标签:
关于Solr搜索标点与符号的中文分词你必须知道的(mmseg源码改造)
摘要:在中文搜索中的标点、符号往往也是有语义的,比如我们要搜索“C++”或是“C#”,我们不希望搜索出来的全是“C”吧?那样对程序员来说是个噩梦。然而在中文分词工具mmseg中,它的中文分词是将标点与符号均去除的,它认为对于中文来讲标点符号无意义,这明显不能满足我们的需求。那么怎样改造它让它符合我们的要求呢?本文就是针对这一问题的详细解决办法,我们改mmseg的源代码。
关键字:Solr, mmseg, 中文, 分词, 标点, 符号, 语义
前提:Solr(5.0.0版本),mmseg4j(1.10.0版本)
作者:王安琪(博客地址:http://www.cnblogs.com/wgp13x/)
0、Solr的mmseg默认中文分词效果
做个实验,入Solr的语句为:t#\"\&\*CTY C# "#"&*^#とう華??? #\"\&\*C8:8。3 C# \"#\"&*^#√とう ,使用的是mmseg中的“max-word”型分词。分词后会变成什么样呢?在对Solr进行简单的mmseg配置操作后,我们在Solr的Analysis中对以上语句进行分析,如下图所示。

图0-1 mmseg默认中文分词效果
从上图中可以看出,默认的mmseg“max-word”型分词将所有的标点、符号都抛弃掉了,余下的只是中文、数字、英文、韩文、日文等。经过mmseg的其他类型如:“complex”和“simple”分析操作后,其结果也是把所有的标点、符号均删除。然而使用Ansj进行中文分词的话,其默认是不删除标点符号的。使用IKAanalyzer来进行中文分词,它也删除掉所有的标点符号。具体情况见博客:中文分词器性能比较 http://www.cnblogs.com/wgp13x/p/3748764.html。
mmseg在中文分词过程中删除标点符号,这直接导致搜索不出标点和符号,因为被删除的将不被建立索引,如:搜索“#”,返回的是所有。为了解释这个问题,我们分析一下Solr创建索引的过程。
1、Solr创建索引的过程
在创建索引的过程中,进入的每一句字符串,均依据fieldType中配置的:tokenizer及以下的filter,从上至下依次处理。正如下图所示的,当进入的字符串为 #Yummm :) Drinking a latte at ... 第一步经过StandardTokenizer后,变成了一个个单词:Yummm | Drinking | a | latte | at | ,可以看出这一步就已经将标点符号去除掉了,并使用标点符号和空格将句子划分成一个个单词。第二步经过的是StopFilter,它将stop words:a at in 等删掉,它认为他们是无语义的词汇,这要看具体情况了,这步结束后原文变成了:Yummm | Drinking | latte | 。第三步是经过LowercaseFilter,很明显从字面上解释就是把所有的单词小写化,最终的结果是:yummm | drinking | latte |。
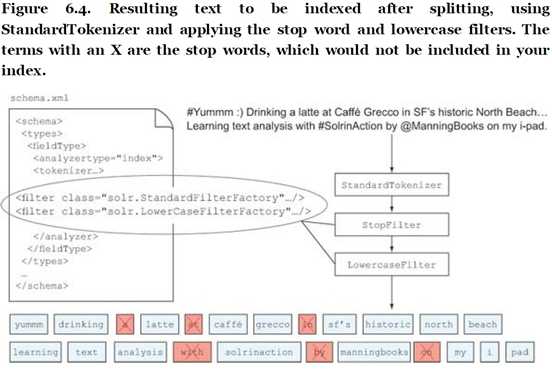 图1-1 Solr创建索引的过程
图1-1 Solr创建索引的过程
在搜索的过程中,新入的搜索字符串,也需要经历这几个过程,再将经历这些过程后的单词以“与”或“或”的关系,进行搜索。这就解释了,上一个问题,为什么输入的搜索条件是“#”,返回的是所有,因为条件经历这些过程后,条件是空,即搜索所有了。
2、Solr的mmseg经过改进后的中文分词效果
经过我们的改进,在入Solr的语句为:!,工;1 - 低 ... 时, 中文分词效果如下图所示。
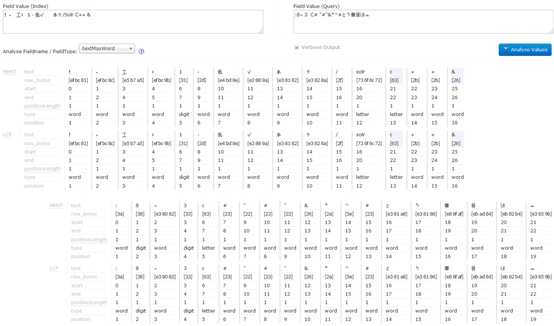
图2-1 mmseg经过改进后的中文分词效果
从上图可以看到,经过MMST后,所有的单词都已经大写小化了,所以可以去除LowerCaseFilter,对结果不影响,即在配置中将<filter class="solr.LowerCaseFilterFactory"/>去掉。再次分析的效果如下图所示:

图2-2 mmseg经过改进后并去除LowerCaseFilter后的中文分词效果
可以看出,C++这样输入的输出变成了:c | + | +,这样的话,当搜索条件为入C++时,便可以匹配出来了!这正是我们想要的。最终效果可以从下图中看出,在图2-3中将一串带有标点符号的字符串添加入Solr的mmseg fild中。在图2-4中对mmseg fild搜索带有标点符号的字符串,可以看到,刚添加的字符串被正确搜索到了!
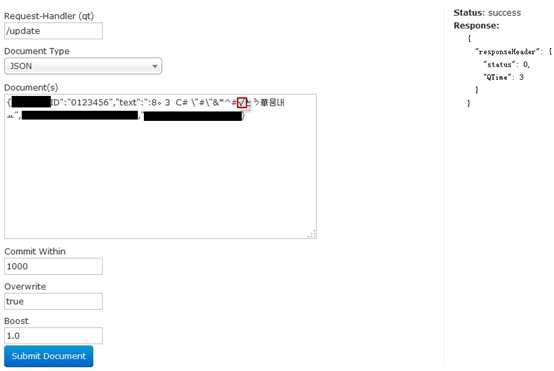 图2-3 添加带有标点符号的Document
图2-3 添加带有标点符号的Document
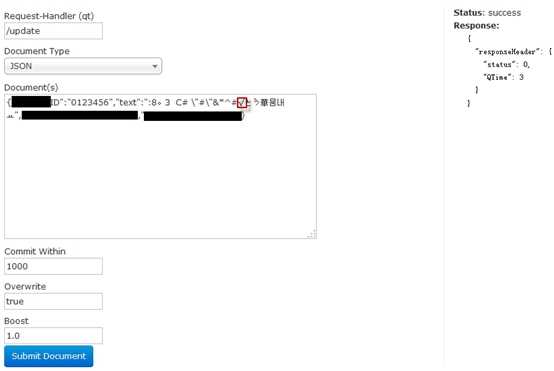
图2-4 搜索条件带有标点符号的搜索结果
3、Solr的mmseg的中文分词效果改进办法
首先,根据mmseg作者chenlb的提示与启发,可以在next()函数中进行修改源码,以达到不去除标点符号的目的。我们在mmseg源码中找到MMSeg类中存在next()函数,通过阅读源码,我们知道,这即是对已识别的各种类型的字符进行分门别类地处理,如数字、字母、韩语等。函数内对其他的字符均视为无效字符,其中标点与符号便落入了此类别,其对此类别的字符处理办法是:“不理睬”。下面就是我依照中文字符的处理过程,编写了标点与符号的处理过程,同时对空格及Tab、\n这些字符采取“不理睬”策略,因为他们真的是无语义的,具体的代码如下。
|
public Word next() throws IOException { // 先从缓存中取 Word word = bufWord.poll(); ; if (word == null) { bufSentence.setLength(0); int data = -1; boolean read = true; while (read && (data = readNext()) != -1) { read = false; // 默认一次可以读出同一类字符,就可以分词内容 int type = Character.getType(data); String wordType = Word.TYPE_WORD; case Character.SPACE_SEPARATOR: case Character.CONTROL: read = true; break; default: // 其它认为无效字符 // read = true; bufSentence.appendCodePoint(data); readChars(bufSentence, new ReadCharByType(type)); // bufWord.add(createWord(bufSentence, Word.TYPE_LETTER)); currentSentence = createSentence(bufSentence); bufSentence.setLength(0); }// switch // 中文分词 if (currentSentence != null) { do { Chunk chunk = seg.seg(currentSentence); for (int i = 0; i < chunk.getCount(); i++) { bufWord.add(chunk.getWords()[i]); } } while (!currentSentence.isFinish()); currentSentence = null; } word = bufWord.poll(); } return word; } |
经过编译后,将MMSeg类相关的class替换到mmseg4j-core-1.10.0.jar目录下,如图3-1所示。然后重新部署Solr,一切运行正常!
图3-1 编译并替换MMSeg
4、Solr的配置补充
经过刚才的操作,已经解决了标点与符号删除的问题。下面讲一下autoGeneratePhraseQueries的配置。
![]()
图4-1 mmSeg配置
如上图的配置所示,autoGeneratePhraseQueries="false",autoGeneratePhraseQueries配置为false有下面的作用:将搜索关键词分词后,以或的条件进行搜索,比如入的是 ![]() ,搜索关键词是
,搜索关键词是![]() ,关键词经过分词后有些分词结果不在Doc范围内,但是仍旧可以搜索出来;然而如果autoGeneratePhraseQueries="true" ,则搜索不出来,此时是且的关系。
,关键词经过分词后有些分词结果不在Doc范围内,但是仍旧可以搜索出来;然而如果autoGeneratePhraseQueries="true" ,则搜索不出来,此时是且的关系。
这简直是太棒了!
关于Solr搜索标点与符号的中文分词你必须知道的(mmseg源码改造)
标签:
原文地址:http://www.cnblogs.com/wgp13x/p/4502178.html