标签:
前面只是获取了单个网页内容,在实际中,则使用爬虫程序遍历互联网,把网络中相关的网页全部抓取过来,这也体现了爬虫程序“爬”的概念。
互联网可以看成一个超级大的“图‘,而每个网页则可以看作是一个”节点“。页面中的链接可以看成是图的”有向边“。因此,可以通过图的遍历的方式对互联网这个”图“进行访问。图的遍历分为宽度优先和深度优先,但深度优先可能会在深度上过于”深”的遍历或者陷入“黑洞”,大多数爬虫都不采用这种方式。此外,在爬取的时候,有时候并不会完全按照宽度优先遍历的方式,而是给待遍历的网页赋予一定的优先级,根据这个优先级进行遍历,这种遍历方式又被称为带偏好的遍历。
有关于图的宽度遍历的知识这里不予详细介绍,主要看一下宽度优先遍历。
实际的爬虫项目是从一系列的种子链接开始的,所谓种子链接就相当于宽度优先遍历中的种子节点,只是实际爬虫项目中种子链接可以有多个,而宽度优先遍历中的种子节点只有一个。
如何定义一个链接的子节点?每个链接对应一个HTML页面或者其他文件(word、excel、pdf等),在这些文件中,只有HTML页面有相应的“子节点”,这些“子节点”就是HTML页面上对应的超链接。这些子节点本身又是一个链接。对于非HTML文档,不能从中提取超链接。因此,可以看作图的“终端”节点。
整个宽度优先爬虫过程就是从一系列的种子节点开始,把这些网页中的“子节点”提取出来,放入队列中以此进行抓取。被处理过的链接需要放入一张表(通常称为Visited表)中,每次处理新链接之前,需要查看这个链接是否已经存在于Visited表中。如果存在,证明链接已经处理过,跳过,不做处理,否则进行下一步处理。整个过程如下图所示:
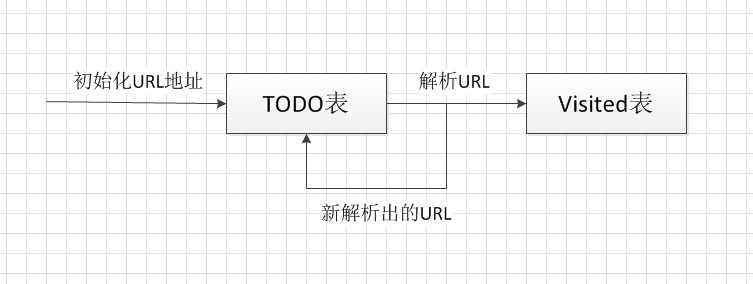
宽度优先遍历是爬虫中使用最广泛的一种爬虫策略,之所以使用宽度优先搜索策略,主要原因有三点:
1)重要的网页往往里种子较近;
2)万维网的实际深度最多能达到17层,但到达某个网页总存在一条很短的路径,而宽度优先遍历会以最快的速度到达这个网页;
3)宽度优先有利于多爬虫的合作抓取,多爬虫合作通常弦抓取站内链接,抓取的封闭性很强。
《自己动手写网络爬虫》读书笔记——宽度优先爬虫和带偏好的爬虫
标签:
原文地址:http://www.cnblogs.com/bianjun/p/4508908.html