标签:
今天太长姿势了,什么叫懂了也写不出代码说的不就是我吗,就那么几行代码居然叽叽歪歪写了一个小时。
首先exercise要实现的是softmax的cost function和gradient,如下图:
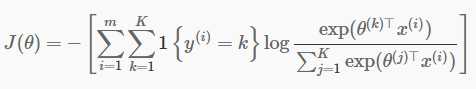 (1)
(1)
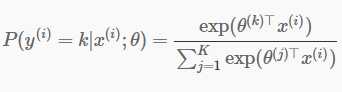 (2)
(2)
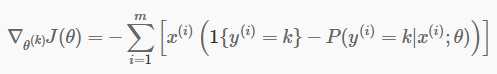 (3)
(3)
下面就来仔细分析怎么不借助for循环高效的实现上面三个函数。
首先P是一个关键,因为在J和梯度中都出现了,所以现在实现P。
可以看到theta和X的乘积是一个十分重要的量,因为在分子分母中都出现了,所以首先计算假设h=exp(θTX),那么h(k,i)就是exp(θ(k)T*x(i))的值了,实际就是计算样本i标签为k的概率,当然是没归一化的。这一句的代码十分简单(为何不支持matlab的代码?有种被歧视了的赶脚=。=):
h = exp(theta‘ * X);
此时要注意的一点是虽然有10个分类,但是通过ufldl的讲解我们知道有一个参数是多余的,更直观的理解就是如果得到了x(i)取前9类的概率,那么取第10类的概率直接用1减去前9类的概率和就得到了,所以theat矩阵是9行,而不是10行。我们得到的h也是9行,和公式里面K=10不一样,所以我们给h加上1行1,至于为什么是1,接下来就知道了。
h = [h;ones(1,m)];
接下来就可以计算P了,我们计算一个矩阵P,使得P(k,i)表示上述公式2的值。可以看到公式2里面的分子就是上面计算过的h(k,i)的值,而分母就是h的第i列的值相加。这里就可以借助bsxfun函数实现:
p = bsxfun(@rdivide,h,sum(h));
logp = log2(p);
bsxfun函数是一个十分高效的函数,上述第一个参数@rdivide表示对h中的每个值做“右除”除法,sum(h)就是上面分析出来的P的分母值,是一个行向量1*m(m是总样本数),即(sum(h))(i)表示h的第i列相加的值,这样bsxfun函数就会自动对h的每一行的每一个元素,都除以sum(h)这一个行向量的对应位置的值。
接下来就可以计算cost function J了。借助sub2ind这个函数实现。ufldl上有对这个函数的解释,这里大概总结以下:对于矩阵A,I=sub2ind(size(A), 1:size(A,1), y);执行后I中存放所有index为(1,y(1)),(2,y(2)),(3,y(3)),...(size(A,1),y(size(A,1)))的元素的index,所以A(I)就是这些元素实际的值了。对于cost function J,我们需要把logp中所有(k,i)位置上的值都拿出来,其中k是x(i)的ground truth的标签,所以我们可以这么写sub2ind函数:
index = sub2ind(size(logp),y,[1:m]);
再把index里面元素在logp中对应的值加起来就是cost function J了:
f = -sum(logp(index));
最后解释一下为什么要给h最后一行补1,我们知道如果h(10,i)接近1,说明分类器认为x(i)取第10类的概率大;如果h(10,i)接近0,说明x(i)分类器不太可能取第10类,如果是其他值,说明分类器“自信度”不高,我们不用考虑。我们只要考虑h(10,i)为1的情况,因为我们只要保证从logp中取(k,i)位置上的元素时候,在h(k,i)位置上接近1的元素(k,i)在logp中被取出来,其他位置上的1并不会给最终的梯度带来影响,因为它们不会被取出来,所以在最初的h的最后一行,即使x(i)不属于第k类,我们把h(k,i)置为1,也不会对后面的运算造成影响。但如果x(i)确实属于第k类,我们把h(k,i)置为1,就保证了这部分误差会被计算到最终的误差J中。
以上计算了cost function J的值,接下来计算梯度g:
首先我们知道上面计算出来的P是一个k*m的矩阵(k是类的数目,m是样本的数量),P(k,i)表示样本x(i)属于第k类的概率,公式3中重要的是怎么求出一个k*m的矩阵yk,使得yk(k,i)表示x(i)是否属于第k类,如果属于,yk(k,i)=1;否则yk(k,i)=0;也就是公式3中减号前面的项,可以用如下代码实现:
yk = full(sparse(y,1:m,1));
full,sparse函数是非常神奇的。假设我们有一个矩阵A=[1,2,4],那么 full(sparse(A,1:3,1));就生成了如下的一个矩阵:
1 0 0 0 1 0 0 0 0 0 0 1
一般来说如果A是一个1*m的矩阵,那么full(sparse(A,1:m,1))就生成了一个(max(A),m)的矩阵,这个矩阵中(A(i),i)上的元素为1,其他元素都为0。这样我们用
yk = full(sparse(y,1:m,1));
就可以得到上面要求的yk。
不过呢,y里面是有10个类标的,所以yk其实是一个10*m的矩阵,前面说了,我们只要知道一个样本x为前9类的样本的概率就可以了,所以我们其实只需要yk的前9行,所以要对yk进行一个截短,同样对上面的p也做一个,因为其实p的最后一行是我们手动加上去的,并且在公式3中yk要和p相减,我们需要保证p和yk的维度match。
yk = yk(1:num_classes-1,:);
p = p(1:num_classes-1,:);
最后就可以根据公式3计算梯度了
g = -X * (yk-p)‘;
就这么三个公式,想用代码高效的实现就这么困难,有时候不光要关注idea,更要关注idea的实现。我实现的第一个版本准确率只有87%,这个版本有92%,有时候真的不知道是算法不好,还是实现不好,所以会码是非常重要的!
最后上下结果,总共迭代了232次:
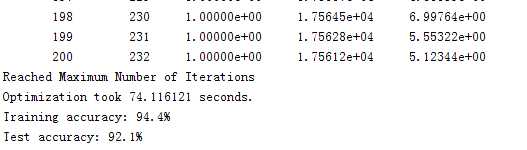
完整的代码可以在我的github上看到。
参考:
【1】http://blog.csdn.net/lingerlanlan/article/details/38425929
【2】http://ufldl.stanford.edu/tutorial/supervised/SoftmaxRegression/
【ufldl tutorial】Softmax Regression
标签:
原文地址:http://www.cnblogs.com/sunshineatnoon/p/4524365.html