标签:
对于商业
搜索引擎来说,分布式爬虫
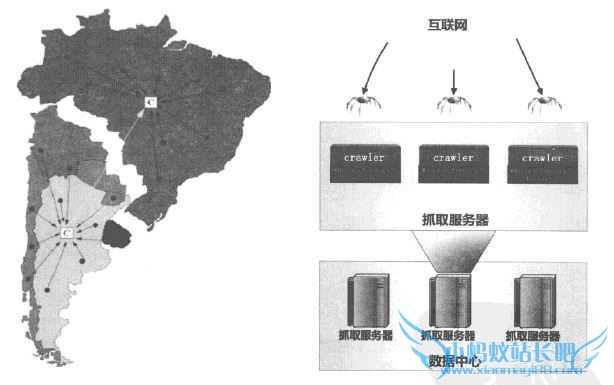
架构是必须采用的技术。面对海量待抓取网页,只有采取分布式架构,才有可能在较短时间内完成一轮抓取工作。 分布式爬虫可以分为若千个分布式层级。不同的应用可能由其中部分层级构成,下图是一个大型分布式爬虫的3个层级:分布式数据中心、分布式抓取服务器及分布式爬虫程序。整个爬虫系统由全球多个分布式数据中心共同构成,每个数据中心负责抓取本地域周边的互联网网页,比如欧洲的数据中心负责抓取英国、法国、德国等欧洲国家的网页,由于爬虫与要抓取的网页地缘较近,在抓取速度上会较远程抓取快很多。
每个数据中心义由多台高速网络连接的抓取服务器构成,而每台服务器又可以部署多个爬虫程序。通过多层级的分布式爬虫体系,才一可能保证抓取数据的及时性和全面性。
对于同一
数据中心的多台抓取服务器,不同机器之间的分工协同方式会有差异,常见的分布式架构有两种:主从式分布爬虫和对等式分布爬虫。 1、主从式分布爬虫(Master-Slave)
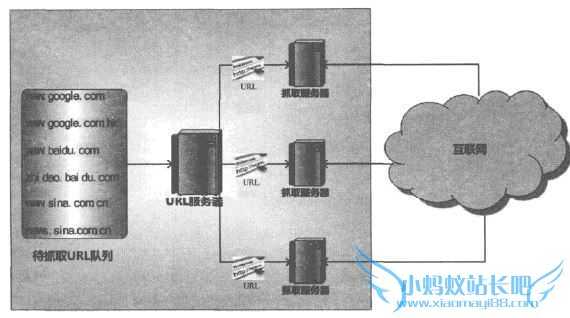
对于主从式分布爬虫,不同的服务器承担不同的角色分工,其中有一台专门负责对其他服务器提供URL分发服务,其他机器则进行实际的网贞F载口URL服务器维护待抓取URL队列,并从中获得待抓取网页的URL,分配给不同的抓取服务器,另外还要对抓取服务器之间的工作进行
负载均衡,使得各个服务器承担的工作量大致相等,不至于出现忙的过忙、闲的过闲的情形。抓取服务器之间没有通信联系,每个抓取服务器只和URL服务器进行消息传递。 Google在早期即采用此种卞从
分布式爬虫,在这种架构中,因为URL服务器承担很多管理任务,同时待抓取URL队列数量巨大,所以URL服务器容易成为整个系统的瓶颈。 2、对等式分布爬虫(Peer to Peer)
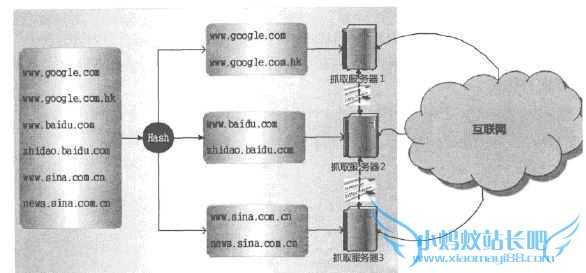
在对等式分布爬虫体系中,服务器之间不存在分工差异,每台服务器承担相同的功能,各自负担一部分URL的抓取工作,如图所示即是其中一种对等式分布爬虫,Mercator爬虫采用此种体系结构。
由于没有URL服务器存在,每台抓取服务器的任务分工就成为问题。在如图所示体系结构下,由服务器自己来判断某个URL是否应该由自己来抓取,或者将这个URL传递给相应的服务器。至于采取的判断方法,则是对网址的主域名进行哈希计算,之后取模(即hash域名」%m,这里的m对应服务器个数),如果计算所得的值和抓取服务器编号匹配,则自己下载该网页,否则将该网址转发给对应编号的抓取服务器。
以图中的例子来说,因为有3台抓取服务器,所以取模的时候m设定为3。图中的1号抓取服务器负责抓取哈希取模后值为1的网页,当其接收到网址www.google.com时,首先用哈希函数计算这个主域名的哈希值,之后对3取模,发现取模后值为1,属于自己的职责范围,于是就自己下载网页;如果接收到网址www.baidu.com,哈希后对3取模,发现其值等于2,不属于自己的职责范畴,则会将这个要下载的URL转发给2号抓取服务器,由2号抓取服务器来进行下载。通过这种方式,每台服务器平均承担大约1/3的抓取工作量。
由于没有URL分发服务器,所以此种方法不存在系统瓶颈问题,另外其哈希函数不是针对整个URL,而只针对主
域名,所以可以保证同一网站的网页都由同一台服务器抓取,这样一方面可以提高下载效率(DNS域名解析可以缓存),另外一方面也可以主动控制对某个网站的访问速度,避免对某个网站访问压力过大。 图中这种体系结构也存在一些缺点,假设在抓取过程中某台服务器宕机,或者此时新加入一台抓取服务器,因为取模时,是以服务器个数确定的,所以此时m值发生变化,导致大部分URL,哈希取模后的值跟着变化,这意味着儿乎所有任务都需要重新进行分配,无疑会导致资源的极大浪费。
为了解决哈希取模的对等式分布爬虫存在的问题,UbiCrawle:爬虫提出了改进方案,即放弃哈希取模方式,转而采用一致性哈希方法C Consisting Hash )来确定
服务器的任务分工,如下图所示:
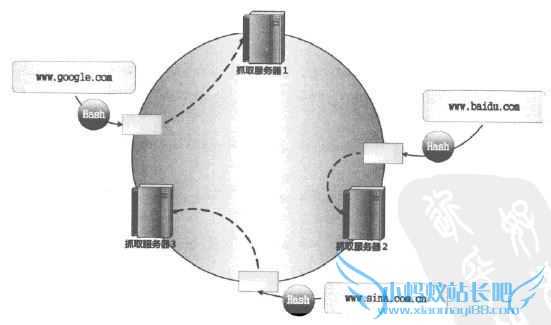
一致性哈希将网站的主域名进行哈希,映射为一个范围在O到2的32次方之问的某个数值,大量的网站主域名会被均匀地哈希到这个数位区间。可以像图中所示那样,将哈希值范围首尾相接,即认为数值0和最大值重合,这样可以将其看做有序的环状序列,从数值O开始,沿着环的顺时针方向,哈希值逐渐增大,自到环的结尾。而某个抓取服务器则负责这个环状序列的一个片段,即落在某个哈希取位范阔内的URL都由该服务器负责下载。这样即可确定每台服务器的职责范。
我们以图为例说明其优势,假设2号抓取服务器接收到了
域名www.baidu.cam,经过哈希值计算后,2号服务器知道在自己的管辖范围内,于是自己下载这个URL。在此之后,2号服务器收到了www.sina.com.cn这个域名,经过哈希计算,可知是3号服务器负责的范围,于是将这个URL转发给3号服务器。如果3号服务器死机,那么2号服务器得不到回应,于是知道3号服务器出了状况,此时顺时针按照环的大小顺序查找,将URL转发给第一个碰到的服务器,即1号服务器,此后3号服务器的下载任务都由l号服务器接管,直到3号服务器重新启动为止。
从上面的流程可知,即使某台
服务器出了问题,那么本来应该由这台服务器负责的URL则由顺时针的下个服务器接管,并不会对其他服务器的任务造成影响,这样就解决了哈希取模方式的弊端,将影响范围从全局限制到了局部,如果新加入一台下载服务器也是如此。http://www.xiaomayi88.com/seoenginer/32500_2.html
搜索引擎分布式爬虫介绍
标签:
原文地址:http://www.cnblogs.com/chenying99/p/4507182.html