标签:
1.简介
Spark 是一个基于内存计算的开源的集群计算系统,目的是让数据分析更加快速,由加州大学伯克利分校 AMP 实验室 (Algorithms,Machines,and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。spark-sql还能提供比较完整的sql的功能,多表分析关联非常方便。
2.单机最简安装
tar -zxvf spark-1.3.0-bin-hadoop2.4.tgz
将解压后的文件移动到/opt/spark/目录下
/opt/spark/sbin:提供节点启停等脚本,方便日常操作
/opt/spark/bin:提供基本的命令脚本,sql、shell等工具
/opt/spark/lib:spark依赖的jar包
cd /opt/spark/sbin
启动master节点:./start-master.sh
启动worker节点:./start-slaves.sh
可以使用ie等浏览器连接master节点(假设master节点ip为192.168.20.56,则在ie地址栏中键入:192.168.20.56:8080),查看节点的执行情况
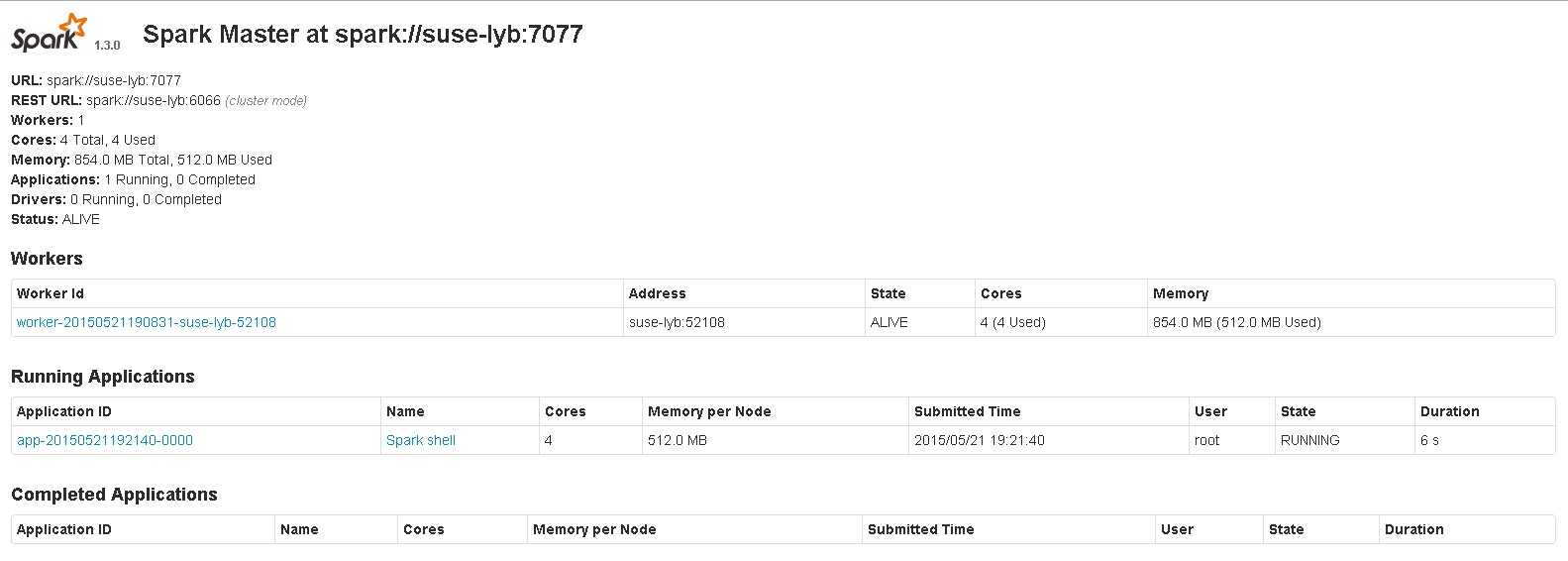
注:如果只是使用命令/opt/spark/bin/spark-shell启动,则不会连接master/worker,而只是spark-shell单独在执行。
/opt/spark/bin/spark-shell --master spark://suse-lyb:7077
执行成功后,可以在master的页面上看到Running Applications多了一个名为Spark shell的进程。
对本地文件进行简单的行数统计:
scala> val textFile = sc.textFile("/opt/spark/README.md")
scala> textFile.count()
res0: Long = 98
标签:
原文地址:http://www.cnblogs.com/linyoub/p/4520643.html