标签:
hadoop启动jobhistoryserver来实现web查看作业的历史运行情况,由于在启动hdfs和Yarn进程之后,jobhistoryserver进程并没有启动,需要手动启动,启动的方法是通过:
mr-jobhistory-daemon.sh start historyserver 命令还启动。
由于前面有过一篇通过web查看job的运行情况的文章(文章的出处:http://www.cnblogs.com/ljy2013/p/4485949.html),文中介绍的是当作业在运行时,如何通过web查看job的运行情况,当job运行完之后,就无法查看,这是由于集群的historyserver 进程没有启动。因此需要手动启动。
我在启动的时候出现错误:
mnvaild maxumum heap size :-Xmx1000
ERROR:could not create the java Virtual Machine 如下图所示:

通过查看执行的脚本mr-jobhistory-daemon.sh的内容,发现脚本文件中的内容并未涉及到maxumum heap size的问题,于是可能是脚本文件中调用的其他文件所导致的,如下图所示:
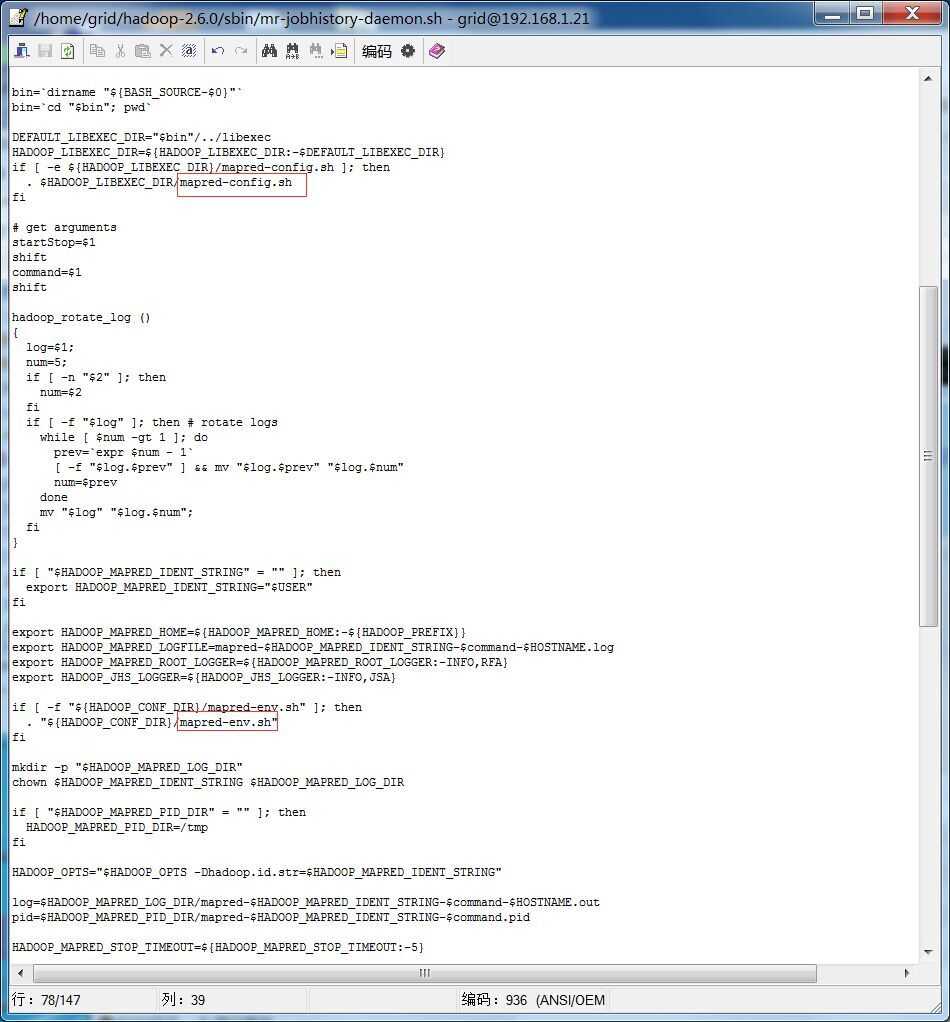
由于mapred-config.sh 脚本文件并未发现,因此只有mapred-env.sh 脚本文件中出现的问题。于是查看mapred-env.sh 脚本文件,如下图所示:
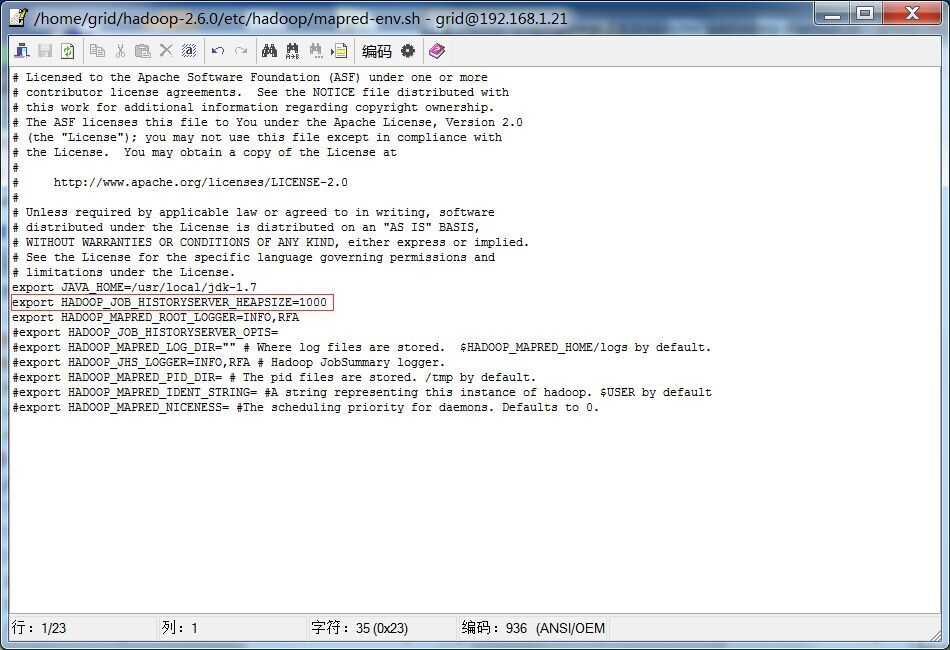
该文该中队jobhistoryserver的堆栈大小进行了设置,
标签:
原文地址:http://www.cnblogs.com/ljy2013/p/4501162.html