标签:
RPC(Remote Procedure Call,远程过程调用)框架是分布式服务的基石,实现RPC框架需要考虑方方面面。其对业务隐藏了底层通信过程(TCP/UDP、打包/解包、序列化/反序列化),使上层专注于功能实现;框架层面,提供各类可选架构(多进程/多线程/协程);应对设备故障(高负载/死机)、网络故障(拥塞/网络分化),提供相应容灾措施。
监控是分布式服务中相当重要的一部分,其有助于我们了解业务发展状况,出灾时提供第一手分析资讯。分布式系统中的每一个模块,都需要一些指标说明其服务状况和服务质量,如调用总数、成功数、连接失败数、调用平均耗时等,这些指标应该由RPC框架默认提供;对于业务相关的指标,例如查看附近的人的总人数、查看附近的人的男/女人数、扔漂流瓶的总人数等,RPC框架也应该提供接口,方便业务开发同学添加相关监控项。
下面我们就来了解实现RPC框架监控的一种方案。
id-key监控
首先我们来看如何对模块监控,这里模块由一组提供相同服务的设备组成,一个模块对外提供统一的服务端口。
那么对一个模块默认应该具备哪些监控项呢?除了以上提到的调用总数、调用成功数、连接失败数、调用平均耗时外,还可以具备以下监控项:
以上监控项中,既有Client端的上报数据,也有Server端自己的上报数据,通过服务提供方和服务使用方两方面监控,确保监控数据的全面和准确。根据RPC框架的具体实现,Server各阶段处理统计可以有不同的细分统计(例如从Accept Queue接收到fd到将请求包push到Inqueue的耗时统计),帮助我们从更细的角度观察RPC框架内部。
有了监控的对象和目标,接着就是如何实现。从一个模块对外提供一个服务端口这一点出发,可以实现基于id-key的分钟级监控。id-key是存在于共享内存中的一个二维数组,具体表示如下:
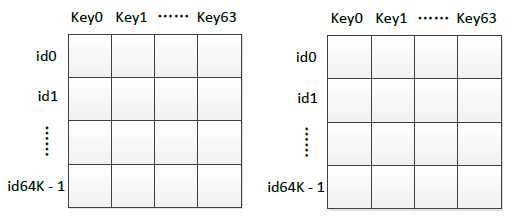
id和key均为unsigned int类型,id的取值范围为 0 ~ 64K-1,key的取值范围为 0 ~ 63。两块共享内存,一块用于读,一块用于写,每分钟切换这两块内存。这两块共享内存一共占用的内存大小为:64K * 64 * 4(bytes) * 2 = 32M。
模块的端口可以映射为一个id,key对应于以上一个个监控项,在RPC框架层修改相关监控项(例如Client进行connect调用失败时,对相应Server连接失败的id-key加1)。通过每分钟切换读写共享内存块,我们得到每分钟某个模块单机的统计数据,我们可以将这些数据进行入库。
但单机的纬度还不够,我们经常需要了解一个模块整体的服务情况,于是我们对每分钟数据进行收集、聚合:
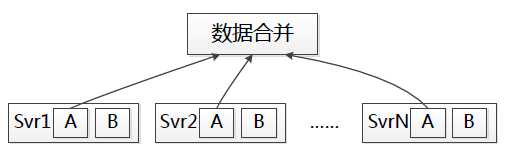
以分钟为单元,将该模块各台设备不同id-key的数据进行求和,我们就得到了该模块各指标整体的分钟级数据。RPC框架内置进程将统计数据写入共享内存,从共享内存获取数据并上传进行合并可由另外的进程完成。
对于业务相关的数据,也可以通过id-key的方法实现监控,对某项业务我们可以申请id(注意避免与模块的id冲突),自定义各项key的含义,然后在业务代码中将相关指标上报到对应id-key。
调用关系
分布式系统中,我们经常需要看一个模块的上下游关系,类似以下展现形式:
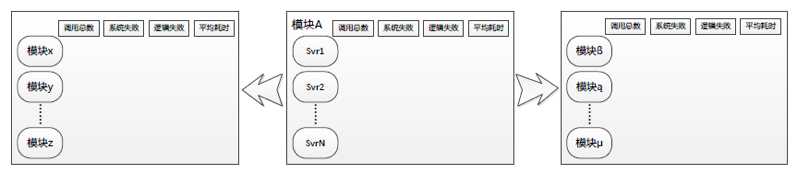
以模块A为查询对象,对应的可以找到其主调模块x/y/z、被调模块ß/?/μ等模块,同时显示调用总数、系统失败数等主被调的服务情况。
我们在框架中也可以实现调用关系数据的收集,每次RPC调用,以主调(SvrID,ModID)为key,被调(SvrID,ModID)为value入主调数据库,另以被调(SvrID,ModID)为key,主调(SvrID,ModID)为value入被调数据库。查看模块A上游时查询被调数据库,查看模块A下游时查询主调数据库。
调用关系方便我们检查RPC框架中,一条链的调用情况,在更大的层面我们有时候希望看到调用网的情况,在一个更大维度观察系统,出灾时可以更直观地看到异常模块。关于分布式系统调用网监控,可以参考Google Dapper这篇文章。
小结
本文介绍了RPC框架中实现监控的id-key方案,id-key通过数据收集与聚合,在框架层默认为各个模块提供调用总数、调用平均耗时等指标,同时可方便添加各种业务数据关联的统计指标。分布式系统中,对某个业务定位分析问题时,经常需要查看该业务相关的调用链,分析一个模块的主被调情况,这也需要在RPC框架层面提供支持。
标签:
原文地址:http://www.cnblogs.com/bangerlee/p/4504833.html