首页
Web开发
Windows程序
编程语言
数据库
移动开发
系统相关
微信
其他好文
会员
首页
>
其他好文
> 详细
推荐系统协同过滤基于的两种假设
时间:
2015-05-16 20:01:49
阅读:
193
评论:
0
收藏:
0
[点我收藏+]
标签:
基于用户的协同过滤,基于的假设是:喜欢相同物品的用户具有相似性。
相同物品越多,用户相似性越大。(有点基于统计的意思)
基于用户的协同过滤推荐机制和基于人口统计学的推荐机制都是计算用户的相似度,并基于“邻居”用户群计算推荐,但它们所不同的是如何计算用户的相似度,基于人口统计学的机制只考虑用户本身的特征,而基于用户的协同过滤机制可是在用户的历史偏好的数据上计算用户的相似度,它的基本假设是,喜欢类似物品的用户可能有相同或者相似的口味和偏好。
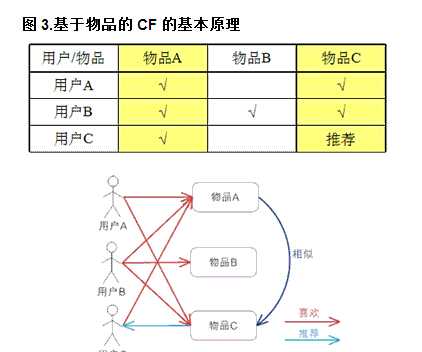
基于项目的协同过滤,基于的假设是
:同一个人喜欢的几个物品具有相似性。
userA喜欢A C
userB喜欢A C
》》则A C具有相似性,同时喜欢的用户越多,说明A C相似性越大。(有点基于统计的意思)
参考:IBM 深入推荐引擎相关算法 - 协同过滤
http://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/index.html
推荐系统协同过滤基于的两种假设
标签:
原文地址:http://www.cnblogs.com/jxhuang/p/4508358.html
踩
(
0
)
赞
(
0
)
举报
评论
一句话评论(
0
)
登录后才能评论!
分享档案
更多>
2021年07月29日 (22)
2021年07月28日 (40)
2021年07月27日 (32)
2021年07月26日 (79)
2021年07月23日 (29)
2021年07月22日 (30)
2021年07月21日 (42)
2021年07月20日 (16)
2021年07月19日 (90)
2021年07月16日 (35)
周排行
更多
分布式事务
2021-07-29
OpenStack云平台命令行登录账户
2021-07-29
getLastRowNum()与getLastCellNum()/getPhysicalNumberOfRows()与getPhysicalNumberOfCells()
2021-07-29
【K8s概念】CSI 卷克隆
2021-07-29
vue3.0使用ant-design-vue进行按需加载原来这么简单
2021-07-29
stack栈
2021-07-29
抽奖动画 - 大转盘抽奖
2021-07-29
PPT写作技巧
2021-07-29
003-核心技术-IO模型-NIO-基于NIO群聊示例
2021-07-29
Bootstrap组件2
2021-07-29
友情链接
兰亭集智
国之画
百度统计
站长统计
阿里云
chrome插件
新版天听网
关于我们
-
联系我们
-
留言反馈
© 2014
mamicode.com
版权所有 联系我们:gaon5@hotmail.com
迷上了代码!