标签:
基于贝叶斯定理是在18世纪提出来的,经过近300年的发展贝叶斯相关理论已经发展的较为成熟,其中贝叶斯分类算法在邮件过滤领域中被广泛应用。
贝叶斯的分类的关键在与概率推论,在各种不确定的田间下,通过变量出现的在所属分类的概率,在一定的阀值下确定分类。分类器基于这样一个假设:一个变量的各种特征都是独立的,尽管与现实生活中的情况是不相符的,例如一个人的皮肤颜色是黑色的、个子比较高、鼻梁突出、语言是英语、所属国家是南非,这些对象的特征之间是有或多或少的关联,这些特征出现的概率也是多维的条件概率。独立性的假设有利于简化贝叶斯分类中概率的计算。
贝叶斯分类需要依靠一个已知的概率模型[2, 4],这些模型是通过已知的样本分布所得出的,根据特征对象在函数中的分布,计算出每个对象各个类别中出现的概率。由于对象的特征都是独立的,通过最大似然估计可以通过特征出现的概率计算对象出现的概率。
贝叶斯分类的依据是贝叶斯定理[2, 3],在此基础上通过先验知识和最大似然函数来估计后验概率。在概率论中一个随机变量出现与条件概率 以及边缘概率。即事件B出现的前提是A事件发生,那么A事件发生的概率(即:B在事件A发生的条件下的概率) 是A,B全部发生的概率除以A事件发生的概率。
????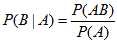 ????
????
于是我们可以得到:
????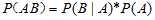 ????
????
或
????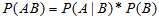 ????
????
整理可得:
????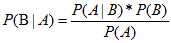 ????
????
这便是贝叶斯定理。
那么,假设当前测试的总样本有K个类别 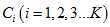 ,每个样本为
,每个样本为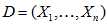 且具有n个特征,n个特征值决定了整个对象所属的类别。那么
且具有n个特征,n个特征值决定了整个对象所属的类别。那么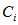 的先验概率为
的先验概率为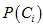 ,其样本的数量除以测试总样本的数量。那么在总样本中随机选择一个样本D,则它属于类别
,其样本的数量除以测试总样本的数量。那么在总样本中随机选择一个样本D,则它属于类别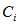 的概率
的概率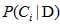 (也称为后验概率)可以根据贝叶斯定理可得:
(也称为后验概率)可以根据贝叶斯定理可得:
?
????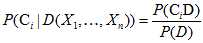 ????
????
进而可得:
????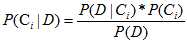 ????
????
由此我们可以进一步说明利用贝叶斯定理如何去分类。为计算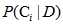 需要条件以及函数,因此在定义上就可以这样描述贝叶斯分类:
需要条件以及函数,因此在定义上就可以这样描述贝叶斯分类:
已知:
类别: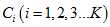
N维特征的向量: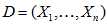
先验概率[12]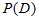 :D的出现是不依赖C的,对于每个出现的D它的N维特征的值也是已知的,且相互独立。于是分母常认定为一个常数(假设为1)
:D的出现是不依赖C的,对于每个出现的D它的N维特征的值也是已知的,且相互独立。于是分母常认定为一个常数(假设为1)
先验概率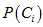 :是一个定值,在实际生活中是已知的。
:是一个定值,在实际生活中是已知的。
似然函数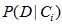 :某类中的样本取某个特征值的可能性
:某类中的样本取某个特征值的可能性
????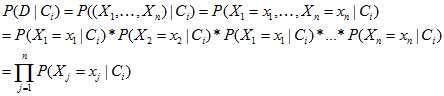 ????
????
可得:
?
????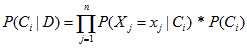 ????
????
于是得到了初步的计算后验概率的公式,完善公式,设置一个缩放因子(证据因子),保证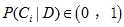 。然后为保证
。然后为保证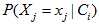 不为0,即避免零频问题,利用拉普拉斯变换(为了解决这个问题,我们引入Laplace校准,它的思想非常简单,就是对没类别下所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的尴尬局面。)
不为0,即避免零频问题,利用拉普拉斯变换(为了解决这个问题,我们引入Laplace校准,它的思想非常简单,就是对没类别下所有划分的计数加1,这样如果训练样本集数量充分大时,并不会对结果产生影响,并且解决了上述频率为0的尴尬局面。)
????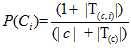 ????
????
其中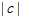 是训练样本中类别的个数,
是训练样本中类别的个数,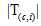 为训练样本中所属
为训练样本中所属 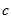 的样本数量,
的样本数量,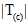 为训练样本总量。
为训练样本总量。
????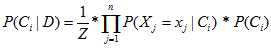 ????
????
?
对后验概率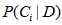 的计算需要先验概率
的计算需要先验概率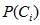 和独立概率分布
和独立概率分布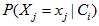 的支持,先验概率
的支持,先验概率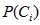 是属于
是属于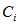 的样本数量与样本总量的比例,如果训练样本是随机选取于样本空间,并且样本容量足够大,那么估计值真实正的偏差越小。独立概率分布函数
的样本数量与样本总量的比例,如果训练样本是随机选取于样本空间,并且样本容量足够大,那么估计值真实正的偏差越小。独立概率分布函数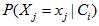 是以某种形式分布的概率密度函数,它代表了每个特征属性对于类别的概率分布,这些参数需要从训练集中样本特征的分布情况进行估计[8, 12]。例如:一个班级中有男生女生,一般情况身高如果能达到180cm,那么这个人有90%的可能性是一个男生,这个180cm就是身高属性对于男生这个类别的参数的值。估计这种参数的方法有很多,可以分为参数估计和非参数估计。前者是先假定类条件概率密度具有某种确定的分布形式,例如符合正态分布、二项分布,再用已经具有类别标签的训练样本集对概率分布的参数进行估计。后者是在不知道或者不假设类条件概率密度的分布形式的基础上,直接用训练集中所包含的信息来估计样本的概率分布情况。 所有的模型参数都可以通过训练集的相关频率来估计。常用参数估计的方法是概率的最大似然估计, 而且一般现实生活中大部分样本空间在样本容量趋于无限大的时候都会呈现出正态分布的特征,对于一些连续的变量而言这种特性更加明显,例如二项分布,
是以某种形式分布的概率密度函数,它代表了每个特征属性对于类别的概率分布,这些参数需要从训练集中样本特征的分布情况进行估计[8, 12]。例如:一个班级中有男生女生,一般情况身高如果能达到180cm,那么这个人有90%的可能性是一个男生,这个180cm就是身高属性对于男生这个类别的参数的值。估计这种参数的方法有很多,可以分为参数估计和非参数估计。前者是先假定类条件概率密度具有某种确定的分布形式,例如符合正态分布、二项分布,再用已经具有类别标签的训练样本集对概率分布的参数进行估计。后者是在不知道或者不假设类条件概率密度的分布形式的基础上,直接用训练集中所包含的信息来估计样本的概率分布情况。 所有的模型参数都可以通过训练集的相关频率来估计。常用参数估计的方法是概率的最大似然估计, 而且一般现实生活中大部分样本空间在样本容量趋于无限大的时候都会呈现出正态分布的特征,对于一些连续的变量而言这种特性更加明显,例如二项分布,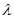 分布都会有这样的特征,因此针对训练样本
分布都会有这样的特征,因此针对训练样本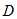 中的连续的特征属性
中的连续的特征属性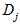 对于
对于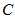 类的分布中,它的均值
类的分布中,它的均值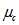 以及方差
以及方差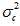 会服从标准正态分布
会服从标准正态分布
????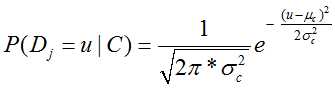 ????
????
即高斯分布,由此来估计相关属性的参数。就文本分类而言可以采用简单的统计来的得到各个特征属性的参数即可。
伪代码示例:
void?Bayes_classifier()??
{??
????分词(以词为特征);??
????特征选择(假设选取20个特征词);??
????foreach(c?in?C)
{?//?C为类别的集合??
????????计算P(c);?//?|S(c)|?/?|S|??
foreach(f?in?F)?{?//?F为选取的特征的集合??
????????????计算P(f?|?c);?//?Num(f?in?S(c))?/?Num(f?in?S),避免零频问题??
}??
}??
foreach(t?in?T)?{?//?T为测试集??
????分词;??
????构造特征向量X;??
????foreach(c?in?C)?{??
????????计算P(X?|?c)*P(c);??
}??
将t归类为P(X|c)*P(c)值最大的类别c;??
????}??
标签:
原文地址:http://www.cnblogs.com/bad-heli/p/4515409.html