标签:
全局存储器,即普通的显存,整个网格中的任意线程都能读写全局存储器的任意位置。
存取延时为400-600 clock cycles 非常容易成为性能瓶颈。
访问显存时,读取和存储必须对齐,宽度为4Byte。如果没有正确的对齐,读写将被编译器拆分为多次操作,降低访存性能。
多个half-warp的读写操作如果能够满足合并访问,则多次访存操作会被合并成一次完成。
合并访问的条件,GT200放宽了合并访问的条件。
支持对8 bit、16 bit、32 bit、64 bit数据字的合并访问 相应传输32Byte 64Byte 128Byte,大于128Byte,分两次传输。
在一次合并传输的数据中,不要求线程编号和访问的数据字编号相同。
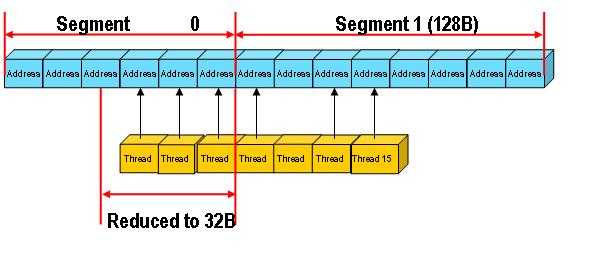
当访问128Byte数据时,如果地址没有对齐到128Byte时,在GT200会产生两次合并访存。根据每个区域的大小,分为两次合并访存,如图所示32Byte和96Byte。
PS:图片来源于网上
关于访存合并以及访存冲突,关键就是要理解,GPU是以half-warp进行访存时,即16个线程一起访问存储器,到这16个线程的访问的地址在同一块区域(指硬件上可以一起传送宽
度)时,并且没有冲突产生时,则这块区域的数据可以被线程同时,提升了访存的效率.
标签:
原文地址:http://www.cnblogs.com/xmphoenix/p/4508476.html