标签:
在过去的文章里,我们已经讨论了各种不同索引。这个文章里,我们会讨论下键列的顺序(索引列的顺序)。索引键列的顺序基于数据的访问模式还有你想如何组织数据。
对于索引键列的顺序,常规指导方针就是把查询用到最多的列放在第一列。这并不是说,所有你索引里的唯一ID列就应该是第一列。优化器是基于索引上的可用统计信息来选择索引的。统计信息会给你键列的使用密度信息,即索引的唯一性,直方图(histogram )用来存储那一列值分布情况信息。
让我们用customer表做例子,它保存来自各个国家的客户信息。
1 CREATE TABLE customer ( 2 Customer_id INT IDENTITY(1,1) NOT NULL, 3 CountryCode CHAR(3) NOT NULL, 4 FirstName VARCHAR(100) NOT NULL, 5 LastName VARCHAR(100) NOT NULL, 6 MobilePhone VARCHAR(20), 7 Email VARCHAR(100) 8 ) 9 GO 10 CREATE UNIQUE CLUSTERED INDEX Ix_Customerid_Countrycode ON customer(Customer_id,Countrycode)
聚集索引的创建是基于常规指导方针,我们把经常用到的列放在了左边。如果我基于Customer_id列来获取记录,这个聚集索引非常合适。如果我是基于Countrycode列,优化器就要进行聚集索引扫描了。
1 SET STATISTICS IO ON 2 go 3 SELECT * FROM customer WHERE Countrycode=‘VNH‘ AND customer_id=1216468

我们来找下countrycode 是VHN的所有客户。这个表有近620000条记录,3066条记录的countrycode是VHN。
1 SELECT * FROM customer WHERE Countrycode=‘VNH‘
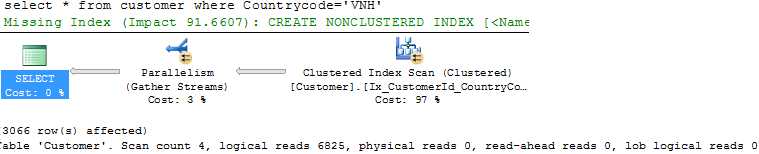
从执行计划可以看到,优化器进行了聚集索引扫描,共扫描了6825页。我们可以修改聚集键的顺序来优化。
1 DROP INDEX customer.Ix_CustomerId_CountryCode 2 GO 3 CREATE UNIQUE CLUSTERED INDEX Ix_CountryCode_CustomerId ON customer(Countrycode,Customer_id) 4 5 SET STATISTICS IO ON 6 go 7 SELECT * FROM customer WHERE Countrycode=‘VNH‘ AND customer_id=1216468

我们来找下countrycode 是VHN的所有客户。
1 SELECT * FROM customer WHERE Countrycode=‘VNH‘

从执行计划可以清楚看到,优化器在这2个情况都使用了索引查找(index seek),但在找countrycode 是VHN的所有客户时,IO操作明显上升。
当保持customer_id为第一列时,数据会按customer_id列的顺序保存,你会有很多页(几乎所有页),里面的数据属于多个countrycode。这个会引起阻塞/死锁。如果我们定义countrycode为第一列,只有少量页,里面的数据与多个countrycode重叠,这样会减少阻塞问题。关键点是:把countrycode定义为索引的第一列会引起更高级别的索引碎片,这可以用定义合适的填充因素值(fill factor value)来控制。
简而言之,键列的常规指导方针是个很好的起点,但是你也要考虑在你程序里的数据访问模式。希望这个可以帮助你解决你遇到的一些问题。
标签:
原文地址:http://www.cnblogs.com/woodytu/p/4510028.html