标签:
fast rcnn
统一了sppnet和rcnn,将原来rcnn分stage的训练合为一个整体的stage,一次完成cls, regression的训练。引入两个loss函数,一个是用来进行cls的,一个是进行regression的,这个思路其实是和google的multibox类似的,但是不同的是regression是对bbox的,而bbox怎么引入到cnn中,同时还可以进行训练呢,这就是sppnet的思路了。fast rcnn在训练cnn时,就是借鉴了spp,通过引入roipooling layer,将用selective search得到的2K的regions通过roipooling layer映射到具体的patch上,类似于sppnet,然后每个patch分别进行分类和regression,这样就一次性完成了所有regions的分类和定位。fastrcnn既利用了sppnet在前面几层统一用conv和pooling对整图进行计算的计算资源节约的特征,又通过引入roipooling 层,将sppnet无法完成的整体cnn的ft完成了,同时引入了l1 norm对regression进行调整,做到了end-to-end.流程框架如下图,图里我少了一条线,roi的label应该是cls的loss的输入之一。
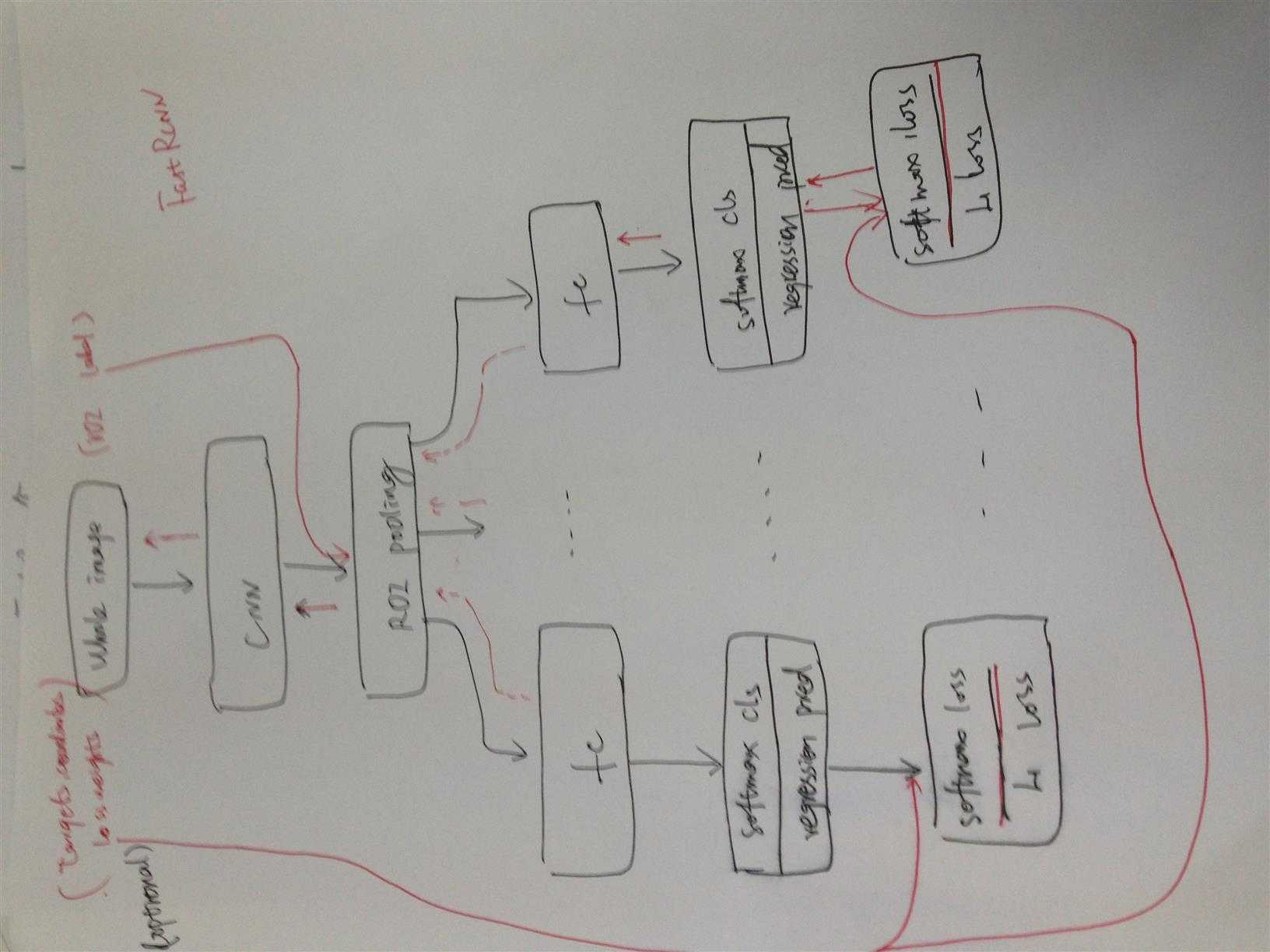
这篇文章看似内容没那么多,但是很重要,而且其实在细节的很多地方都值得借鉴,代码写的也是相当完美。
Multi-Objective Convolutional Learning for Face Labeling,其实是引入了单个pixel的loss,以及pixel之间的邻域loss,即引入了crf的两个energy,通过引入这两个loss完成对cnn的训练,但是在进行test时,并不用crf,使用graphcut完成分割。我个人觉得有点类似于fcn,但是fcn是单纯对pixel的分类,而本文通过引入crf,利用了pixel之间的关系,根据作者所说,这么做提高了不少。
Object detection via a multi-region & semantic segmentation-aware CNN model
本文我读了一下,有点类似于是sppnet,但是不同的是在生成特征时,把一个regions,通过不同方向的裁剪,得到很多个regions,而后这些regions分别得到特征,然后把这些特征通过spp统一到一个尺度,最后展开作为一个大特征,完成检测。而在分割时,直接用bbox作为正样本,而不需要那么严格的pixel级别的正样本,cnn能够对bbox带来的噪声具有鲁棒性。具体需要细看。
multibox,google的工作,整图作为输入,得到的是confidence和可能存在object的bbox位置,fastrcnn其实借鉴了这个思路。但是感觉google的工作很庞大,不知道能不能调试下来。
fcn,通过cnn,完成分割,这个工作的出现,引入了很多后续工作。
cnn-crf(deeplab),是cnn和crf分stage训练的,但是和别的思路不一样的地方是,crf在分割时起到作用了,而cnn的训练又没有用到crf。
最近就在不停的读文章和比较其中的差别了,其中可以分为两个路子,fastrcnn, multibox; fcn cnn-crf。
标签:
原文地址:http://www.cnblogs.com/jianyingzhou/p/4513780.html