标签:blog http width strong 使用 文件
Paxos算法的难理解与算法的知名度一样令人敬仰,从我个人的经历而言,难理解的原因并不是该算法高深到大家智商不够,而在于Lamport在表达该算法时过于晦涩且缺乏一个完整的应用场景。如果大师能换种思路表达该算法,大家可能会更容易接受:
Lamport首先提出算法的起源,在没有任何辅助场景下,已经让很多人陷于泥潭,在满脑子疑问的前提下,根本无法继续接触算法的具体内容,更无从体会算法的精华。本文将换种表达方法对Paxos算法进行重新描述。
我们所有的描述都假设读者已经熟读了Lamport的paxos-simple一文,因此对各种概念不再解释。
除了Lamport的几篇论文,对Paxos算法描述比较简洁的中文文章是:http://zh.wikipedia.org/zh-cn/Paxos%E7%AE%97%E6%B3%95,该文翻译的比较到位,但在关键细节上还是存在一些歧义和一些对原文不正确的理解,可能会导致读者对Paxos算法更迷茫,但阅读该文可以快速地对Paxos算法有个大概的了解。
1.应用场景
(1)分布式中的一致性
Paxos算法主要是解决一致性问题,关于“一致性”,在不同的场景有不同的解释:
(2)MQ
假如所有系统的Log信息都写入一个MQ Server,然后通过MQ把每条Log指令发异步送到多个Log Server写入文件(写入多个Log Server的原因是对Log文件做备份以防数据丢失),则所有Log Server上的数据肯定是一致的(Log内容及顺序完全相同),因为MQ本身就有排序功能,只要进了Q数据也就有了序,相当于编了全局唯一的号,无论把这些数据写入多少个文件,只要按编号,各文件的内容必定是一致的,但一个MQ Server显然是一个单点,如果宕机,会影响整个系统的可用性。
(3)多MQ
要解决MQ单点问题,首选方案是采用多个MQ Server,即使用一个MQ Cluster,客户端可以访问任意MQ Server,不同的客户端可能访问不同MQ Server,不同MQ Server上的数据内容、顺序可能不一致,如果不解决这个问题,每个MQ Server写入Log Server的内容就不一致,这显然不是我们期望的结果。
(4)NoSQL中的数据更新
一般的NoSQL都会通过数据复制的形式保证其可用性,但客户端对多数据进行操作时,可能会有很多对同一数据的操作发送的某一台或几台Server,有可能执行:Insert、Update A、Update B....Update N,就一次Insert连续多次Update,最终复制Server上也必须执行这一的更新操作,如果因为线程池、网络、Server资源等原因导致各复制Server接收到的更新顺序不一致,这样的复制数据就失去了意义,如果在金融领域甚至会造成严重的后果。
上面这些不一致问题性正是Paxos算法要解决的,当然这些问题也不是只有Paxos能解决,在没有Paxos之前这些问题也得到了解决,比如通过使用双Master模式的MQ解决MQ单点问题;通过使用Master Server解决NoSQL的复制问题,但这些解决方法都存在一些缺陷,要么难水平扩展,要么影响可用性。当然除了Paxos算法还有其他一些算法也试图解决这类问题,比如:Viewstamped Replication算法。
上面描述的这些场景的共性是希望多Server之间状态一致,也就是一致性,再看中文Wiki开篇提到的:
在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点都执行相同的操作序列,那么他们最后能得到一个一致的状态。为保证每个节点执行相同的命令序列,需要在每一条指令上执行一个“一致性算法”以保证每个节点看到的指令一致
大家或许会对该描述有更深的理解。
2.Paxos如何解决这类问题
Paxos对这类问题的解决就是试图对各Server上的状态进行全局编号,如果能编号成功,那么所有操作都按照编号顺序执行,一致性就不言而喻。当Cluster中的Server都接收了一些数据,如何进行编号?就是表决,让所有的Server进行表决,看哪个Server上的哪个数据应该排第一,哪个排第二...,只要多数Server同意某个数据该排第几,那就排第几。
很显然,为了给每个数据唯一编号,每次表决只能产生一个数据,否则表决就没有任何意义。Paxos的算法的所有精力都放在如何在一次表决只产生一个数据。再进一步,我们称表决的数据叫Value,Paxos算法的核心和精华就是确保每次表决只产生一个Value。
3.Paxos算法
我们对原文的概念加以补充:
也就是说,Acceptor对proposer有两个动作:promise和accept
下面的解释也主要围绕着”Only a single value is chosen,“,再看下条件P1,
P1:An acceptor must accept the first proposal that it receives.
乍一看,这个条件是显然的,因为之前没有任何value,acceptor理所当然地应该accept第一个proposal,但仔细想想,感觉P1这个条件很不严格,到底是一个对问题的简单描述还是一个数学上严格的必要条件?这些疑问归结为2个问题:
(1)这个条件本质上在保证什么?
(2)第二个proposal怎么办?
在后续的算法中看到一个Acceptor是否批准一个Value与它是否是第一个没有任何关系,而与这个Proposal的编号有关。那岂不说明P1没有得到保证?开始我也百思不得其解,后来经过跟朋友交流发现,P1中的"accept"其实是指acceptor对proposer的"promise",就是语言描述跟算法的步骤描述之间存在歧义,因此我认为对算法问题还是应该采用数学语法而非文字语言。
所以,P1是强调了第一个proposal要被promise,但第二个还未提到,这也是疑问之一。
也很显然的是,单靠P1是无法保证Paxos算法的,因可能无法形成多数派,那接下来的讨论应该是考虑如何弥补P1的缺点,使其可以保证Paxos算法,就是我们希望未来的条件应该说明:
于是约束P2出现了:
P2:If a proposal with value v is chosen, then every higher-numbered proposal that is chosen has value v.
P2的出现让人大跌眼镜,P2并没沿着P1的路向下走,也没有解决P1的上述2个不完备,而是从另一个侧面讨论如何保证只能选出一个Value。P1讨论的是该如何选择,P2讨论的是一旦被选出来,之后的选择应该不变,就是P1还在讨论选的问题,P2已经选出来了,中间有个断层,怎么选的没有讨论。
其实从后面Lamport不断对P2增强可以看出,P2里面蕴含着P1(通过proposal编号,第一次之前没有编号,所以选择),P2才真正给出了怎么选择的具体过程,从事后分析看,P1给出了第一个该怎么选,P2给出了所有的该怎么选,条件有点重复。所以,把P1和P2看作是两个独立条件的做法是不准确的,因而中文wiki中提到“如果 P1 和 P2 都能够保证,那么约束2就能够保证”,对细微理解有一定的影响。
也不是说P1就没有用,反过来看,P2是个未知问题,而P1是这个未知问题的已知部分,从契约的角度来看,P1就是个不变式,任何对P2的增强都不能过了头以至于无法满足P1这个不变式,也就是说,P1是P2增强的底线。
那还有没有其他的不变式需要遵守?是否在对P2增强的过程中已破坏了这些未知的不变式?这些高难度的问题牵扯到Paxos算法正确性,要看MIT的严格的数学证明,已超出了本文。
另外,中文Wiki对P2的描述是:“P2:一旦一个 value 被批准(chosen),那么之后批准(chosen)的 value 必须和这个 value 一样。”,原文采用higher-numbered更能描述未来对proposal进行编号这个事实,而中文采用“之后”,已经完全失去这个意义。
我们暂时按下P1不表,近距离观察一下P2,为了保证每次选出一个value,P2规定在一个Value已经被选出的情况下,如果还有其他的proposer提交value,那之后批准的value应该跟前一个一致,就是在事实上已经选定一个value时,之后的proposer不能提交不同的value把之前的结果打乱。这是一个泛泛的描述,但如果这个描述能得到实现,paxos算法就能得到保证,因此P2也称"safety property"。
接下来的讨论都时基于“If a proposal with value v is chosen”,如何保证“then every higher-numbered proposal that is chosen has value v”,具体怎么做到“a proposal with value v is chosen"暂且不谈。
P2更多是从思想层面上提出来该如何解决这个问题,但具体的落实工作需要很多细化的步骤,Lamport是通过逐步增强条件的方式进行落实P2,主要从下面几个方面进行:
Lamport为什么能把过程划分的如此清楚已经不得而知,但从Lamport发表的文章来看,他对分布式有很深的造诣,也持续了很长的时间,能有如此的结果,与他对分布式的基础与背后的巨大努力有很大关系。但对我们而言,不知过程只知个结果,总感觉知其然不知其所以然。
我们沿着上面的思路继续:
P2a:If a proposal with value v is chosen, then every higher-numbered proposal accepted by any acceptor has value v.
这个条件是在限制acceptor,很显然,如果P2a得到了满足,满足P2是肯定的,但P2a的增强破坏了P1不变式的底线,具体参考原文,所以P2a本身没啥意义,转而从proposer端进行增强。
P2b:If a proposal with value v is chosen, then every higher-numbered proposal issued by any proposer has value v.
这个条件是在限制proposer,如果能限制住proposer,对acceptor的限制当然能被满足的。同时,因为限制proposer必须提交value v,也就顺便保证了P1(第一个肯定是value v)
但P2b是难以实现的,难实现的原因是多个proposer可以提交任意value的proposal,无法限制proposer不能提交某个value,因此需要寻找P2b的等价条件:
P2c:For any v and n, if a proposal with value v and number n is issued, then there is a set S consisting of a majority of acceptors such that either
(a) no acceptor in S has accepted any proposal numbered less than n, or
(b) v is the value of the highest-numbered proposal among all proposals numbered less than n accepted by the acceptors in S.
根据原文,P2c里面蕴含了P2b,但由P2c推导P2b是最难理解的部分。
首先要清楚P2c要做什么,因为P2b很难直接实现,P2c要做的就是解决P2b的问题,就是解决“如果value v被选择了,更高编号的提案已经具有value v”,也就是说:
就是要证明如果C成立,那么结果R成立,而原文的表达是“如果R成立,那么存在一个条件R”,容易让人搞混因果关系,再次感叹如果使用数学符号表达这样的歧义肯定会减少很多。
P2c解决问题的思路是:不是直接尝试去满足P2b,而是寻找能满足P2b的一个充分条件,如果能满足这个充分条件,那P2b的满足是显然的。还要强调一点的是proposer可以提交任意的value,你怎么能限制我提交的必须是value v呢?其实原文中的“For any v and n, if a proposal with value v and number n is issued”是指“如果一个编号为n的proposal提交value v,并且value v能被acceptor所接受”,要想被接受就不能随便提交一个value,就必须是一个受限制的value,这里讨论的前提是value v是要被接受的。然后我们再看下,是否满足了条件C,结果R就成立。
(a) no acceptor in S has accepted any proposal numbered less than n
如果这个条件成立,那么n是S中第一个proposal,根据P1,必须接受,所以结果R成立
(b) v is the value of the highest-numbered proposal among all proposals numbered less than n accepted by the acceptors in S
这个证明先假设编号为n的proposal具有value X被选择,肯定存在一个集合C,其中的每个acceptor都接受了value X,而集合S中的每个Acceptor都接受了value v,因为S、C都是多数派,所以存在一个公共成员u,既接受了X,又接受了v,为了保证选择的唯一性,必须X=v.
大家可能会发觉该证明有点不太严格,“小于n的最大编号”与n之间还有很多proposal,那些proposal也有一些value,那些value会不会不是v?
这个就会用到原文中的数学归纳法,就是任意的编号m的proposal具有了value v,那么n=m+1是,根据上面也是具有value v的,那么向后递推,任意的n >m都具有value v。中文wiki中的那个归纳证明不需要对m...n-1正推,而对n反证,通过数学归纳正推完全可以得出最终结果。
也就是说,P2c是P2b的一个加强,满足P2c就能满足P2b。
我们再近距离观察下P2c,发现只要在proposer提交提案前,咨询一下acceptor,看他们的最高编号是啥,他们是否选择了某个value v,再根据acceptor的回答进行选择新的编号、value提交,就可以满足P2c。通过编号,可以把(a)和(b)两个条件统一在一起。
其实P2c要表达的思想非常简单:如果前面有value v选出了,那以后就提交这个value v;否则proposer决定提交哪个value,具体做法就是事前咨询,事中决定,事后提交,也就是说可以通过消息传递模型实现。Lamport通过条件、集合、归纳证明等形式表达该问题,而没提这样做的目的,会导致理解很困难。大家可能会比较疑惑,难道自始至终只能选出一个value?其实这里的选出,是指一次选举,而不是整个选举周期,可以多次运行paxos,每次都只选出一个value。
满足P2c从侧面也反映出要想提交一个正确的value v,要对proposer、acceptor同时进行限制,仅限制一方问题是无法解决的。
再回顾下条件之间的递推关系P2c=>P2b=>P2a=>P2,就是说P2c最终保证了P2,也就是解决了如何做到一个value v被选择之后,被选择的编号更大的proposal都具有value v,P2c不仅保证P2的结果,更提出了“如何选”的问题,就是上面分阶段进行,这就填补了P1与P2之间缺少如何选的断层,还有P1的2个不完备问题从直观上感觉会得到解决,具体的要看算法过程章节。
P1的不完备问题:
P2c也顺便解决了P1的不完备问题,因为proposer提交的value是受acceptor限制的,就不会在一次选举中提交两个不同的value,即使能提交也会因为proposal编号问题有一个会被拒绝,从而能保证能形成多数派。
另一个关于第二个该怎么选的不完备问题,也是显然的了。
再次证明了,P2里面蕴含了P1,P1只是未知问题P2的不变式。
1.编号处理
根据P2c ,proposer在提案前会先咨询acceptor查看其批准的最大的编号和value,再决定提交哪个value。之前我们一直强调更高编号的proposal,而没有说明低编号的proposal该怎么处理。
|--------低编号(L<N)--------|--------当前编号(N)--------|--------高编号(H>N)--------|
P2c 的正确性是由当前编号N而产生了一些更高编号H来保证的,更低编号L在之前某个时刻,可能也是符合P2c 的,但因为网络通信的不可靠,导致L被延迟到与H同时提交,L与H有可能有不同的value,这显然违背了P2c ,解决办法是acceptor不接受任何编号已过期的proposal,更精确的描述为:
P1a : An acceptor can accept a proposal numbered n iff it has not responded to a prepare request having a number greater than n.
显然,acceptor接收到的第一个proposal符合这个条件,也就是说P1a 蕴含了P1。
关于编号问题进一步的讨论请参考下节的【再论编号问题:唯一编号 】。
2. Paxos算法形成
重新整理P2c 和P1a 可以提出Paxos算法,算法分2个阶段:
Phase1:prepare
(a)proposer选择一个proposal编号n,发送给acceptor中的一个多数派
(b)如果acceptor发现n是它已回复的请求中编号最大的,它会回复它已accept的最大的proposal和对应的value(如果有);同时还附有一种承诺:不会批准编号小于n的proposal
Phase2:accept
(a)如果proposer接收到了多数派的回应,它发送一个accept消息到(编号为n,value v的proposal)到acceptor的多数派(可以与prepare的多数派不同)
关键是这个value v是什么,如果acceptor回应中包含了value,则取其编号最大的那个,作为v;如果回应中不包含任何value,则有proposer随意选择一个
(b)acceptor接收到accept消息后check,如果没有比n大的回应比n大的proposal,则accept对应的value;否则拒绝或不回应
感觉算法过程异常地简单,而理解算法是怎么形成却非常困难。再仔细考虑下,这个算法又会产生更多的疑问:
保证paxos正确运行的一个重要因素就是proposal编号,编号之间要能比较大小/先后,如果是一个proposer很容易做到,如果是多个proposer同时提案,该如何处理?Lamport不关心这个问题,只是要求编号必须是全序的,但我们必须关心。这个问题看似简单,实际还稍微有点棘手,因为这本质上是也是一个分布式的问题。
在Google的Chubby论文中给出了这样一种方法:
假设有n个proposer,每个编号为ir (0<=ir <n),proposol编号的任何值s都应该大于它已知的最大值,并且满足:s %n = ir => s = m*n + ir
proposer已知的最大值来自两部分:proposer自己对编号自增后的值和接收到acceptor的reject后所得到的值
以3个proposer P1、P2、P3为例,开始m=0,编号分别为0,1,2
P1提交的时候发现了P2已经提交,P2编号为1 > P1的0,因此P1重新计算编号:new P1 = 1*3+0 = 4
P3以编号2提交,发现小于P1的4,因此P3重新编号:new P3 = 1*3+2 = 5
整个paxos算法基本上就是围绕着proposal编号在进行:proposer忙于选择更大的编号提交proposal,acceptor则比较提交的proposal的编号是否已是最大,只要编号确定了,所对应的value也就确定了。所以说,在paxos算法中没有什么比proposal的编号更重要。
活锁
当一proposer提交的poposal被拒绝时,可能是因为acceptor promise了更大编号的proposal,因此proposer提高编号继续提交。 如果2个proposer都发现自己的编号过低转而提出更高编号的proposal,会导致死循环,也称为活锁。
Leader选举
活锁的问题在理论上的确存在,Lamport给出的解决办法是选举出一个proposer作leader,所有的proposal都通过leader来提交,当Leader宕机时马上再选举其他的Leader。
Leader之所以能解决这个问题,是因为其可以控制提交的进度,比如果之前的proposal没有结果,之后的proposal就等一等,不着急提高编号再次提交,相当于把一个分布式问题转化为一个单点问题,而单点的健壮性是靠选举机制保证。
问题貌似越来越复杂,因为又需要一个Leader选举算法,但Lamport在fast paxos中认为该问题比较简单,因为Leader选举失败不会对系统造成什么影响,因此这个问题他不想讨论。但是后来他又说,Fischer, Lynch, and Patterson的研究结果表明一个可靠的选举算法必须使用随机或超时(租赁)。
Paxos本来就是选举算法,能否用paxos来选举Leader呢?选举Leader是选举proposal的一部分,在选举leader时再用paxos是不是已经在递归使用paxos?存在称之为PaxosLease的paxos算法简化版可以完成leader的选举,像Keyspace、Libpaxos、Zookeeper、goole chubby等实现中都采用了该算法。关于PaxosLease,之后我们将会详细讨论。
虽然Lamport提到了随机和超时机制,但我个人认为更健壮和优雅的做法还是PaxosLease。
Leader带来的困惑
Leader解决了活锁问题,但引入了一个疑问:
既然有了Leader,那只要在Leader上设置一个Queue,所有的proposal便可以被全局编号,除了Leader是可以选举的,与Paxos算法1 提到的单点MQ非常相似。
那是不是说,只要从多个MQ中选举出一个作为Master就等于实现了paxos算法?现在的MQ本身就支持Master-Master模式,难道饶了一圈,paxos就是双Master模式?
仅从编号来看,的确如此,只要选举出单个Master接收所有proposal,编号问题迎刃而解,实在无须再走acceptor的流程。但paxos算法要求无论发生什么错误,都能保证在每次选举中能选定一个value,并能被learn学习。比如leader、acceptor,learn都可能宕机,之后,还可能“苏醒”,这些过程都要保证算法的正确性。
如果仅有一个Master,宕机时选举的结果根本就无法被learn学习, 也就是说,Leader选举机制更多的是保证异常情况下算法的正确性,虚惊一场,paxos原来不是Master-Master。
在此,我们第一次提到了"learn"这个角色,在value被选择后,learn的工作就是去学习最终决议,学习也是算法的一部分,同样要在任何情况下保证正确性,后续的主要工作将围绕“learn”展开。
Paxos与二段提交
Google的人曾说,其他分布式算法都是paxos的简化形式。
假如leader只提交一个proposal给acceptor的简单情况:
其实就是一个二段提交问题,整个paxos算法可以看作是多个交叉执行而又相互影响的二段提交算法。
如何选出多个Value
Paxos算法描述的过程是发生在“一次选举”的过程中,这个在前面也提到过,实际Paxos算法执行是一轮接一轮,每轮还有个专有称呼:instance(翻译成中文有点怪),每instance都选出一个唯一的value。
在每instanc中,一个proposal可能会被提交多次才能获得acceptor的批准,一般做法是,如果acceptor没有接受,那proposer就提高编号继续提交。如果acceptor还没有选择(多数派批准)一个value,proposer可以任意提交value,否则就必须提交意见选择的,这个在P2c 中已经说明过。
Paxos中还有一个要提一下的问题是,在prepare阶段提交的是proposal的编号,之后再决定提交哪个value,就是value与编号是分开提交的,这与我们的思维有点不一样。
3. 学习决议
在决议被最终选出后,最重要的事情就是让learn学习决议,学习决议就是决定如何处理决议。
在学习的过程中,遇到的第一个问题就是learn如何知道决议已被选出,简单的做法就是每个批准proposal的acceptor都告诉每个需要学习的learn,但这样的通信量非常大。简单的优化方式就是只告诉一个learn,让这个唯一learn通知其他learn,这样做的好是减少了通信量,但坏处同样明显,会形成单点;当然折中方案是告诉一小部分learn,复杂性是learn之间又会有分布式的问题。
无论如何,有一点是肯定的,就是每个acceptor都要向learn发送批准的消息,如果不是这样的话,learn就无法知道这个value是否是最终决议,因此优化的问题缩减为一个还是多个learn的问题。
能否像proposer的Leader一样为learn也选个Leader?因为每个acceptor都有持久存储,这样做是可以的,但会把系统搞的越来越复杂,之后我们还会详细讨论这个问题。
Learn学习决议时,还有一个重要的问题就是要按顺序学习,之前的选举算法花费很多精力就是为了给所有的proposal全局编号,目的是能被按顺序使用。但learn收到的决议的顺序可能不不一致,有可能先收到10号决议,但9号还未到,这时必须等9号到达,或主动向acceptor去请求9号决议,之后才能学习9号、10号决议。
4. 异常情况、持久存储
在算法执行的过程中会产生很多的异常情况,比如proposer宕机、acceptor在接收proposal后宕机,proposer接收消息后宕机,acceptor在accept后宕机,learn宕机等,甚至还有存储失败等诸多错误。
但无论何种错误必须保证paxos算法的正确性,这就需要proposer、aceptor、learn都做能持久存储,以做到server”醒来“后仍能正确参与paxos处理。
以上就是paxos算法的大概介绍,目的是对paxos算法有粗略了解,知道算法解决什么问题、算法的角色及怎么产生的,还有就是算法执行的过程、核心所在及对容错处理的要求。
但仅根据上面的描述还很难翻译成一个可执行的算法程序,因为还有无限多的问题需要解决:
众多问题如雪片般飞来,待这些都逐一解决后才能讨论实现的问题。当然还有一个最重要的问题,paxos算法被证明是正确的,但程序如何能被证明是正确的?
前两篇Paxos算法的讨论,让我们对paxos算法的理论形成过程有了大概的了解,但距离其成为一个可执行的算法程序还有很长的路要走,原因是很多的细节和错误未被考虑。Google Chubby的作者说,paxos算法实现起来远没有看起来简单,原因是paxos的容错仅限于server crash这一种情况,但在实际工程实现时要考虑磁盘损坏、文件损坏、Leader身份丢失等诸多的错误。
1. Paxos各角色的职能
在paxos算法中存在Client、Proposer、Proposer Leaer、Acceptor、Learn五种角色,可精简为三种主要角色:proposer、acceptor、learn。角色只是逻辑上存在的,在实际实现中,节点可以身兼多职。
在我们的讨论中,我们先假定没有Proposer Leader这一角色,在不考虑活锁的情况下,如果算法过程正确,那有Leader角色的算法过程肯定也正确。
除了五种角色,还有三个重要的概念:instance、proposal、value,分别代表:每次paxos选举过程、提案、提案的value
当然,还有4个关键过程:
对acceptor来说,还蕴含是着promise、accept、reject三个动作。
先上一幅图,更直观地对几种角色的职能加以了解(各角色的具体职能参考Lamport的论文就足够了):
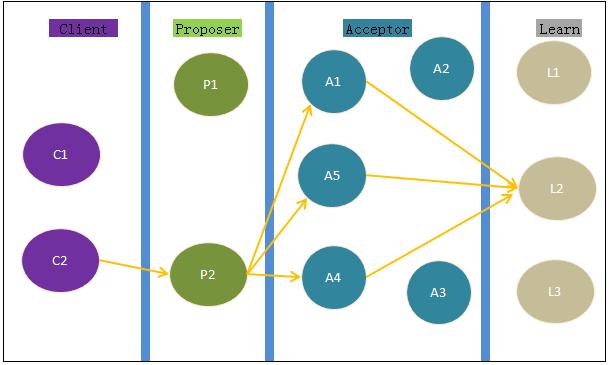
上图不是非常严格,仅为表现各角色之间的关系。
2. Proposer
在Proposer、Acceptor、Learn中均涉及到proposal的编号,该编号应该有proposer作出改变,对其他的角色是只读的,这就保证了只有一个数据源。当多个proposer同时提交proposal时,必须保证各proposer的编号唯一、且可比较,具体做法之前已经提到。这里还要强调一点的是,仅每个proposer按自己的规则提高编号是不够的,还必须了解“外面”的最大编号是多少,例如,P1、P2、P3(请参考:Paxos算法2#再论编号问题:编号唯一性)
这要求acceptor要在reject消息中给出当前的最大编号,proposer可能出现宕机,重启后继续服务,reject消息会帮助它迅速找到下一个正确编号。但是当多个acceptor回复各自不一的reject消息时,事情就变得复杂起来。
当proposer发送proposal给一个acceptor时,会有三种结果:
在判断是否可以进行Phase2时的一个充分条例就是:必须有acceptor的多数派promise了当前的proposal。
下面分别从Phase1和Phase2讨论proposer的行为:
Phase1-prepare:发送prepare到acceptor
Proposer在本地选择proposal编号,发送给acceptor,会收到几种情况的response:
(a). 没有收到多数派的回应
消息丢失、Server宕机导致没有多数派响应,在可靠消息传输(TCP)下,应该报告宕机导致剩余的Server无法继续提供服务,在实际中一个多数派同时宕机的可能性非常小。
(b). 收到多数派的reject
Acceptor可能会发生任意的错误,比如消息丢失、宕机重启等,会导致每个acceptor看到的最大编号不一致,因而在reject消息中response给proposer的最大编号也不一致,这种情况proposer应该取其最大作为比较对象,重新计算编号后继续Phase1的prepare阶段。
(c). 收到多数派的promise
根据包含的value不同,这些promise又分三种情况:
全部为null的情况比较好处理,只要proposer自由决定value即可;多数派达成一致的情况也好处理,选择已经达成决议的value提交即可,value互不相同的情况有两种处理方式:
其实问题的本质是:在一个instance内,一个acceptor是否能accept多个value?约束P2只是要求,如果某个value v已被选出,那之后选出的还应该是v;反过来说,如果value v还没有被多数派accept,也没有限制acceptor只accept一个value。
感觉两种处理方式都可以,只要选择一个value,能在paxos之后的过程中达成一致即可。其实不然,有可能value v已经成为了最终决议,但acceptor不知道,如果这时不选择value v而选其他value,会导致在一次instance内达成两个决议。
会不会存在这样一种情况:A、B、C、D为多数派的promise,A、B、C的proposal编号,value为(1,1),D的为(2,2)?就是说,编号互不一致,但小编号的已经达成了最终决议,而大编号的没有?
设:小编号的proposal为P1,value为v1;大编号的proposal为P2,value为v2
也就是说,只要按照【方案2】选择value就能保证结果的正确性。之所以能有这样的结果,关键还是那个神秘的多数派,这个多数派起了两个至关重要的作用:
而多数派能起作用的原因就是,任何两个多数派至少有一个公共成员,而这个公共成员对后续proposal的行为起着决定性的影响,如果这个多数派拒绝了后续的proposal,这些proposal就会因为无法形成新的多数派而进行不下去。这也是paxos算法的精髓所在吧。
Phase2-accept:发送accept给acceptor
如果一切正常,proposer会选择一个value发送给acceptor,这个过程比较简单
accept也会收到2种回应:
(a). acceptor多数派accept了value
一旦多数派accept了value,那最终决议就已达成,剩下的工作就是交由learn学习并关闭本次选举(instance)。
(b). acceptor多数派reject了value或超时
说明acceptor不可用或提交的编号不够大,继续Phase1的处理。
proposer的处理大概如此,但实际编程时还有几个问题要考虑:
其他2个问题比较简单,持久化的问题有必要讨论下。
持久化的目的是在proposer server宕机“苏醒”时,可以继续参与paxos过程。
从前面分析可看出,proposer工作的正确性是靠编号的正确性来保证的,编号的正确性是由proposer对编号的初始化写及acceptor的reject一起保证的,所以只要acceptor能正常工作,proposer就无须持久化当前编号。
3. acceptor
acceptor的行为相对简单,就是根据提案的编号决定是否接受proposal,判断编号依赖promise和accept两种消息,因此acceptor必须对接收到的消息做持久化处理。根据之前的讨论也知道,acceptor的持久化也会影响着proposer的正确性。
在acceptor对proposal进行决策的时候,还有个重要的概念没有被详细讨论,即instance。任何对proposal的判断都是基于某个instance,即某次paxos过程,当本次instance宣布结束(选出了最终决议)时,paxos过程就转移到下一个instance。这样会衍生出几个问题:
根据1中对各角色职能的讨论,决议是否被选出是由learn来决定的,当learn得知某个value v已经被多数派accept时,就认为决议被选出,并宣布关闭当前的instance。与2中提到的一样,因为网络原因acceptor可能不会得知instance已被关闭,而会继续对proposer回答关于该instance的问题。也就是说,无论如何acceptor都无法准确得知instance是否关闭,acceptor程序的正确性也就不能依赖instance是否关闭。但acceptor在已经知道instance已被关闭的情况下,在拒绝proposer时能提供更多的信息,比如,可以使proposer选择一个更高的instance重新提交请求。
当然,只要proposer根据2中提到的方式进行提案,就不会发生同一instance中产生两个决议的情况。
4. learn
learn的主要职责是学习决议,但决议必须一个一个按顺序学,不能跳号,比如learn已经知道了100,102号决议,必须同时知道101时才能一起学习。只是简单的等待101号决议的到来显然不是一个好办法,learn还要去主动向acceptor询问101号决议的情况,acceptor会对消息做持久化,做到这一点显然不难。
learn还要周期性地check所接收到的value,一旦意识到决议已经达成,必须关闭对应的instance,并通知acceptor、proposer等(根据需要可以通知任意多的对象)。
learn还存在一个问题是,是选择一个server做learn还是选多个,假如有N个acceptor,M个learn,则会产生N*M的通信量,如果M很大则通信量会非常大,如果M=1,通信量小但会形成单点。折中方案是选择规模相对较小的M,使这些learn通知其他learn。
paxos中的learn相对比较抽象,好理解但难以想象能做什么,原因在于对paxos的应用场景不清晰。一般说来有两种使用paxos的场景:
如果把paxos作为单独的服务,那learn的作用就是达成决议后通知客户端;如果是应用的一部分,learn则会直接执行业务逻辑,比如开始数据复制。
持久化:
learn所依赖的所有信息就是value和instance,这些信息都已在acceptor中进行了持久化,所以learn不需要再对消息进行持久化,当learn新加入或重启时要做的就是能通过acceptor把这些信息取回来。
错误处理:
learn可能会重启或新加入后会对“之前发生的事情”不清楚,解决办法是:使learn继续监听消息,直至某个instance对应的value达成一致时,learn再向acceptor请求之前所有的instance。
至此,我们进一步讨论了paxos个角色的职责和可能的实现分析,离我们把paxos算法变为一个可执行程序的目标又进了一步,使我们对paxos的实现方式大致心里有底,但还有诸多的问题需要进一步讨论,比如错误处理。虽然文中也提到了一些错误及处理方式,但还没有系统地考虑到所有的错误。
标签:blog http width strong 使用 文件
原文地址:http://www.cnblogs.com/duanxz/p/3783416.html