标签:
提高系统运行效率,从应用程序通信做起。当前流行的互联网平台由多个分布式应用程序串连,它们就像流水线一样处理数据,产能的高低受制于流水线的运转速度。以前人们使用扫描数据库的方式来交互,即承担流水线职责是数据库,显然数据库应该承担的是仓库职责。每个生产环节都不停的跑到仓库去询问,有没有它要加工的产品,仓库的压力可想而知,生产效率可想而知。没有工厂会这样运行,但你的项目就这样干过。
我们需要在各应用程序间建立有效的通信机制来承担流水线的职责,去掉轮询将会有效降低数据库的压力。轮询带来的弊端有:
1. 硬件资源投入随着用户的增加成比例上升。工厂要生产更多的商品,厂长就得增加更多的仓库来服务,否则仓库会由于压力太大而崩溃。但由于流水线本身的运转速度不够,投入产出比太低。
2. 稳定性不足,可靠性不够。订单多的时候仓库忙不过来,没订单的时候仓库也没闲着,尽管这时候仓库里没货也有很多人来问。同时,为了防止不同流水线拿错商品,仓库还要做好登记,标明哪个商品在哪条流水线生产。受制于此,产能极易受到波动,一点小小的冲击可能造成灾难性的后果。
3. 结构复杂,维护困难,难以满足灵活多变的业务需求。某天市场部门收到新产品的订单,需要培训新的生产工人,仓库也需要为此做出改变,并增加更多的仓库,牵一发动全身,难以按时交货。好不容易顶住压力完成交货,却由于质量不高客户怨声载道。新产品市场反应不好,不再有订单需要生产,刚投入的资源需要全部收回。笨重的生产流程难以适应市场需求,我们需要灵活、高效、可靠的生产线。
如何能抛弃轮询的机制,让信息高效传递呢? 数据量大,实时性要求高是互联网系统的重要特点,技术团队需要有所创新和改变,敢于直面用户需求。
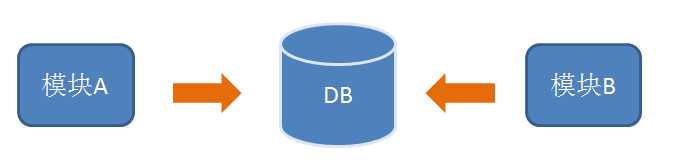
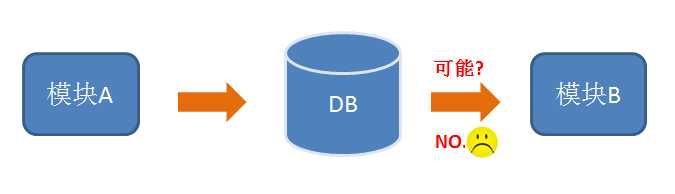
如果各应用程序依靠轮询数据库来传递消息,模块A做完后将数据写入数据库,模块B通过轮询数据库来确定模块A已经完成,它看起来就像这样:
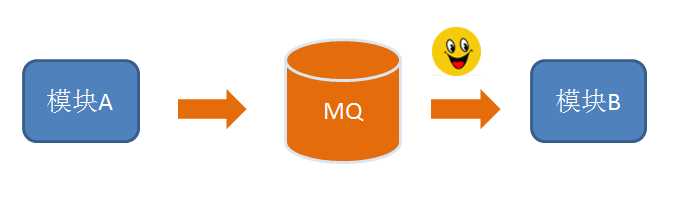
如此调整之后将有效降低数据库的负载,结构优雅高效,提高了稳定性,降低无谓的资源消耗。调整后各组件职责更为明确,做组件擅长的事情。数据库负责持久化数据、Redis负责缓存热数据、MQ负责在应用程序间传递消息。
流水线上一环节生产的半成品直接交给下一环节再加工,提高了工人效率,解放了仓库保管员,市场部不再抱怨生产部了,这才是真正的流水线。
标签:
原文地址:http://www.cnblogs.com/zeeman/p/4517584.html