标签:
数据集介绍:本数据集由Cai-Nicolas Ziegler收集,他对图书漂流社区进行了四周(2014年8月和9月)的数据爬行。该数据集包含278858个用户对271379册图书的1149780个评分。
数据集的网页地址:http://www.datatang.com/data/45481/
由于数据集的质量不高,需要对数据进行预处理。可先用Excel处理数据,调整数据集的格式并删除错误的数据行,随后用R语言加载数据。由于Excel2010最大只能支持1048576行,当数据集的行数超过这个限制后,可用Access加载数据,同时我们需要用Access对数据集中的三张表进行联结。

1、分析人群的年龄
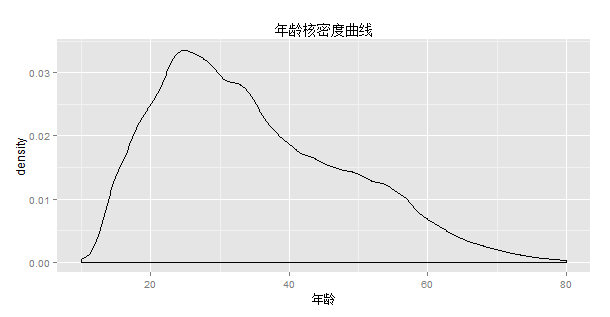
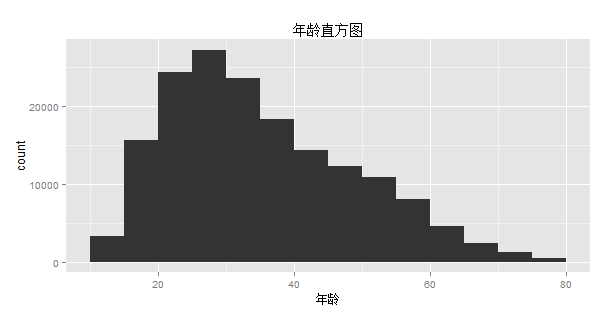
从以上两张图片可以看出,读书人群主要集中在20~40之间,且年龄呈偏态分布。
2、统计各国读书人群的数量
由于数据集包含了很多国家,不利于作图,因此只选择了排名靠前的12个国家。

可以看出,美国的读者人数最多。同时我们发现,母语为英语的国家占了很大的比重。一方面可能与人口基数有关;另一方面,我们可以猜想,在数据爬取的过程中可能优先选择了英语国家,造成了数据的有偏性。总之,在这里,我们不能妄下结论。
3、统计各类评分的数量
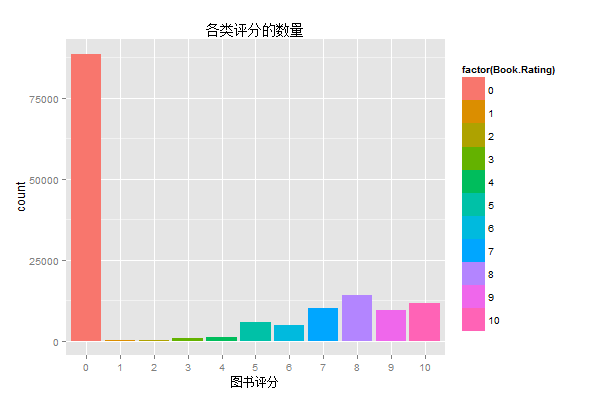
可以看出,很多图书没有得到评分(0分),可能是因为很多人不希望在这方面花费时间。在得到评分的数据里,评分主要集中在7~10分,而1~4分的数据很少,可以推测人们在评分这件事上偏于保守。
4、分析各国读者的年龄
首先画出以国家分组的年龄直方图。
 通过图片,我们还不能明显看出各国读者人群的年龄是否存在差异。
通过图片,我们还不能明显看出各国读者人群的年龄是否存在差异。
4.1、比较各国读者人群的人均年龄
比较各国的人均年龄,首先想到的方法是方差分析,但方差分析有两个假设条件——正态和方差齐性。由上面的分析可知,年龄的分布呈偏态分布。另外,我们还可以验证方差齐性。

p<0.05,所以方差齐性也不满足要求。因此,我们只能使用非参数检验(秩和检验)。

非参数检验的p值小于0.05,说明各国读者人群的人均年龄不全相同。

可以看出,usa的人均年龄最大,portugal的人均年龄最小。
5、分析年龄与图书评分的关系
同样的方法,我们可以分析年龄与评分的关系。

Kruskal-Wallis rank sum test
#非参数检验
data: Age by Book.Rating
Kruskal-Wallis chi-squared = 456.51, df = 10,
p-value < 2.2e-16 非参数检验的p值小于0.05,说明各类评分的读者人均年龄不全相同。

可以看出,给出1~4分的读者平均年龄略小。
6、分析活跃用户
找出阅读量排名前10的用户。

可以看出,即使是阅读量排名靠前的用户对评分的态度也会有所不同,例如ID为98391的用户对评分这件事比较积极且给出的分数较高,而ID为76352的用户就显得不够积极。
7、对图书进行关联分析(购物篮分析)
支持度0.001,置信度0.5,可得到23条规则。下图展现了前面的8条规则。
#需要分析的数据储存在user_analyze中 library(arules) user_analyze$ISBN<-as.character(user_analyze$ISBN) #制作购物篮数据 book_list<-as(split(user_analyze$ISBN,user_analyze$UserID),"transactions") #关联分析 rules<-apriori(book_list,parameter = list(support=0.001,confidence=0.5,minlen=2,maxlen=5)) inspect(rules)
 随后,我们可以根据ISBN码查看哪些书有较强的关联性。
随后,我们可以根据ISBN码查看哪些书有较强的关联性。
例如,我们可以分析前两条规则,ISBN码为0439064864的图书为《Harry Potter and the Chamber of Secrets (Book 2)》,ISBN码为0439136350的图书为《Harry Potter and the Prisoner of Azkaban (Book 3)》。前两条规则表明很多读者会同时选择这两本书,这也显得理所当然,因为这两本书是Harry Potter系列的第二部和第三部,所以经常会同时出现在一个人的读书单里。
标签:
原文地址:http://my.oschina.net/u/2369107/blog/416067