标签:style class blog code http color
前言
本文的目的很明确:介绍如何将二维数组传递进显存,以及如何将二维数组从显存传递回主机端。
实现步骤
1. 在显存中为二维数组开辟空间
2. 获取该二维数组在显存中的 pitch 值 (cudaMallocPitch 实现)
3. 将二维数组传递进显存 (cudaMemcpy2D 实现)
4. 在显存中对该二维数组进行处理 (目前必须按照 1 维数组的规则进行处理)
5. 将结果传递回内存 (cudaMemcpy2D实现)
重要概念 - pitch
对于内存的存取来说,对准偏移量为2的幂(现在一般要求2^4=16)的地址能获取更快的速度,而如果不对齐,可能你需要的数据需要更多的存取次数才能得到。
为了满足这个条件,对于一个二维数组来说(行优先row major),就希望每一行的开头都满足“对齐”。如果一行的长度不规整,导致下一行开头不在指定的位置,就需要在每一行末尾进行填充(padding),从而使得每一行都对齐,这和BMP格式的像素存储是一个道理。
pitch就是指每一行的字节数 + padding的字节数 。
使用 cudaMemcpy2D 的目的仅是为了利用 pitch 机制提升二维数组中元素的访问速度。事实上二维数组传递进显存后,还是得按照一维数组的规范去处理该二维矩阵。global 函数中目前不支持多下标访问,好坑。。
代码示例
1 #include "cuda.h" 2 #include "cuda_runtime.h" 3 4 #include <iostream> 5 6 using namespace std; 7 8 // 定义测试二维数组的行列数 9 const int R = 5; 10 const int C = 10; 11 12 int main() 13 { 14 // 定义一个用于测试的二维数组,其每个元素都赋值为0,并将其打印出来。 15 int array2D[R][C]; 16 cout << "传输前的测试矩阵:" << endl; 17 for (int i=0; i<R; i++) { 18 for (int j=0; j<C; j++) { 19 array2D[i][j] = 0; 20 cout << array2D[i][j] << " "; 21 } 22 cout << endl; 23 } 24 25 // 再定义另一个同样大小的二维数组用于获取从显存传回的结果 26 int result[R][C]; 27 cout << "传输前的结果矩阵:" << endl; 28 for (int i=0; i<R; i++) { 29 for (int j=0; j<C; j++) { 30 result[i][j] = 1; 31 cout << result[i][j] << " "; 32 } 33 cout << endl; 34 } 35 36 // 为此二维数组在显存中分配内存 37 int *d_array2D; 38 cudaMalloc ((void**)&d_array2D, sizeof(int)*R*C); 39 40 // 获取显存中的二维数组的 pitch 值 41 size_t d_pitch; 42 cudaMallocPitch ((void**) &d_array2D, &d_pitch, sizeof(int)*C, R); 43 44 // 将二维数组转移进显存 45 cudaMemcpy2D ( 46 d_array2D, // 目的地址 47 d_pitch, // 目的 pitch 48 array2D, // 源地址 49 sizeof(int)*C, // 源 pitch 50 sizeof(int)*C, // 数据拷贝宽度 51 R, // 数据拷贝高度 52 cudaMemcpyHostToDevice // 数据传递方向 53 ); 54 55 // 将二维数组从显存传输回主机端的结果矩阵中 56 cudaMemcpy2D ( 57 result, // 目的地址 58 sizeof(int)*C, // 目的 pitch 59 d_array2D, // 源地址 60 d_pitch, // 源 pitch 61 sizeof(int)*C, // 数据拷贝宽度 62 R, // 数据拷贝高度 63 cudaMemcpyDeviceToHost // 数据传递方向 64 ); 65 66 // 打印传回到结果矩阵的数据 67 cout << "从显存获取到测试矩阵后的结果矩阵:" << endl; 68 for (int i=0; i<R; i++) { 69 for (int j=0; j<C; j++) { 70 cout << result[i][j] << " "; 71 } 72 cout << endl; 73 } 74 75 cudaFree (d_array2D); 76 77 cin.get(); 78 79 return EXIT_SUCCESS; 80 }
运行测试
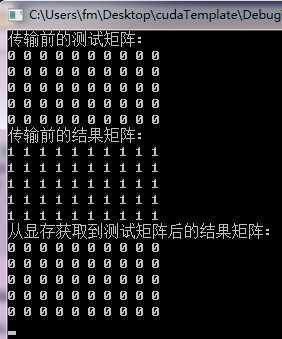
小结
本文介绍的仅仅是二维数组在两端之间的传输!当二维数组传递进了显存,在对其操作的过程中,是需要对其进行一个一维到二维的下标操作转换的,global 中不支持多下标访问。之所以加入 pitch 并使用 cudaMemcpy2D 只是为了提高元素的访问速度。
如果需要具体处理传递进入的二维数组,还要将 pitch 也作为参数传递进 kernel 函数,如下所示:
// 下面的 kernel 函数将二维数组的所有位置为 2 __global__ void kernelFun (int *d_array2D, int pitch) { for (int i=0; i<R; i++) { int *row = (int *)((char *)d_array2D+i*pitch); for (int j=0; j<C; j++) { row[j] = 2; } } return; }
二维数组的传输 (host <-> device),布布扣,bubuko.com
标签:style class blog code http color
原文地址:http://www.cnblogs.com/scut-fm/p/3787957.html