标签:
#include "stdafx.h"
#include <iostream>
#include "opencv2/core/core.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
using namespace std;
using namespace cv;
#define DIM 512
struct cuComplex
{
float r;
float i;
cuComplex(float a,float b):r(a),i(b){}
float magnitude2(void){return r*r+i*i;}
cuComplex operator*(const cuComplex& a)
{
return cuComplex(r*a.r-i*a.i,i*a.r+r*a.i);
}
cuComplex operator+(const cuComplex& a)
{
return cuComplex(r+a.r,i+a.i);
}
};
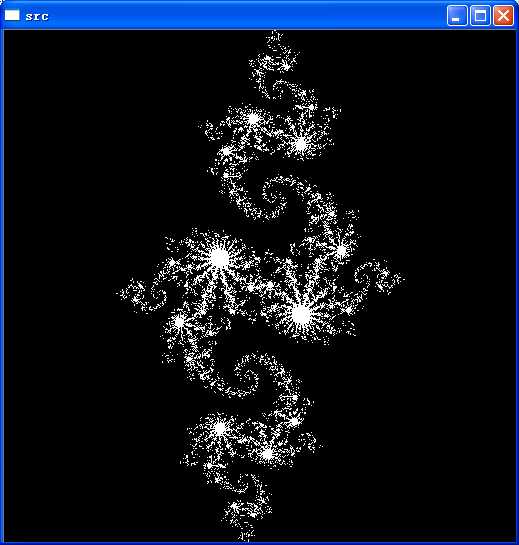
int julia(int x,int y)
{
const float scale = 1.5;
float jx = scale*(float)(DIM/2 - x)/(DIM/2);
float jy = scale*(float)(DIM/2 - y)/(DIM/2);
cuComplex c(-0.8,0.156);
cuComplex a(jx,jy);
for (int i=0;i<200;i++)
{
a=a*a +c;
if (a.magnitude2()>1000)
{
return 0;
}
}
return 1;
}
int _tmain(int argc, _TCHAR* argv[])
{
Mat src = Mat(DIM,DIM,CV_8UC3);//创建画布
for (int x=0;x<src.rows;x++)
{
for (int y=0;y<src.cols;y++)
{
for (int c=0;c<3;c++)
{
src.at<Vec3b>(x,y)[c]=julia(x,y)*255;
}
}
}
imshow("src",src);
waitKey();
return 0;
}
//1)CUDA和OPENCV联系起来;(test1.cu)
#include "stdafx.h"
#include <iostream>
#include "opencv2/core/core.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include <stdio.h>
#include <assert.h>
#include <cuda_runtime.h>
#include <helper_functions.h>
#include <helper_cuda.h>
using namespace std;
using namespace cv;
#define N 250
//test1的kernel
__global__ void test1kernel(int *t)
{
int x = blockIdx.x;
int y = blockIdx.y;
int offset = x+y*gridDim.x;
t[offset] =255-t[offset];
}
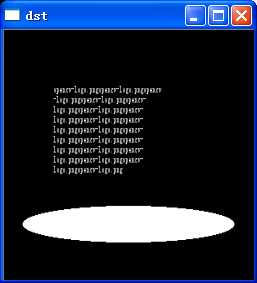
int main(void)
{
//step0.数据和内存初始化
Mat src = imread("opencv-logo.png",0);
resize(src,src,Size(N,N));
int *dev_t;
int t[N*N];
Mat dst = Mat(N,N,CV_8UC3);
for (int i=0;i<N*N;i++)
{
t[i] =(int)src.at<char>(i/N,i%N);
}
checkCudaErrors(cudaMalloc((void **)&dev_t, sizeof(int)*N*N));
//step1.由cpu向gpu中导入数据
checkCudaErrors(cudaMemcpy(dev_t, t,sizeof(int)*N*N, cudaMemcpyHostToDevice));
//step2.gpu运算
dim3 grid(N,N);
test1kernel<<<grid,1>>>(dev_t);
//step3.由gpu向cpu中传输数据
checkCudaErrors(cudaMemcpy(t, dev_t,sizeof(int)*N*N, cudaMemcpyDeviceToHost));
//step4.显示结果
for (int i=0;i<N;i++)
{
for (int j=0;j<N;j++)
{
int offset = i*N+j;
for (int c=0;c<3;c++)
{
dst.at<Vec3b>(i,j)[c] =t[offset];
}
}
}
//step5,释放资源
checkCudaErrors(cudaFree(dev_t));
imshow("dst",dst);
waitKey();
return 0;
}

//3)julia
#include "stdafx.h"
#include <iostream>
#include "opencv2/core/core.hpp"
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/imgproc/imgproc.hpp"
#include <stdio.h>
#include <assert.h>
#include <cuda_runtime.h>
#include <helper_functions.h>
#include <helper_cuda.h>
using namespace std;
using namespace cv;
#define N 250
struct cuComplex
{
float r;
float i;
__device__ cuComplex(float a,float b): r(a),i(b){}
__device__ float magnitude2(void)
{
return r*r+i*i;
}
__device__ cuComplex operator*(const cuComplex& a)
{
return cuComplex(r*a.r - i*a.i,i*a.r + r*a.i);
}
__device__ cuComplex operator+(const cuComplex& a)
{
return cuComplex(r+a.r,i+a.i);
}
};
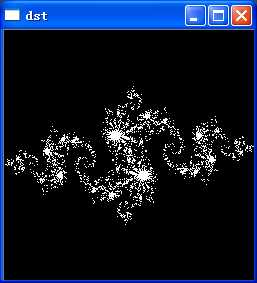
__device__ int julia(int x,int y)
{
const float scale = 1.5;
float jx = scale*(float)(N/2 - x)/(N/2);
float jy = scale*(float)(N/2 - y)/(N/2);
cuComplex c(-0.8,0.156);
cuComplex a(jx,jy);
for (int i=0;i<200;i++)
{
a=a*a +c;
if (a.magnitude2()>1000)
{
return 0;
}
}
return 1;
}
__device__ int fblx(int offset)
{
if (offset ==0 || offset==1)
{
return offset;
}
else
{
return(fblx(offset - 1)+fblx(offset - 2));
}
}
//test3的kernel
__global__ void juliakernel(int *t)
{
int x = blockIdx.x;
int y = blockIdx.y;
int offset = x+y*gridDim.x;
int juliaValue = julia(x,y);
t[offset] =juliaValue*255;
}
int main(void)
{
//step0.数据和内存初始化
int *dev_t;
int t[N*N];
Mat dst = Mat(N,N,CV_8UC3);
for (int i=0;i<N*N;i++)
{
t[i] =0;
}
checkCudaErrors(cudaMalloc((void **)&dev_t, sizeof(int)*N*N));
//step1.由cpu向gpu中导入数据
checkCudaErrors(cudaMemcpy(dev_t, t,sizeof(int)*N*N, cudaMemcpyHostToDevice));
//step2.gpu运算
dim3 grid(N,N);
juliakernel<<<grid,1>>>(dev_t);
//step3.由gpu向cpu中传输数据
checkCudaErrors(cudaMemcpy(t, dev_t,sizeof(int)*N*N, cudaMemcpyDeviceToHost));
//step4.显示结果
for (int i=0;i<N;i++)
{
for (int j=0;j<N;j++)
{
int offset = i*N+j;
printf("%d is %d",offset,t[offset]);
for (int c=0;c<3;c++)
{
dst.at<Vec3b>(i,j)[c] =t[offset];
}
}
}
//step5,释放资源
checkCudaErrors(cudaFree(dev_t));
imshow("dst",dst);
waitKey();
return 0;
}标签:
原文地址:http://www.cnblogs.com/jsxyhelu/p/4491876.html