标签:
1、J48原理
基于从上到下的策略,递归的分治策略,选择某个属性放置在根节点,为每个可能的属性值产生一个分支,将实例分成多个子集,每个子集对应一个根节点的分支,然后在每个分支上递归地重复这个过程。当所有实例有相同的分类时,停止。
问题:如何选择根节点属性,建立分支呢?
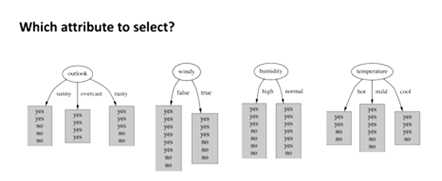
例如:weather.arff
我们希望得到的是纯分裂,即分裂为纯节点,希望找到一个属性,它的一个节点全是yes,一个节点全是no,或许第三个节点又全是yes,这是最好的情况,因为如果是混合节点则需要再次分裂。
通过量化来确定能产生最纯子节点的属性---计算纯度(目标是得到最小的决策树)。而自上而下的树归纳法用到了一些启发式方法---产生纯节点的启发法是以信息论为基础的,即信息熵,以bits测量信息。
信息增益=分裂前分布的信息熵-分裂后分布的信息熵,选择信息增益最大的属性。
![]() (分裂前分部信息熵)
(分裂前分部信息熵)
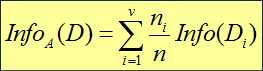 (分布后分布信息熵)
(分布后分布信息熵)
![]() (属性A的信息增益)
(属性A的信息增益)
计算这四个属性的信息增益,如下图:
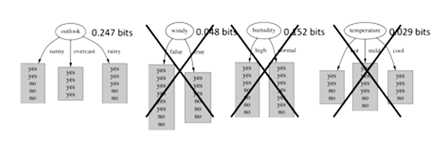
经过计算得到outlook、windy、humidity、temperature的信息增益分别为0.247bits、0.048bits、0.152bits、0.029bits,所以选择outlook为根节点。
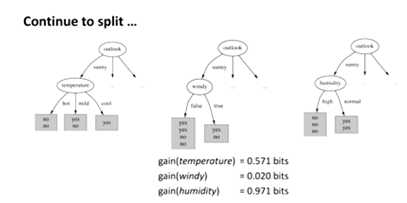
........
2、举例
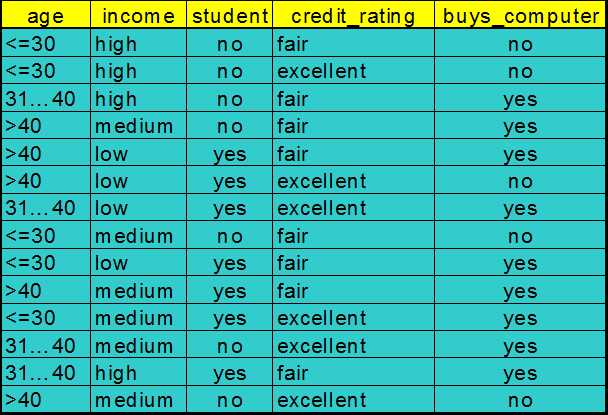
(1)所给数据如下图

(2)选择根节点
先求age的信息增益
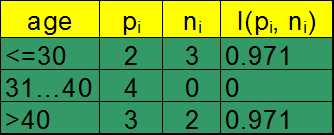
分裂前分布的信息熵:![]()
分裂后分布的信息熵:
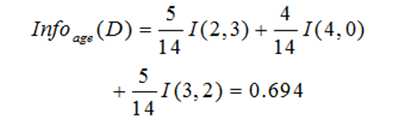
信息增益:
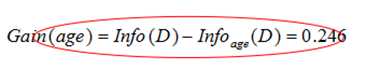
类似地:
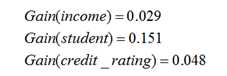
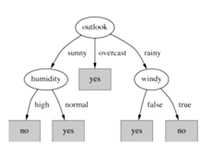
比较得到选择age为根节点,然后得到决策树的第一层,如下图:
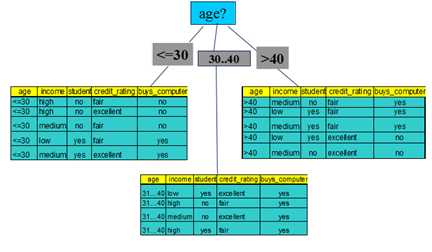
然后在每个分支上递归地重复这个过程,直到所有实例有相同的分类。
3、总结
J48分类算法可信度高,建立的决策树简单易懂,并且结果非常容易理解。
标签:
原文地址:http://www.cnblogs.com/chamie/p/4523976.html