标签:
.
.
.
.
.
目录
(一) 一起学 Unix 环境高级编程 (APUE) 之 标准IO
(二) 一起学 Unix 环境高级编程 (APUE) 之 文件 IO
(三) 一起学 Unix 环境高级编程 (APUE) 之 文件和目录
(四) 一起学 Unix 环境高级编程 (APUE) 之 系统数据文件和信息
(五) 一起学 Unix 环境高级编程 (APUE) 之 进程环境
(六) 一起学 Unix 环境高级编程 (APUE) 之 进程控制
(七) 一起学 Unix 环境高级编程 (APUE) 之 进程关系 和 守护进程
(八) 一起学 Unix 环境高级编程 (APUE) 之 信号
(九) 一起学 Unix 环境高级编程 (APUE) 之 线程
(十) 一起学 Unix 环境高级编程 (APUE) 之 线程控制
(十一) 一起学 Unix 环境高级编程 (APUE) 之 高级 IO
1.非阻塞 I/O
高级 IO 部分有个很重要的概念是:非阻塞 I/O
在14章之前,我们讨论的所有函数都是阻塞的函数,例如 read(2) 函数读取设备时,设备中如果没有充足的数据,那么 read(2) 函数就会阻塞等待,直到有数据可读再返回。
当 IO 操作时出现了错误的时候,我们之前在讨论信号的博文中提到过会出现假错的情况。
那么从学了非阻塞 I/O 为止我们一共遇到了两种假错的情况:
EINTR:被信号打断,阻塞时会遇到。
EAGAIN:非阻塞形式操作失败。
遇到这两种假错的时候我们需要重新再操作一次,所以通常对假错的判断是放在循环中的。
例如 read(2) 函数使用非阻塞方式读取数据时,如果没有读取到数据,errno 为 EAGAIN,此时并不是说设备有问题或读取失败,只是表明采用的是非阻塞方式读取而已。
阻塞与非阻塞是使用的同一套函数,flags 特殊要求指定为 O_NONBLOCK 就可以了。
下面我们举个小栗子:(伪代码)
1 fd = open("/etc/service", O_RDONLY | O_NONBLOCK); 2 /* if error */ 3 4 while (1) { 5 size = read(fd, buf, BUFSIZE); 6 if (size < 0) { 7 if (EAGAIN == errno) { 8 continue; 9 } 10 perror("read()"); 11 exit(1); 12 } 13 14 // do sth... 15 16 }
上面的小栗子, 首先在 open(2) 的时候使用特殊要求 O_NONBLOCK 指定以非阻塞形式打开文件。
当 read(2) 发生错误时要判断是否为假错,如果发生了假错就再试一次,如果是真错就做相应的异常处理。
2.有限状态机
大家先考虑一个问题:把大象放到冰箱里需要几步?
1)打开冰箱门;
2)把大象放进去;
3)关闭冰箱门;
这就是解决这个问题的自然流程。
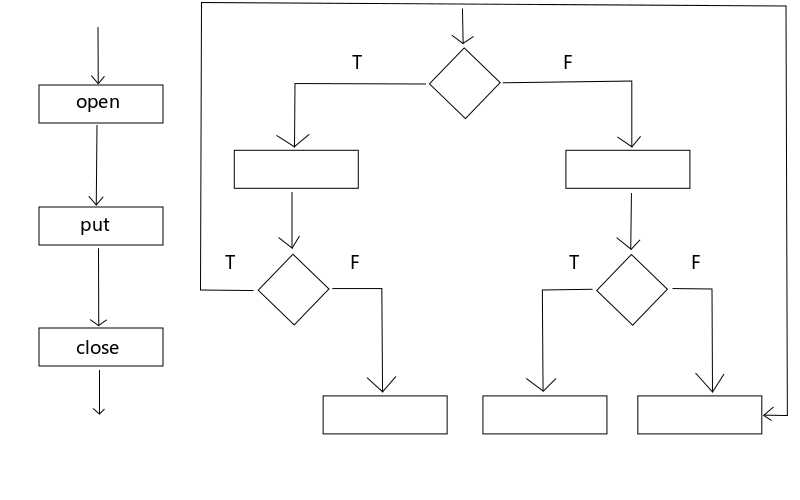
图1 简单流程与复杂流程
把一个问题的解决步骤(自然流程)摆出来发现是结构化的流程就是简单流程,如果不是结构化的流程就是复杂流程。所有的网络应用和需要与人交互的流程都是复杂流程。
结构化的流程就是作为人类的本能解决问题的思路。
在之前的博文中 LZ 提到过一个“口令随机校验”的策略大家还记得吗?就是要求用户必须连续两次输入正确的密码才认为校验通过。就算是这样小的模块也不会用一个单纯的顺序选择流程把它完成,它一定是一个非结构化的流程。
有限状态机就是程序设计的一种思路而已,大家刚开始接触觉得难以理解,那是因为还没有习惯这种设计思路。我们为什么觉得像原先那种流程化的程序设计思路好用?那是因为被虐惯了,你曾经被迫习惯用计算机的思路来考虑问题而不是用作为人解决问题的本能步骤来考虑问题。有限状态机就是让你以作为人的本能的解决问题的方式来解决问题,当你习惯了有限状态机的设计思想之后就不觉得这是什么难以理解的东西了。
有限状态机被设计出来的目的就是为了解决复杂流程的问题,所以更何况是简单流程的问题也一样能够轻松的解决。
作为程序猿最怕的是什么?
恐怕最怕的就是需求变更了吧。
为什么要使用有限状态机的设计思路呢?因为它能帮助我们从容的应对需求变更。
使用有限状态机编程的程序在面对需求变更的时候往往仅需要修改几条 case 语句就可以了,而没有使用有限状态机编程的程序面对需求变更往往要把大段的代码推倒重来。
所以如果你掌握了有限状态机的编程思想,那么在很多情况下都可以相对轻松的解决问题,而且程序具有较好强的健壮性。
说了这么多废话,有限状态机到底是什么呢?
使用有限状态机首先要把程序的需求分析出来(废话,用什么编程都得先分析需求),然后把程序中出现的各种状态抽象出来制作成一张状态机流程图,然后根据这个流程图把程序的框架搭建出来,接下来就是添枝加叶了。
下面我们通过一个栗子来说明有限状态机的设计思想。
假如有如下需求:从设备 tty11 读取输入并输出到 tty12 上,同样从 tyy12 读取输入并输出到 tty11 上。
首先我们把它的各种状态抽象出来画成一幅图。
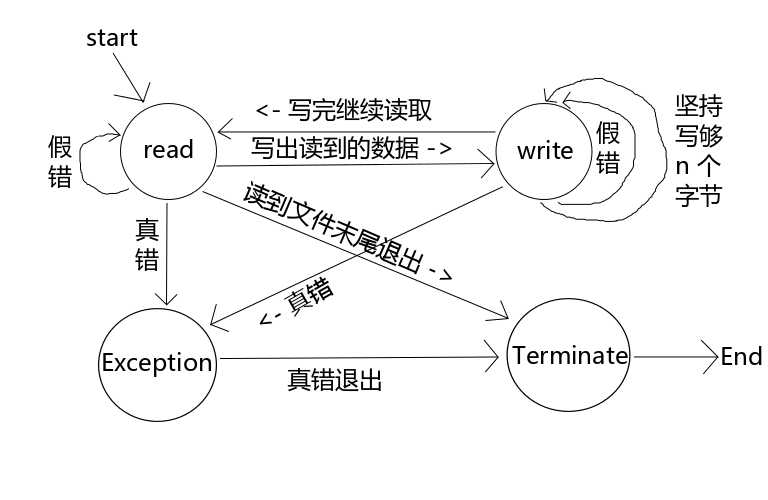
图2 有限状态机
每个状态画成一个圆形节点,每个节点延伸出来有多少条线就表示有多少种可能性。
这些节点拿到我们的程序中就变成了一条条 case 语句,下面我们看看使用代码如何实现。
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <unistd.h> 4 #include <sys/types.h> 5 #include <sys/stat.h> 6 #include <fcntl.h> 7 #include <errno.h> 8 9 #define BUFSIZE 1024 10 #define TTY1 "/dev/tty11" 11 #define TTY2 "/dev/tty12" 12 13 /* 状态机的各种状态 */ 14 enum 15 { 16 STATE_R=1, 17 STATE_W, 18 STATE_Ex, 19 STATE_T 20 }; 21 22 /* 状态机,根据不同的需求设计不同的成员 */ 23 struct fsm_st 24 { 25 int state; // 状态机当前的状态 26 int sfd; // 读取的来源文件描述符 27 int dfd; // 写入的目标文件描述符 28 char buf[BUFSIZE]; // 缓冲 29 int len; // 一次读取到的实际数据量 30 int pos; // buf 的偏移量,用于记录坚持写够 n 个字节时每次循环写到了哪里 31 char *errstr; // 错误消息 32 }; 33 34 /* 状态机驱动 */ 35 static void fsm_driver(struct fsm_st *fsm) 36 { 37 int ret; 38 39 switch(fsm->state) 40 { 41 case STATE_R: // 读态 42 fsm->len = read(fsm->sfd,fsm->buf,BUFSIZE); 43 if(fsm->len == 0) // 读到了文件末尾,将状态机推向 T态 44 fsm->state = STATE_T; 45 else if(fsm->len < 0) // 读取出现异常 46 { 47 if(errno == EAGAIN) // 如果是假错就推到 读态,重新读一次 48 fsm->state = STATE_R; 49 else // 如果是真错就推到 异常态 50 { 51 fsm->errstr = "read()"; 52 fsm->state = STATE_Ex; 53 } 54 } 55 else // 成功读取到了数据,将状态机推到 写态 56 { 57 fsm->pos = 0; 58 fsm->state = STATE_W; 59 } 60 break; 61 62 case STATE_W: // 写态 63 ret = write(fsm->dfd,fsm->buf+fsm->pos,fsm->len); 64 if(ret < 0) // 写入出现异常 65 { 66 if(errno == EAGAIN) // 如果是假错就再次推到 写态,重新再写入一次 67 fsm->state = STATE_W; 68 else // 如果是真错就推到 异常态 69 { 70 fsm->errstr = "write()"; 71 fsm->state = STATE_Ex; 72 } 73 } 74 else // 成功写入了数据 75 { 76 fsm->pos += ret; 77 fsm->len -= ret; 78 if(fsm->len == 0) // 如果将读到的数据完全写出去了就将状态机推向 读态,开始下一轮读取 79 fsm->state = STATE_R; 80 else // 如果没有将读到的数据完全写出去,那么状态机依然推到 写态,下次继续写入没写完的数据,实现“坚持写够 n 个字节” 81 fsm->state = STATE_W; 82 } 83 84 break; 85 86 case STATE_Ex: // 异常态,打印异常并将状态机推到 T态 87 perror(fsm->errstr); 88 fsm->state = STATE_T; 89 break; 90 91 case STATE_T: // 结束态,在这个例子中结束态没有什么需要做的事情,所以空着 92 /*do sth */ 93 break; 94 default: // 程序很可能发生了溢出等不可预料的情况,为了避免异常扩大直接自杀 95 abort(); 96 } 97 98 } 99 100 /* 推动状态机 */ 101 static void relay(int fd1,int fd2) 102 { 103 int fd1_save,fd2_save; 104 // 因为是读 tty1 写 tty2;读 tty2 写 tty1,所以这里的两个状态机直接取名为 fsm12 和 fsm21 105 struct fsm_st fsm12,fsm21; 106 107 fd1_save = fcntl(fd1,F_GETFL); 108 // 使用状态机操作 IO 一般都采用非阻塞的形式,避免状态机被阻塞 109 fcntl(fd1,F_SETFL,fd1_save|O_NONBLOCK); 110 fd2_save = fcntl(fd2,F_GETFL); 111 fcntl(fd2,F_SETFL,fd2_save|O_NONBLOCK); 112 113 // 在启动状态机之前将状态机推向 读态 114 fsm12.state = STATE_R; 115 // 设置状态机中读写的来源和目标,这样状态机的读写接口就统一了。在状态机里面不用管到底是 读tty1 写tty2 还是 读tty2 写tty1 了,它只需要知道是 读src 写des 就可以了。 116 fsm12.sfd = fd1; 117 fsm12.dfd = fd2; 118 119 // 同上 120 fsm21.state = STATE_R; 121 fsm21.sfd = fd2; 122 fsm21.dfd = fd1; 123 124 125 // 开始推状态机,只要不是 T态 就一直推 126 while(fsm12.state != STATE_T || fsm21.state != STATE_T) 127 { 128 // 调用状态机驱动函数,状态机开始工作 129 fsm_driver(&fsm12); 130 fsm_driver(&fsm21); 131 } 132 133 fcntl(fd1,F_SETFL,fd1_save); 134 fcntl(fd2,F_SETFL,fd2_save); 135 136 } 137 138 int main() 139 { 140 int fd1,fd2; 141 142 // 假设这里忘记将设备 tty1 以非阻塞的形式打开也没关系,因为推动状态机之前会重新设定文件描述符为非阻塞形式 143 fd1 = open(TTY1,O_RDWR); 144 if(fd1 < 0) 145 { 146 perror("open()"); 147 exit(1); 148 } 149 write(fd1,"TTY1\n",5); 150 151 fd2 = open(TTY2,O_RDWR|O_NONBLOCK); 152 if(fd2 < 0) 153 { 154 perror("open()"); 155 exit(1); 156 } 157 write(fd2,"TTY2\n",5); 158 159 160 relay(fd1,fd2); 161 162 163 close(fd1); 164 close(fd2); 165 166 167 exit(0); 168 }
大家先把这段代码读明白,下面我们还要用这段代码来修改示例。
如果只看上面的代码是很难理解程序是做什么的,因为都是一组一组的 case 语句,不容易理解。所以一般使用有限状态机开发的程序都会与图或相关的文档配套发行,看了图再结合代码就很容易看出来代码的目的了。
大家要对比着上面的图来看代码,这样思路就很清晰了。
使用状态机之前需要使两个待进行数据中继的文件描述符必须都是 O_NONBLOCK 的。
整个状态机中都没有使用循环来读写数据,因为状态机能确保每一种状态都是职责单一的,出现其它的任何状况的时候只要推动状态机问题就可以解决了。
所以这样的程序可维护性是不是高了很多?如果出现了需求变更,只需要简单的修改几条 case 语句就可以了,而不需要大段大段的修改代码了。
大家要多使用状态机的设计思想来写程序才能加深对这种设计思想的掌握程度。
3. I/O 多路转接
上面那个 读tty11 写tty12,读tty12 写tty11 的栗子是采用忙等的方式实现的,I/O 多路转接这个小节讨论的就是怎么把上面那个栗子修改为非忙等的模式。
有些时候就是这样的,读取多个文件(一般是设备)的时候不能使用阻塞方式,因为一个阻塞了其它的就没法读了;而非阻塞方式如果采用忙等的形式又得不偿失。你想想比如 telnet 服务在接收用户的命令的时候是不是这种情况呢?
对于处理这样的需求,Linux 系统为我们提供了 3 种方案:select(2)、poll(2) 和 epoll(7),这些方案提供的函数可以同时监视多个文件描述符,当它们的状态没有变化时阻塞等待,当它们的状态发生变化时会给我们一个通知让我们继续处理任务,下面我们一个一个的介绍它们。
先来看第一个函数:select(2)
1 select, FD_CLR, FD_ISSET, FD_SET, FD_ZERO - synchronous I/O multiplexing 2 3 /* According to POSIX.1-2001 */ 4 #include <sys/select.h> 5 6 /* According to earlier standards */ 7 #include <sys/time.h> 8 #include <sys/types.h> 9 #include <unistd.h> 10 11 int select(int nfds, fd_set *readfds, fd_set *writefds, 12 fd_set *exceptfds, struct timeval *timeout); 13 14 void FD_CLR(int fd, fd_set *set); 15 int FD_ISSET(int fd, fd_set *set); 16 void FD_SET(int fd, fd_set *set); 17 void FD_ZERO(fd_set *set);
select(2) 的优点是足够老,各个平台都支持它,这也是它相对于 poll(2) 唯一的优点。
参数列表:
nfds:最大的文件描述符 + 1;
readfds:需要监视的输入文件描述符集合;
writefds:需要监视的输出文件描述符集合;
exceptfds:需要监视的会发生异常的文件描述符集合;
timeout:等待的超时时间,如果时间超时依然没有文件描述符状态发生变化那么就返回。设置为 0 会立即返回,设置为 NULL 则一直阻塞等待,不会超时。
还记得我们之前提到过使用 select(2) 函数替代 sleep(3) 函数吗?记不起来的童鞋自己回去翻看前面的博文吧,这里不再赘述了。
我们看到参数中的文件描述符集合是 fd_set 类型的,那么怎么把我们的 int 类型的文件描述符添加到 fd_set 当中去呢?
通过带参数的宏 FD_CLR 就可以将文件描述符 fd 添加到 set 中了。
带参数的宏 FD_ZERO 的作用是清空 set 中的文件描述符。
带参数的宏 FD_ISSET 的作用是测试文件描述符 fd 是否在 set 集合中。
下面我们重构上面的栗子,通过把它修改成非忙等的形式来看看 select 是如何使用的。代码没有太大的区别,所以只贴出有差异的部分。
1 enum 2 { 3 STATE_R=1, 4 STATE_W, 5 STATE_AUTO, // 添加这个值是为了起到分水岭的作用,小于这个值的时候才需要使用 select(2) 监视 6 STATE_Ex, 7 STATE_T 8 }; 9 10 static int max(int a,int b) 11 { 12 if(a < b) 13 return b; 14 return a; 15 } 16 17 static void relay(int fd1,int fd2) 18 { 19 int fd1_save,fd2_save; 20 struct fsm_st fsm12,fsm21; 21 fd_set rset,wset; // 读写文件描述符集合 22 23 fd1_save = fcntl(fd1,F_GETFL); 24 fcntl(fd1,F_SETFL,fd1_save|O_NONBLOCK); 25 fd2_save = fcntl(fd2,F_GETFL); 26 fcntl(fd2,F_SETFL,fd2_save|O_NONBLOCK); 27 28 fsm12.state = STATE_R; 29 fsm12.sfd = fd1; 30 fsm12.dfd = fd2; 31 32 fsm21.state = STATE_R; 33 fsm21.sfd = fd2; 34 fsm21.dfd = fd1; 35 36 37 while(fsm12.state != STATE_T || fsm21.state != STATE_T) 38 { 39 //布置监视任务 40 FD_ZERO(&rset); 41 FD_ZERO(&wset); 42 43 // 读态监视输入文件描述符;写态监视输出文件描述符 44 if(fsm12.state == STATE_R) 45 FD_SET(fsm12.sfd,&rset); 46 if(fsm12.state == STATE_W) 47 FD_SET(fsm12.dfd,&wset); 48 if(fsm21.state == STATE_R) 49 FD_SET(fsm21.sfd,&rset); 50 if(fsm21.state == STATE_W) 51 FD_SET(fsm21.dfd,&wset); 52 53 if(fsm12.state < STATE_AUTO || fsm21.state < STATE_AUTO) 54 { 55 // 以阻塞形式监视 56 if(select(max(fd1,fd2)+1,&rset,&wset,NULL,NULL) < 0) 57 { 58 if(errno == EINTR) 59 continue; 60 perror("select()"); 61 exit(1); 62 } 63 } 64 65 //查看监视结果 66 if( FD_ISSET(fd1,&rset) || FD_ISSET(fd2,&wset) || fsm12.state > STATE_AUTO) 67 fsm_driver(&fsm12); 68 if( FD_ISSET(fd2,&rset) || FD_ISSET(fd1,&wset) || fsm21.state > STATE_AUTO) 69 fsm_driver(&fsm21); 70 } 71 72 fcntl(fd1,F_SETFL,fd1_save); 73 fcntl(fd2,F_SETFL,fd2_save); 74 75 }
在上面的栗子中,无论设备中是否有数据供我们读取我们都不停的推动状态机,所以导致出现了忙等的现象。
而在这个栗子中,我们在推状态机之前使用 select(2) 函数对文件描述符进行监视,如果文件描述状态没有发生变化就阻塞等待;而哪个状态机的文件描述符发生了变化就推动哪个状态机,这样就将查询法的实现改为通知法的实现了。是不是很简单呢?
poll(2) 出现的时间没有 select(2) 那么悠久,所以在可移植性上来说没有 select(2) 函数那么好,但是绝大多数主流 *nix 平台都支持 poll(2) 函数,它比 select(2) 要优秀很多,下面我们来了解下它。
1 poll - wait for some event on a file descriptor 2 3 #include <poll.h> 4 5 int poll(struct pollfd *fds, nfds_t nfds, int timeout); 6 7 struct pollfd { 8 int fd; /* 需要监视的文件描述符 */ 9 short events; /* 要监视的事件 */ 10 short revents; /* 该文件描述符发生了的事件 */ 11 };
参数列表:
fds:实际上是一个数组的首地址,因为 poll(2) 可以帮助我们监视多个文件描述符,而一个文件描述放到一个 struct pollfd 结构体中,多个文件描述符就需要一个数组来存储了。
nfds:fds 这个数组的长度。在参数列表中使用数组首地址 + 长度的做法还是比较常见的。
timeout:阻塞等待的超时时间。传入 -1 则始终阻塞,不超时。
结构体中的事件可以指定下面七种事件,同时监视多个事件可以使用按位或(|)添加:
| 事件 | 描述 |
| POLLIN | 文件描述符可读 |
| POLLPRI | 可以非阻塞的读高优先级的数据 |
| POLLOUT | 文件描述符可写 |
| POLLRDHUP | 流式套接字连接点关闭,或者关闭写半连接。 |
| POLLERR | 已出错 |
| POLLHUP | 已挂断(一般指设备) |
| POLLNVAL | 参数非法 |
表1 poll(2) 可以监视的 7 种事件
使用 poll(2) 的步骤也很简单:
1)首先通过 struct pollfd 结构体中的 events 成员布置监视任务;
2)然后使用 poll(2) 函数进行阻塞的监视;
3)当从 poll(2) 函数返回时就可以通过 struct polfd 结构体中的 revents 成员与上面的 7 个宏中被我们选出来监视的宏进行按位与(&)操作了,只要结果不为 1 就认为触发了该事件。
好了,这 3 步就是 poll(2) 函数的使用方法,简单吧。
下面我们修改一下上面的栗子,把上面用 select(2) 实现的部分修改为用 poll(2) 来实现。没有改过的地方就不贴出来了,其实也只有 relay() 函数被修改了。
1 static void relay(int fd1,int fd2) 2 { 3 int fd1_save,fd2_save; 4 struct fsm_st fsm12,fsm21; 5 struct pollfd pfd[2]; // 一共监视两个文件描述符 6 7 8 fd1_save = fcntl(fd1,F_GETFL); 9 fcntl(fd1,F_SETFL,fd1_save|O_NONBLOCK); 10 fd2_save = fcntl(fd2,F_GETFL); 11 fcntl(fd2,F_SETFL,fd2_save|O_NONBLOCK); 12 13 fsm12.state = STATE_R; 14 fsm12.sfd = fd1; 15 fsm12.dfd = fd2; 16 17 fsm21.state = STATE_R; 18 fsm21.sfd = fd2; 19 fsm21.dfd = fd1; 20 21 pfd[0].fd = fd1; 22 pfd[1].fd = fd2; 23 24 while(fsm12.state != STATE_T || fsm21.state != STATE_T) 25 { 26 // 布置监视任务 27 pfd[0].events = 0; 28 if(fsm12.state == STATE_R) 29 pfd[0].events |= POLLIN; // 第一个文件描述符可读 30 if(fsm21.state == STATE_W) 31 pfd[0].events |= POLLOUT; // 第一个文件描述符可写 32 33 pfd[1].events = 0; 34 if(fsm12.state == STATE_W) 35 pfd[1].events |= POLLOUT; // 第二个文件描述符可读 36 if(fsm21.state == STATE_R) 37 pfd[1].events |= POLLIN; // 第二个文件描述符可写 38 39 // 只要是可读写状态就进行监视 40 if(fsm12.state < STATE_AUTO || fsm21.state < STATE_AUTO) 41 { 42 // 阻塞监视 43 while(poll(pfd,2,-1) < 0) 44 { 45 if(errno == EINTR) 46 continue; 47 perror("poll()"); 48 exit(1); 49 } 50 } 51 52 // 查看监视结果 53 if( pfd[0].revents & POLLIN || 54 pfd[1].revents & POLLOUT || 55 fsm12.state > STATE_AUTO) 56 fsm_driver(&fsm12); // 推状态机 57 if( pfd[1].revents & POLLIN || 58 pfd[0].revents & POLLOUT || 59 fsm21.state > STATE_AUTO) 60 fsm_driver(&fsm21); // 推状态机 61 } 62 63 fcntl(fd1,F_SETFL,fd1_save); 64 fcntl(fd2,F_SETFL,fd2_save); 65 66 }
代码中注释写得很明确了,相信不需要 LZ 再解释什么了。
epoll(7) 不是一个函数,它在 man 手册的第 7 章里,它是 Linux 为我们提供的“加强版 poll(2)”,既然是加强版,那么一定有超越 poll(2) 的地方,下面就聊一聊 epoll(7)。
在使用 poll(2) 的时候用户需要管理一个 struct pollfd 结构体或它的结构体数组,epoll(7) 则使内核为我们管理了这个结构体数组,我们只需要通过 epoll_create(2) 返回的标识引用这个结构体即可。
1 epoll_create - open an epoll file descriptor 2 3 #include <sys/epoll.h> 4 5 int epoll_create(int size);
调用 epoll_create(2) 时最初 size 参数给传入多少,kernel 在建立数组的时候就是多少个元素。但是这种方式不好用,所以后来改进了,只要 size 随便传入一个正整数就可以了,内核不会再根据大家传入的 size 直接作为数组的长度了,因为内核是使用 hash 来管理要监视的文件描述符的。
返回值是 epfd,从这里也可以体现出 Linux 一切皆文件的设计思想。失败时返回 -1 并设置 errno。
得到了内核为我们管理的结构体数组标识之后,接下来就可以用 epoll_ctl(2) 函数布置监视任务了。
1 epoll_ctl - control interface for an epoll descriptor 2 3 #include <sys/epoll.h> 4 5 int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); 6 7 8 struct epoll_event { 9 uint32_t events; /* Epoll 监视的事件,这些事件与 poll(2) 能监视的事件差不多,只是宏名前面加了个E */ 10 epoll_data_t data; /* 用户数据,除了能保存文件描述符以外,还能让你保存一些其它有关数据,比如你这个文件描述符是嵌在一棵树上的,你在使用它的时候不知道它是树的哪个节点,则可以在布置监视任务的时候将相关的位置都保存下来。这个联合体成员就是 epoll 设计的精髓。 */ 11 };
epoll_ctl(2) 的作用是要对 fd 增加或减少(op) 什么行为的监视(event)。成功返回0,失败返回 -1 并设置 errno。
op 参数可以使用下面三个宏来指定操作:
| 宏 | 描述 |
| EPOLL_CTL_ADD | 增加要监视的文件描述符 |
| EPOLL_CTL_MOD | 更改目标文件描述符的事件 |
| EPOLL_CTL_DEL | 删除要监视的文件描述符,event 参数会被忽略,可以传入 NULL。 |
表2 epoll_ctl(2) 函数 op 参数的选项
与 select(2) 和 poll(2) 一样, 布置完监视任务之后需要取监视结果,epoll(7) 策略使用 epoll_wait(2) 函数进行阻塞监视并返回监视结果。
1 epoll_wait - wait for an I/O event on an epoll file descriptor 2 3 #include <sys/epoll.h> 4 5 int epoll_wait(int epfd, struct epoll_event *events, 6 int maxevents, int timeout);
参数列表:
epfd:要操作的 epoll 实例;
events + maxevents:共同指定了一个结构体数组,数组的起始位置和长度。其实每次使用 epoll_ctl(2) 函数添加一个文件描述符时相当于向内核为我们管理的数组中添加了一个成员,所以当我们使用同一个 struct epoll_event 变量操作多个文件描述符时,只需传入该变量的地址和操作了多少个文件描述符即可,大家看看下面的栗子就明白了。
timeout:超时等待的时间,设置为 -1 则始终阻塞监视,不超时。
跟上面的栗子一样,LZ 只贴出来被修改了的 relay() 函数,其它部分不变。
1 static void relay(int fd1,int fd2) 2 { 3 int fd1_save,fd2_save; 4 struct fsm_st fsm12,fsm21; 5 int epfd; 6 struct epoll_event ev; 7 8 epfd = epoll_create(10); 9 if(epfd < 0) 10 { 11 perror("epfd()"); 12 exit(1); 13 } 14 15 fd1_save = fcntl(fd1,F_GETFL); 16 fcntl(fd1,F_SETFL,fd1_save|O_NONBLOCK); 17 fd2_save = fcntl(fd2,F_GETFL); 18 fcntl(fd2,F_SETFL,fd2_save|O_NONBLOCK); 19 20 fsm12.state = STATE_R; 21 fsm12.sfd = fd1; 22 fsm12.dfd = fd2; 23 24 fsm21.state = STATE_R; 25 fsm21.sfd = fd2; 26 fsm21.dfd = fd1; 27 28 ev.events = 0; 29 ev.data.fd = fd1; 30 epoll_ctl(epfd,EPOLL_CTL_ADD,fd1,&ev); 31 32 ev.events = 0; 33 ev.data.fd = fd2; 34 epoll_ctl(epfd,EPOLL_CTL_ADD,fd2,&ev); 35 36 37 while(fsm12.state != STATE_T || fsm21.state != STATE_T) 38 { 39 // 布置监视任务 40 41 ev.events = 0; 42 ev.data.fd = fd1; 43 if(fsm12.state == STATE_R) 44 ev.events |= EPOLLIN; 45 if(fsm21.state == STATE_W) 46 ev.events |= EPOLLOUT; 47 epoll_ctl(epfd,EPOLL_CTL_MOD,fd1,&ev); 48 49 ev.events = 0; 50 ev.data.fd = fd2; 51 if(fsm12.state == STATE_W) 52 ev.events |= EPOLLOUT; 53 if(fsm21.state == STATE_R) 54 ev.events |= EPOLLIN; 55 epoll_ctl(epfd,EPOLL_CTL_MOD,fd2,&ev); 56 57 // 监视 58 if(fsm12.state < STATE_AUTO || fsm21.state < STATE_AUTO) 59 { 60 while(epoll_wait(epfd,&ev,1,-1) < 0) 61 { 62 if(errno == EINTR) 63 continue; 64 perror("epoll_wait()"); 65 exit(1); 66 } 67 } 68 69 // 查看监视结果 70 if( ev.data.fd == fd1 && ev.events & EPOLLIN || 71 ev.data.fd == fd2 && ev.events & EPOLLOUT || 72 fsm12.state > STATE_AUTO) 73 fsm_driver(&fsm12); 74 if( ev.data.fd == fd2 && ev.events & EPOLLIN || 75 ev.data.fd == fd1 && ev.events & EPOLLOUT || 76 fsm21.state > STATE_AUTO) 77 fsm_driver(&fsm21); 78 } 79 80 fcntl(fd1,F_SETFL,fd1_save); 81 fcntl(fd2,F_SETFL,fd2_save); 82 83 close(epfd); 84 85 }
4.记录锁
记录锁就是用 fcntl(2) 函数创建一个锁文件,比较麻烦,感兴趣的童鞋可以自己看看书上的介绍,在这里 LZ 就不做介绍了,我们在最后会讨论两个方便的文件锁和锁文件。
5.异步 I/O
这部分主要是说信号驱动 IO,不是真正意义上的异步 IO。
异步 I/O 分为 System V 异步 I/O 和 BSD 异步 I/O,Linux 模仿的是后者,这里我们不过多讨论了,后面 LZ 在讨论内核的博文中会继续讨论异步。
6. readv(2) 和 write(2)
1 readv, writev - read or write data into multiple buffers 2 3 #include <sys/uio.h> 4 5 ssize_t readv(int fd, const struct iovec *iov, int iovcnt); 6 7 ssize_t writev(int fd, const struct iovec *iov, int iovcnt); 8 9 struct iovec { 10 void *iov_base; /* 起始地址 */ 11 size_t iov_len; /* Number of bytes to transfer */ 12 };
这两个函数的作用就是对多个碎片的读写操作,将所有的小碎片写到文件中。
readv(2) 当没有连续的空间存储从 fd 读取或写入的数据时,将其存储在 iovcnt 个 iov 结构体中,writev(2) 的作用相同。iov 是结构体数组起始位置,iovcnt 是数组长度。
7. readn() 和 writen()
这两个函数可以从本书(《APUE》第三版)的光盘中找,它们并不是什么标准库的函数,也不是系统调用,只是本书作者自己封装的函数,算是方言中的方言,作用是坚持写够 n 个字节,之前我们在讨论 IO 的博文中实现过类似的效果。
对了,天朝在引入这本书的时候貌似没有引入配套光盘,需要的童鞋可以自己去网上搜索一下。
7.存储映射 I/O
存储映射 I/O 是十四章的小重点。
在 *nix 系统中分配内存的方法有好几种,不一定非得使用 free(3) 函数。
通过 mmap(2) 和 unmap(2) 函数可以实现一个实时的类似于 malloc(3) 和 free(3) 函数的效果,我们在前面的博文中提到过,malloc(3) 和 free(3) 实际上是以打白条的形式实现的,就是在你调用函数的时候并没有立即分配内存给你,而是在你真正使用内存的时候才分配给你的。
存储映射I/O说的就是将一个文件的一部分或全部映射到内存中,用户拿到的就是这段内存的起始位置,访问这个文件就相当于访问一个大字符串一样。
1 mmap, munmap - map or unmap files or devices into memory 2 3 #include <sys/mman.h> 4 5 void *mmap(void *addr, size_t length, int prot, int flags, 6 int fd, off_t offset); 7 int munmap(void *addr, size_t length);
mmap(2) 函数的作用是把 fd 这个文件从 offset 偏移位置开始把 length 字节个长度映射到 addr 这个内存位置上,如果 addr 参数传入 NULL 则由 kernel 帮我们选择一块空间并使用返回值返回这段内存的首地址。
prot 参数是操作权限,可以使用下表中的宏通过按位或(|)来组合指定。
| 宏 | 含义 |
| PROT_READ | 映射区可读 |
| PROT_WRITE | 映射区可写 |
| PROT_EXEC | 映射区可执行 |
| PROT_NONE | 映射区不可访问 |
表3 mmap(2) 函数的 prot 参数可选项
映射区不可访问(PROT_NONE)的含义是如果我映射的内存中有一块已经有某些数据了,绝对不能让我的程序越界覆盖了,就可以把这段空间设置为映射区不可访问。
flags 参数是特殊要求,以下二者必选其一:
| 宏 | 含义 |
| MAP_SHARED | 对映射区进行存储操作相当于对原来的文件进行写入,会改变原来文件的内容。 |
| MAP_PRIVATE | 当对映射区域进行存储操作时会创建一个私有副本,所有后来再对映射区的操作都相当于操作这个副本,而不影响原来的文件。 |
表4 mmap(2) 函数的 flags 参数可选项
其它常用选项:
MAP_ANONYMOUS:不依赖于任何文件,映射出来的内存空间会被清 0,并且 fd 和 offset 参数会被忽略,通常我们在使用的时候会把 fd 设置为 -1。
用这个参数可以很容易的做出一个最简单最好用的在具有亲缘关系的进程之间的共享内存,比后面第15章我们要讨论的共享内存还好用。后面 LZ 会给出一个小栗子让大家看看这种方式如何使用。
mmap(2) 在成功的时候返回一个指针,会指向映射的内存区域的起始地址。失败时返回 MAP_FAILED 宏定义,其实是这样定义的:(void *) -1。
首先我们写一个栗子看看如何把一个文件映射到内存中访问。
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <sys/mman.h> 4 #include <sys/types.h> 5 #include <sys/stat.h> 6 #include <unistd.h> 7 #include <fcntl.h> 8 9 10 #define FNAME "/etc/services" 11 12 int main(void) 13 { 14 int fd,i; 15 char *str; 16 struct stat statres; 17 int count = 0; 18 19 fd = open(FNAME,O_RDONLY); 20 if(fd < 0) 21 { 22 perror("open()"); 23 exit(1); 24 } 25 26 // 通过 stat(2) 获得文件大小 27 if(fstat(fd,&statres) < 0) 28 { 29 perror("fstat()"); 30 exit(1); 31 } 32 33 str = mmap(NULL,statres.st_size,PROT_READ,MAP_SHARED,fd,0); 34 if(str == MAP_FAILED) 35 { 36 perror("mmap()"); 37 exit(1); 38 } 39 40 // 将文件映射到内存之后文件描述符就可以关闭了,直接访问映射的内存就相当于访问文件了。 41 close(fd); 42 43 for(i = 0 ; i < statres.st_size; i++) { 44 // 因为访问的是文本文件,所以可以把映射的内存看作是一个大字符串处理 45 if(str[i] == ‘a‘) { 46 count++; 47 } 48 } 49 50 printf("count = %d\n",count); 51 52 // 用完了别忘了解除映射,不然会造成内存泄漏! 53 munmap(str,statres.st_size); 54 55 exit(0); 56 }
这段代码会统计 /etc/services 文件中包含多少个字符 ‘a‘。
mmap(2) 的返回值是 void* 类型的,这是一种百搭的类型,在映射了不同的东西的情况下我们可以使用不同的指针来接收,这样就能用不同的方式访问这段内存空间了。上面这个文件是文本文件,所以我们可以使用 char* 来接收它的返回值,这样就将整个文件看作是一个大字符串来访问了。
这个还是比较常规的用法,下面我们看一下如何使用 mmap(2) 函数制作一个好用的共享内存。
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <sys/mman.h> 4 #include <sys/types.h> 5 #include <sys/stat.h> 6 #include <unistd.h> 7 #include <fcntl.h> 8 #include <string.h> 9 #include <wait.h> 10 11 #define MEMSIZE 1024 12 13 int main(void) 14 { 15 char *str; 16 pid_t pid; 17 18 // 这里在 flags 中添加 MAP_ANONYMOUS,为制作共享内存做准备 19 str = mmap(NULL,MEMSIZE,PROT_READ|PROT_WRITE,MAP_SHARED|MAP_ANONYMOUS,-1,0); 20 if(str == MAP_FAILED) 21 { 22 perror("mmap()"); 23 exit(1); 24 } 25 26 // 创建子进程,父子进程使用共享内存进行通信 27 pid = fork(); 28 if(pid < 0) 29 { 30 perror("fork()"); 31 exit(1); 32 } 33 if(pid == 0) // 子进程向共享内存中写入数据 34 { 35 strcpy(str,"Hello!"); 36 munmap(str,MEMSIZE); // 注意,虽然共享内存是在 fork(2) 之前创建的,但是 fork(2) 的时候子进程也拷贝了一份,所以子进程使用完毕之后也要解除映射 37 exit(0); 38 } 39 else // 父进程从共享内存中读取子进程写入的数据 40 { 41 wait(NULL); // 保障子进程先运行起来,因为就算父进程先运行了也会在这里阻塞等待 42 puts(str); // 把从共享内存中读取出来的数据打印出来 43 munmap(str,MEMSIZE); // 不要忘记解除映射 44 exit(0); 45 } 46 47 48 exit(0); 49 }
共享内存是进程间通信的一种手段,就是在内存中开辟一块空间让多个进程之间可以共同访问这段空间,从而实现进程之间的数据交换。在后面讨论 IPC 的博文中我们还会详细介绍共享内存,不过用 mmap(2) 制作的共享内存比后面介绍的共享内存使用起来更简便一些。
大家自己运行一下这段代码,可以看到父进程打印出了子进程写入的“Hello”字符串,说明这段内存确实是在父子进程之间共享的。
大家在使用的时候不要忘记父子进程最后都要做解除映射的动作。
从这个栗子中我们也可以看出来,这种共享内存的方式只适合在具有亲缘关系的进程之间使用,没有亲缘关系的进程是无法获得指向同一个映射内存空间的指针的。
8. flock(2) 和 lockf(3) 函数
1 lockf - apply, test or remove a POSIX lock on an open file 2 3 #include <unistd.h> 4 5 int lockf(int fd, int cmd, off_t len); 6 7 flock - apply or remove an advisory lock on an open file 8 9 #include <sys/file.h> 10 11 int flock(int fd, int operation);
这两个函数可以实现好用的文件加锁。
我们这里只介绍 lockf(2) 函数,flock(2) 函数也差不多,都很简单,所以大家可以自己去查阅 man 手册。
lockf(3) 可以给文件进行局部加锁,简单来说就是从当前位置锁住 len 个字节。
参数列表:
fd:要加锁的文件描述符;
cmd:具体的命令见下表;
| 宏 | 说明 |
| F_LOCK |
为文件的一段加锁,如果已经被加锁就阻塞等待,如果两个锁要锁定的部分有交集就会被合并 ,文件关闭时或进程退出时会自动释放,不会被子进程继承。 |
| F_TLOCK | 与 F_LOCK 差不多,不过是尝试加锁,非阻塞。 |
| F_ULOCK | 解锁,如果是被合并的锁会分裂。 |
| F_TEST |
测试锁,如果文件中被测试的部分没有锁定或者是调用进程持有锁就返回 0; 如果是其它进程持有锁就返回 -1,并且 errno 设置为 EAGAIN 或 EACCES。 |
图5 lockf(3) 函数的 cmd 参数可选值
len:要锁定的长度,如果为 0 表示文件有多长锁多长,从当前位置一直锁到文件结尾。
下面我们使用 lockf(3) 函数写一个栗子。
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <string.h> 4 #include <unistd.h> 5 #include <wait.h> 6 #include <sys/types.h> 7 8 9 #define PROCNUM 20 10 #define FNAME "/tmp/out" 11 #define BUFSIZE 1024 12 13 14 static void func_add() 15 { 16 FILE *fp; 17 int fd; 18 char buf[BUFSIZE]; 19 20 fp = fopen(FNAME,"r+"); 21 if(fp == NULL) 22 { 23 perror("fopen()"); 24 exit(1); 25 } 26 27 fd = fileno(fp); 28 if(fd < 0) 29 { 30 perror("fd"); 31 exit(1); 32 } 33 34 // 使用之前先锁定 35 lockf(fd,F_LOCK,0); 36 37 fgets(buf,BUFSIZE,fp); 38 rewind(fp); // 把文件位置指针定位到文件首 39 sleep(1); // 放大竞争 40 fprintf(fp,"%d\n",atoi(buf)+1); 41 fflush(fp); 42 43 // 使用之后释放锁 44 lockf(fd,F_ULOCK,0); 45 46 fclose(fp); 47 48 return ; 49 } 50 51 int main(void) 52 { 53 int i; 54 pid_t pid; 55 56 for(i = 0 ; i < PROCNUM ; i++) 57 { 58 pid = fork(); 59 if(pid < 0) 60 { 61 perror("fork()"); 62 exit(1); 63 } 64 if(pid == 0) // child 65 { 66 func_add(); 67 exit(0); 68 } 69 } 70 71 for(i = 0 ; i < PROCNUM ; i++) 72 wait(NULL); 73 74 75 exit(0); 76 }
还是用我么以前的栗子改的,大家还记得以前写过一个栗子,让 20 个进程同时向 1 个文件中累加数字吗。
在这里每个进程在读写文件之前先加锁,如果加不上就等待别人释放锁再加。如果加上了锁就读出文件中当前的值,+1 之后再写回到文件中。
获得锁之后 sleep(1) 是为了放大竞争,让进程之间一定要出现竞争的现象,便于我们分析调试。
在调试并发的程序时,如果有些问题很难复现,那么可以通过加长每一个并发单位的执行时间来强制它们出现竞争的情况,这样可以让我们更容易的分析问题。
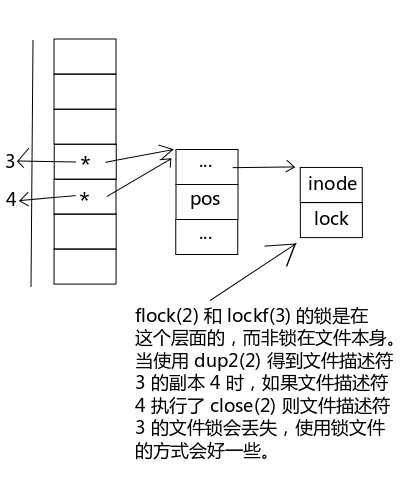
图3 flock(2) 和 lockf(3) 的缺点
文件锁还有一个机制是把一个文件当作锁,比如要操作的是 /tmp/out 文件,那么父进程可以先创建一个 /tmp/lcok文件,然后再创建 20 个子进程同时对 /tmp/out 文件进行读写,但是子进程必须先锁定 /tmp/lock 文件才能操作 /tmp/out 文件,没抢到锁文件的需要等待其它进程解锁再抢锁,等父进程为所有的子进程收尸之后再关闭/tmp/lock,/tmp/lock 这个文件就被称为锁文件。
高级 IO 部分大概就这些内容了,有什么疑问欢迎大家在评论中讨论。
(十一) 一起学 Unix 环境高级编程 (APUE) 之 高级 IO
标签:
原文地址:http://www.cnblogs.com/chuyuhuashi/p/4468610.html