对推荐系统的建模数据进行分析,代表型数据:1)无上下文的隐形反馈数据;2) 无上下文的显性反馈数据;3) 有上下文的隐形反馈数据;4)有小上下文的显性反馈数据,其中显性的反馈数据就是用户对物品的评分,而隐形的就是用户对物品的浏览,时长等数据(不同的领域,用户对物品的行为种类不一样),像我之前的做的都全是用有上下文的隐形反馈,都是通过点击、登陆、时长归纳出来的用户对物品的评分。
有了用户数据以后,可以做一些行为的分析:1) 用户活跃度和物品流行度的分布(用户浏览过多少物品和物品被多少用户浏览过,符合长尾分布?);2) 用户活跃度跟物品流行度的关系(是不是新用户趋近于接触热门物品?);3) 用户的平均评分和物品的平均评分(流行度中等的物品的平均评分,可能平均分很高)
有了上面的数据跟分析之后,接下来就开始运用算法来建模了,常用的有基于领域的算法,基于隐语义模型,基于图模型等。
基于领域的算法通常又分基于用户的和基于物品的CF,前一种算法的步骤
(1)找到和目标用户兴趣相似的用户集合;(2) 找到这个集合的用户喜欢听的,而且目标用户没有听过的物品
后一种算法的步骤:(1)计算物品与物品之间的相似度;(2) 通过目标用户已经正反馈的物品,来找到相似度其它物品。
上面2种算法的关键是找到用户/物品相似度集合,这里的用户/物品的相似度计算,不是用用户/物品的内在属性来衡量的(比如A物品是青苹果,B物品是红苹果,C物品是香蕉,用协同过滤的思想来计算的话,A跟B就不一定相似哦),直观上来讲 就是 如果A用户跟B用户 的物品重合性高,那么A跟B就相似,类似如果A物品跟B物品的共同用户重合性高,那么A跟B相似。
计算相似度的公式有很多种,余弦、皮尔逊、欧氏距离等。关于详细的公式请参考谷歌度娘。
实际应用需要注意的一些点:
1)余弦跟欧氏距离区别:我的感觉这两种方式,一个是定性,一个是定量,比如A用户对2个物品的评分是3,3,而B用户对这两个物品的评分是5,5,如果按余弦计算A,B就是相似的,而欧氏距离认为这两个用户还是有差异的;
2)通过余弦计算的时候,通常会做一个预处理,评分的用户会预先把每个物品的评分减去该用户的平均分 或者 加一个惩罚项(按物品的流行度/用户的活跃度)。计算用户跟用户相似度时 惩罚那些物品流行度高的,换句话说 2个用户对偏重冷门物品的有相同行为比对热门的有相同行为的更相似
3)对某用户活跃度太高的人,应该去除该用户
4) 相似度的归一化,提高推荐的多样性
user-cf的参数K值影响,K越大,结果越全局热门,覆盖面越小,流行度越大,通常运营与新闻类网站。
另外需要关注的就是哈利波特问题,就是某个物品太热了,而导致好多物品都会跟热门物品关联
最后,经常会问到的问题是:协同过滤跟关联规则有什么区别?
1. 关联规则面向的是transaction,而协同过滤面向的是用户偏好(评分)。
2. 协同过滤在计算相似商品的过程中可以使用关联规则分析,但是在有用户评分的情况下(非1/0),协同过滤算法应该比传统的关联规则更能产生精准的推荐。
3. 协同过滤的约束条件没有关联规则强,或者说更为灵活,可以考虑更多的商业实施运算和特殊的商业规则。
基于隐语义模型是近几年来研究比较火热的领域,特别是学术界,因为可以玩数学公式,出学术论文等。该模型的核心思想是通过隐变量(特征)来联系用户的兴趣跟物品。比较著名的方法有:PLSA,LDA,MF,LFM等,关于这些模型的目标损失函数,优化算法等请参考相应论文/技术博客
由于数据集里面的都是用户有正反馈行为的物品,那么如何采集用户的负样本呢?1) 对于每个用户,保证正负样本均衡;2) 采样负样本时,对更热门的负样本 加大采样权重。
案例:雅虎的新闻推荐,新闻在很短的时间内获得大量关注或是去关注,特别是刚出的新闻。这对于单纯的LFM很难实时推荐,因为需要在用户行为记录上反复迭代才能获取较好的性能。一个替代的方案是:预先利用新闻链接的内容属性(关键字、类别等)得到连接的内容特征向量跟用户对内容特征的兴趣程度(历史记录),然后再叠加最近几个小时更新的LFM,拿到用户实时的兴趣。最后通过两步叠加生成最后的实时结果
LMF跟基于领域的方法比较:
1. 理论基础,前者有明确的优化函数,而基于领域的则更多的基于统计的方法,并没有一个学习的过程;
2. 离线计算的空间复杂度:假设M个用户N个物品,对于LMF则需要O(F*(M+N))的空间复杂度,F是隐变量的个数,对于user-cf需要O(M*M)记录用户相关表,而item-cf要O(N*N)记录物品相关表
3. 离线计算的时间复杂度:假设M个用户N个物品K条用户对物品的行为记录,对于LMF则需要O(F*K*S)的空间复杂度,F是隐变量的个数,S是迭代次数,对于user-cf需要O(M*(K/M)^2)时间复杂度,而item-cf要O(M*(K/M)^2) 时间复杂度
4. 推荐解释,item-cf能给出很好的解释,而LFM则无法给出具体业务上的解释
基于图模型的推荐,由于用户物品的行为都可以转化为二分图的表示,那么就可以根据历史数据构建出这种形式,然后度量两个顶点之间的相似度的问题。基于这个思想的著名算法包括随机游走和PersonalRank算法。适合社交关系较强的数据应用上。
冷启动问题
常见的冷启动问题包括三类:1)用户冷启动(新用户没有历史行为,该怎么推荐?);2)物品冷启动(新物品,该如何向对齐感兴趣的用户推荐? item-cf受影响);3)系统冷启动(新开发的网站,没用户,只有一些物品信息,如何在网站发布的时候让访问的用户感受个性化推荐?)
对于上述的几个问题,可以参考几个常见的解决方案
1. 对于新用户可以先进行热门推荐或热门物品的随机推荐,对于新物品可以考虑基于内容的推荐思想计算与其它物品的相似度;
2. 利用用户注册信息,如年龄,性别,地区等(结合简单分析物品的用户年龄、性别、地区的分布,建立相关表),或者一开始让用户选一些自己感兴趣的tag,这样就可以进行粗粒度的个性化;
3. 利用授权登陆获取到社交或其他信息,如淘宝跟新浪微博的相互打通;
4. 系统冷启动时,可以引入专家(小编或运营人员等)建立起物品的相似表;
通常基于内容推荐通常是作为一个baseline,但是并不表示内容推荐就一定比基于领域的算法效果差,推荐系统实践一书举了个例子:如github的内容推荐就会相对比CF的要略好一点,因为用户的行为强烈的受到物品的某一属性影响,github浏览用户会受开源项目的作者影响,会关注这些知名作者的其他开源项目。
基于标签tag的推荐====>最基本的统计用户常用的tag,然后统计被tag次数最多的哪些物品,最后找那些很热且含有用户常用tag的物品进行推荐
上面的问题:会给热门标签对于的热门物品很大的权重(用户常用的标签的热门物品),因此会造成推荐热门物品,降低新颖性。
改进1:类似的解决方法就是上面基于领域模型的惩罚热门标签(具体做法就是借鉴tf-idf思想记录常用标签被多少个其他用户使用过)跟热门物品
改进2:数据稀疏性的问题(再别的模型一样都会遇到的问题),把相似的tag聚类,例如某用户的tag是”推荐系统“,那么“个性化推荐”“协同过滤”tag应该也是用户会感兴趣的tag。放在别的算法可能就是对物品进行LDA聚类,抽象出来一类物品,稠密化数据。
上面讲的推荐模型里面的数据都是最基本的例如用户,物品,评分/tag,光有这些数据能产生推荐,但是推荐结果的质量就不一定了,有些时候从业务上看会很离谱(例如假设通过协同过滤算法得到一件外套跟t恤很相似,但是在夏天的时候,某一个用户买过T恤,难道要他推荐外套??)。所以除了上面讲的最基本的数据外,可以利用一些其他的信息来帮助改进推荐结果。这里统称为上下文信息(如时间,地点,情感心情等)
基于时间上下文的user-cf算法:算法的场景,例如A用户1个月前喜欢苹果,2个月前喜欢香蕉,B用户1个月前喜欢苹果,3个月前喜欢香蕉,而C用户跟A用户一样,1个月前喜欢苹果,2个月前喜欢香蕉,如果不加时间上下文关系,A、B、C用户的兴趣是相等的,但是加入时间上下文,那么A跟C 就会 比 B跟C 更相似;同理基于时间上下文的item-cf算法,也是采用了类似原理场景。实际操作的时候就是,对相似度计算公式的分子上面加一个兴趣相似的时间衰减函数,突出最近行为。
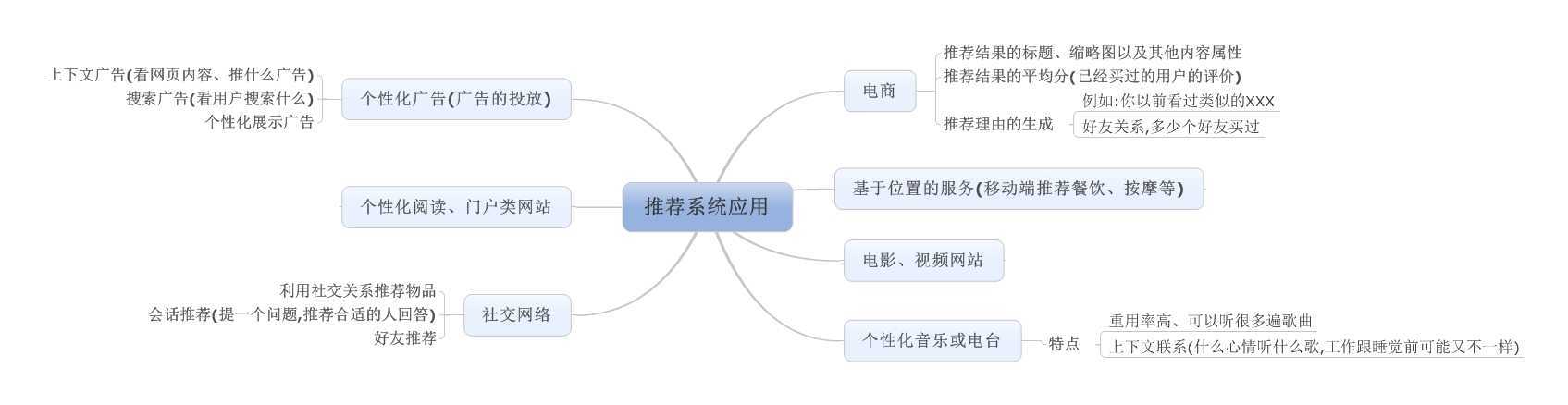
基于位置的推荐:给你推荐附近的酒店、餐馆等,移动时代这个显得更为重要,前段时间,百度公司出的春运,百度迁徙,火了互联网,就是因为掌握了用户的地理信息。再比如一个场景,淘宝的给用户推荐宝贝,是不是推荐也可以推荐一些离用户近的那些宝贝?还可以节省点路费,当然还需要其它因为,如成本,宝贝兴趣强弱关系等。
利用社交网络数据,用户社交关系数据对推荐的重要性不言而喻,更甚都可以不用复杂的推荐算法,单纯看社交关系进行推荐。如最近火的不行的”天天系列“,腾讯下面的游戏,基于微信平台,利用社交关系把用户粘的紧紧的,天然的满足用户的需求,即时不是玩游戏的用户。
社交数据的来源:电邮、用户注册(某个公司、某个学校、家乡等)、论坛/讨论组、即时聊天软件、社交网站等。
算法方面也是多种多样,基于图的社交挖掘(图是社交关系表达的最好表达方式)、基领域+社交关系的推荐、基于社交关系的矩阵分解等。
参考资料:推荐系统实践-项亮编著