标签:
作者:MSDN
译者:李马
预定义段
一个Windows NT的应用程序典型地拥有9个预定义段,它们是.text、.bss、.rdata、.data、.rsrc、.edata、.idata、.pdata和.debug。一些应用程序不需要所有的这些段,同样还有一些应用程序为了自己特殊的需要而定义了更多的段。这种做法与MS-DOS和Windows 3.1中的代码段和数据段相似。事实上,应用程序定义一个独特的段的方法是使用标准编译器来指示对代码段和数据段的命名,或者使用名称段编译器选项-NT——就和Windows 3.1中应用程序定义独特的代码段和数据段一样。
以下是一个关于Windows NT PE文件之中一些有趣的公共段的讨论。
可执行代码段,.text
Windows 3.1和Windows NT之间的一个区别就是Windows NT默认的做法是将所有的代码段(正如它们在Windows 3.1中所提到的那样)组成了一个单独的段,名为“.text”。既然Windows NT使用了基于页面的虚拟内存管理系统,那么将分开的代码放入不同的段之中的做法就不太明智了。因此,拥有一个大的代码段对于操作系统和应用程序开发者来说,都是十分方便的。
.text段也包含了早先提到过的入口点。IAT亦存在于.text段之中的模块入口点之前。(IAT在.text段之中的存在非常有意义,因为这个表事实上是一系列的跳转指令,并且它们的跳转目标位置是已固定的地址。)当Windows NT的可执行映像装载入进程的地址空间时,IAT就和每一个导入函数的物理地址一同确定了。要在.text段之中查找IAT,装载器只用将模块的入口点定位,而IAT恰恰出现于入口点之前。既然每个入口拥有相同的尺寸,那么向后退查找这个表的起始位置就很容易了。
数据段,.bss、.rdata、.data
.bss段表示应用程序的未初始化数据,包括所有函数或源模块中声明为static的变量。
.rdata段表示只读的数据,比如字符串文字量、常量和调试目录信息。
所有其它变量(除了出现在栈上的自动变量)存储在.data段之中。基本上,这些是应用程序或模块的全局变量。
资源段,.rsrc
.rsrc段包含了模块的资源信息。它起始于一个资源目录结构,这个结构就像其它大多数结构一样,但是它的数据被更进一步地组织在了一棵资源树之中。以下的IMAGE_RESOURCE_DIRECTORY结构形成了这棵树的根和各个结点。
//WINNT.H
typedef struct _IMAGE_RESOURCE_DIRECTORY {
ULONG Characteristics;
ULONG TimeDateStamp;
USHORT MajorVersion;
USHORT MinorVersion;
USHORT NumberOfNamedEntries;
USHORT NumberOfIdEntries;
} IMAGE_RESOURCE_DIRECTORY, *PIMAGE_RESOURCE_DIRECTORY;
请看这个目录结构,你将会发现其中竟然没有指向下一个结点的指针。但是,在这个结构中有两个域NumberOfNamedEntries和NumberOfIdEntries代替了指针,它们被用来表示这个目录附有多少入口。附带说一句,我的意思是目录入口就在段数据之中的目录后边。有名称的入口按字母升序出现,再往后是按数值升序排列的ID入口。
一个目录入口由两个域组成,正如下面IMAGE_RESOURCE_DIRECTORY_ENTRY结构所描述的那样:
// WINNT.H
typedef struct _IMAGE_RESOURCE_DIRECTORY_ENTRY {
ULONG Name;
ULONG OffsetToData;
} IMAGE_RESOURCE_DIRECTORY_ENTRY, *PIMAGE_RESOURCE_DIRECTORY_ENTRY;
根据树的层级不同,这两个域也就有着不同的用途。Name域被用于标识一个资源种类,或者一种资源名称,或者一个资源的语言ID。OffsetToData与常常被用来在树之中指向兄弟结点——即一个目录结点或一个叶子结点。
叶子结点是资源树之中最底层的结点,它们定义了当前资源数据的尺寸和位置。IMAGE_RESOURCE_DATA_ENTRY结构被用于描述每个叶子结点:
// WINNT.H
typedef struct _IMAGE_RESOURCE_DATA_ENTRY {
ULONG OffsetToData;
ULONG Size;
ULONG CodePage;
ULONG Reserved;
} IMAGE_RESOURCE_DATA_ENTRY, *PIMAGE_RESOURCE_DATA_ENTRY;
OffsetToData和Size这两个域表示了当前资源数据的位置和尺寸。既然这一信息主要是在应用程序装载以后由函数使用的,那么将OffsetToData作为一个相对虚拟的地址会更有意义一些。——幸甚,恰好是这样没错。非常有趣的是,所有其它的偏移量,比如从目录入口到其它目录的指针,都是相对于根结点位置的偏移量。
要更清楚地了解这些内容,请参考图2。 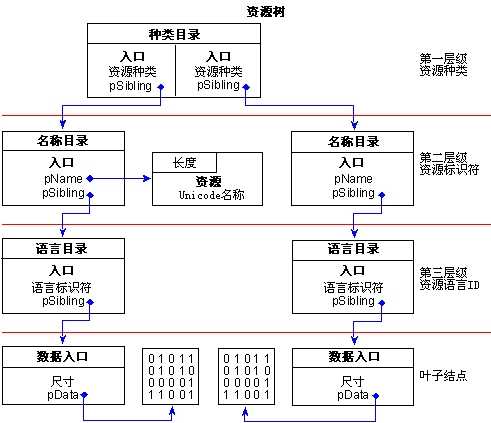
图2.一个简单的资源树结构
图2描述了一个非常简单的资源树,它包含了仅仅两个资源对象:一个菜单和一个字串表。更深一层地来说,它们各自都有一个子项。然而,你仍然可以看到资源树有多么复杂——即使它像这个一样只有一点点资源。
在树的根部,第一个目录有一个文件中包含的所有资源种类的入口,而不管资源种类有多少。在图2中,有两个由树根标识的入口,一个是菜单的,另一个是字串表的。如果文件中拥有一个或多个对话框资源,那么根结点会再拥有一个入口,因此,就有了对话框资源的另一个分支。
WINUSER.H中标识了基本的资源种类,我将它们列到了下面:
//WINUSER.H /* * 预定义的资源种类 */ #define RT_CURSOR MAKEINTRESOURCE(1) #define RT_BITMAP MAKEINTRESOURCE(2) #define RT_ICON MAKEINTRESOURCE(3) #define RT_MENU MAKEINTRESOURCE(4) #define RT_DIALOG MAKEINTRESOURCE(5) #define RT_STRING MAKEINTRESOURCE(6) #define RT_FONTDIR MAKEINTRESOURCE(7) #define RT_FONT MAKEINTRESOURCE(8) #define RT_ACCELERATOR MAKEINTRESOURCE(9) #define RT_RCDATA MAKEINTRESOURCE(10) #define RT_MESSAGETABLE MAKEINTRESOURCE(11)
在树的第一层级,以上列出的MAKEINTRESOURCE值被放置在每个种类入口的Name处,它标识了不同的资源种类。
每个根目录的入口都指向了树中第二层级的一个兄弟结点,这些结点也是目录,并且每个都拥有它们自己的入口。在这一层级,目录被用来以给定的种类标识每一个资源种类。如果你的应用程序中有多个菜单,那么树中的第二层级会为每个菜单都准备一个入口。
你可能意识到了,资源可以由名称或整数标识。在这一层级,它们是通过目录结构的Name域来分辨的。如果如果Name域最重要的位被设置了,那么其它的31个位就会被用作一个到IMAGE_RESOURCE_DIR_STRING_U结构的偏移量。
// WINNT.H
typedef struct _IMAGE_RESOURCE_DIR_STRING_U {
USHORT Length;
WCHAR NameString[1];
} IMAGE_RESOURCE_DIR_STRING_U, *PIMAGE_RESOURCE_DIR_STRING_U;
这个结构仅仅是由一个2字节长的Length域和一个UNICODE字符Length组成的。
另一方面,如果Name域最重要的位被清空,那么它的低31位就被用于表示资源的整数ID。图2示范的就是菜单资源作为一个命名的资源,以及字串表作为一个ID资源。
如果有两个菜单资源,一个由名称标识,另一个由资源标识,那么它们二者就会在菜单资源目录之后拥有两个入口。有名称的资源入口在第一位,之后是由整数标识的资源。目录域NumberOfNamedEntries和NumberOfIdEntries将各自包含值1,表示当前的1个入口。
在第二层级的下面,资源树就不再更深一步地扩展分支了。第一层级分支至表示每个资源种类的目录中,第二层级分支至由标识符表示的每个资源的目录中,第三层级是被个别标识的资源与它们各自的语言ID之间一对一的映射。要表示一个资源的语言ID,目录入口结构的Name域就被用来表示资源的主语言ID和子语言ID了。Windows NT的Win32 SDK开发包中列出了默认的值资源,例如对于0x0409这个值来说,0x09表示主语言LANG_ENGLISH,0x04则被定义为子语言的SUBLANG_ENGLISH_CAN。所有的语言ID值都定义于Windows NT Win32 SDK开发包的文件WINNT.H中。
既然语言ID结点是树中最后的目录结点,那么入口结构的OffsetToData域就是到一个叶子结点(即前面提到过的IMAGE_RESOURCE_DATA_ENTRY结构)的偏移量。
再回过头来参考图2,你会发现每个语言目录入口都对应着一个数据入口。这个结点仅仅表示了资源数据的尺寸以及资源数据的相对虚拟地址。
在资源数据段(.rsrc)之中拥有这么多结构有一个好处,就是你可以不存取资源本身而直接可以从这个段收集很多信息。例如,你可以获得有多少种资源、哪些资源(如果有的话)使用了特别的语言ID、特定的资源是否存在以及单独种类资源的尺寸。为了示范如何利用这一信息,以下的函数说明了如何决定一个文件中包含的不同种类的资源:
// PEFILE.C
int WINAPI GetListOfResourceTypes(LPVOID lpFile, HANDLE hHeap, char **pszResTypes)
{
PIMAGE_RESOURCE_DIRECTORY prdRoot;
PIMAGE_RESOURCE_DIRECTORY_ENTRY prde;
char *pMem;
int nCnt, i;
/* 获得资源树的根目录 */
if ((prdRoot = (PIMAGE_RESOURCE_DIRECTORY)ImageDirectoryOffset
(lpFile, IMAGE_DIRECTORY_ENTRY_RESOURCE)) == NULL)
return 0;
/* 在堆上分配足够的空间来包括所有类型 */
nCnt = prdRoot->NumberOfIdEntries * (MAXRESOURCENAME + 1);
*pszResTypes = (char *)HeapAlloc(hHeap, HEAP_ZERO_MEMORY,
nCnt);
if ((pMem = *pszResTypes) == NULL)
return 0;
/* 将指针指向第一个资源种类的入口 */
prde = (PIMAGE_RESOURCE_DIRECTORY_ENTRY)((DWORD)prdRoot +
sizeof (IMAGE_RESOURCE_DIRECTORY));
/* 在所有的资源目录入口类型中循环 */
for (i = 0; i < prdRoot->NumberOfIdEntries; i++)
{
if (LoadString(hDll, prde->Name, pMem, MAXRESOURCENAME))
pMem += strlen(pMem) + 1;
prde++;
}
return nCnt;
}
这个函数将一个资源种类名称的列表写入了由pszResTypes标识的变量中。请注意,在这个函数的核心部分,LoadString是使用各自资源种类目录入口的Name域来作为字符串ID的。如果你查看PEFILE.RC,你会发现我定义了一系列的资源种类的字符串,并且它们的ID与它们在目录入口中的定义完全相同。PEFILE.DLL还有有一个函数,它返回了.rsrc段中的资源对象总数。这样一来,从这个段中提取其它的信息,借助这些函数或另外编写函数就方便多了。
导出数据段,.edata
.edata段包含了应用程序或DLL的导出数据。在这个段出现的时候,它会包含一个到达导出信息的导出目录。
// WINNT.H
typedef struct _IMAGE_EXPORT_DIRECTORY {
ULONG Characteristics;
ULONG TimeDateStamp;
USHORT MajorVersion;
USHORT MinorVersion;
ULONG Name;
ULONG Base;
ULONG NumberOfFunctions;
ULONG NumberOfNames;
PULONG *AddressOfFunctions;
PULONG *AddressOfNames;
PUSHORT *AddressOfNameOrdinals;
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;
导出目录中的Name域标识了可执行模块的名称。NumberOfFunctions域和NumberOfNames域表示模块中有多少导出的函数以及这些函数的名称。
AddressOfFunctions域是一个到导出函数入口列表的偏移量。AddressOfNames域是到一个导出函数名称列表起始处偏移量的地址,这个列表是由null分隔的。AddressOfNameOrdinals是一个到相同导出函数顺序值(每个值2字节长)列表的偏移量。
三个AddressOf...域是当模块装载时进程地址空间中的相对虚拟地址。一旦模块被装载,那么要获得进程地质空间中的确切地址的话,就应该在相对虚拟地址上加上模块的基地址。可是,在文件被装载前,仍然可以决定这一地址:只要从给定的域地址中减去段头部的虚拟地址(VirtualAddress),再加上段实体的偏移量(PointerToRawData),这个结果就是映像文件中的偏移量了。以下的例子解说了这一技术:
// PEFILE.C
int WINAPI GetExportFunctionNames(LPVOID lpFile, HANDLE hHeap, char **pszFunctions)
{
IMAGE_SECTION_HEADER sh;
PIMAGE_EXPORT_DIRECTORY ped;
char *pNames, *pCnt;
int i, nCnt;
/* 获得.edata域中的段头部和指向数据目录的指针 */
if ((ped = (PIMAGE_EXPORT_DIRECTORY)ImageDirectoryOffset
(lpFile, IMAGE_DIRECTORY_ENTRY_EXPORT)) == NULL)
return 0;
GetSectionHdrByName (lpFile, &sh, ".edata");
/* 决定导出函数名称的偏移量 */
pNames = (char *)(*(int *)((int)ped->AddressOfNames -
(int)sh.VirtualAddress + (int)sh.PointerToRawData +
(int)lpFile) - (int)sh.VirtualAddress +
(int)sh.PointerToRawData + (int)lpFile);
/* 计算出要为所有的字符串分配多少内存 */
pCnt = pNames;
for (i = 0; i < (int)ped->NumberOfNames; i++)
while (*pCnt++);
nCnt = (int)(pCnt.pNames);
/* 在堆上为函数名称分配内存 */
*pszFunctions = HeapAlloc (hHeap, HEAP_ZERO_MEMORY, nCnt);
/* 将所有字符串复制到缓冲区 */
CopyMemory((LPVOID)*pszFunctions, (LPVOID)pNames, nCnt);
return nCnt;
}
请注意,在这个函数之中,变量pNames是由决定偏移量地址和当前偏移量位置的方法来赋值的。偏移量的地址和偏移量本身都是相对虚拟地址,因此在使用之前必须进行转换——函数之中体现了这一点。虽然你可以编写一个类似的函数来决定顺序值或函数入口点,但是我为什么不为你做好呢?——GetNumberOfExportedFunctions、GetExportFunctionEntryPoints和GetExportFunctionOrdinals已经存在于PEFILE.DLL之中了。
导入数据段,.idata
.idata段是导入数据,包括导入库和导入地址名称表。虽然定义了IMAGE_DIRECTORY_ENTRY_IMPORT,但是WINNT.H之中并无相应的导入目录结构。作为代替,其中有若干其它的结构,名为IMAGE_IMPORT_BY_NAME、IMAGE_THUNK_DATA与IMAGE_IMPORT_DESCRIPTOR。在我个人看来,我实在不知道这些结构是如何和.idata段发生关联的,所以我花了若干个小时来破译.idata段实体并且得到了一个更简单的结构,我名之为IMAGE_IMPORT_MODULE_DIRECTORY。
// PEFILE.H
typedef struct tagImportDirectory
{
DWORD dwRVAFunctionNameList;
DWORD dwUseless1;
DWORD dwUseless2;
DWORD dwRVAModuleName;
DWORD dwRVAFunctionAddressList;
} IMAGE_IMPORT_MODULE_DIRECTORY, *PIMAGE_IMPORT_MODULE_DIRECTORY;
和其它段的数据目录不同的是,这个是作为文件中的每个导入模块重复出现的。你可以将它看作模块数据目录列表中的一个入口,而不是一个整个数据段的数据目录。每个入口都是一个指向特定模块导入信息的目录。
IMAGE_IMPORT_MODULE_DIRECTORY结构中的一个域dwRVAModuleName是一个相对虚拟地址,它指向模块的名称。结构中还有两个dwUseless参数,它们是为了保持段的对齐。PE文件格式规范提到了一些东西,关于导入标记、时间/日期标志以及主/次版本,但是在我的实验中,这两个域自始而终都是空的,所以我仍然认为它们没有什么用处。
基于这个结构的定义,你便可以获得可执行文件中导入的所有模块和函数名称了。以下的函数示范了如何获得特定的PE文件中的所有导入函数名称:
//PEFILE.C
int WINAPI GetImportModuleNames(LPVOID lpFile, HANDLE hHeap, char **pszModules)
{
PIMAGE_IMPORT_MODULE_DIRECTORY pid;
IMAGE_SECTION_HEADER idsh;
BYTE *pData;
int nCnt = 0, nSize = 0, i;
char *pModule[1024];
char *psz;
pid = (PIMAGE_IMPORT_MODULE_DIRECTORY)ImageDirectoryOffset
(lpFile, IMAGE_DIRECTORY_ENTRY_IMPORT);
pData = (BYTE *)pid;
/* 定位.idata段头部 */
if (!GetSectionHdrByName(lpFile, &idsh, ".idata"))
return 0;
/* 提取所有导入模块 */
while (pid->dwRVAModuleName)
{
/* 为绝对字符串偏移量分配缓冲区 */
pModule[nCnt] = (char *)(pData +
(pid->dwRVAModuleName-idsh.VirtualAddress));
nSize += strlen(pModule[nCnt]) + 1;
/* 增至下一个导入目录入口 */
pid++;
nCnt++;
}
/* 将所有字符串赋值到一大块的堆内存中 */
*pszModules = HeapAlloc(hHeap, HEAP_ZERO_MEMORY, nSize);
psz = *pszModules;
for (i = 0; i < nCnt; i++)
{
strcpy(psz, pModule[i]);
psz += strlen (psz) + 1;
}
return nCnt;
}
这个函数非常好懂,然而有一点值得指出——注意while循环。这个循环当pid->dwRVAModuleName为0的时候终止,这就暗示了在IMAGE_IMPORT_MODULE_DIRECTORY结构列表的末尾有一个空的结构,这个结构拥有一个0值,至少dwRVAModuleName域为0。这便是我在对文件的实验中以及之后在PE文件格式中研究的行为。
这个结构中的第一个域dwRVAFunctionNameList是一个相对虚拟地址,这个地址指向一个相对虚拟地址的列表,这些地址是文件中的一些文件名。如下面的数据所示,所有导入模块的模块和函数名称都列于.idata段数据中了:
E6A7 0000 F6A7 0000 08A8 0000 1AA8 0000 ................ 28A8 0000 3CA8 0000 4CA8 0000 0000 0000 (...<...L....... 0000 4765 744F 7065 6E46 696C 654E 616D ..GetOpenFileNam 6541 0000 636F 6D64 6C67 3332 2E64 6C6C eA..comdlg32.dll 0000 2500 4372 6561 7465 466F 6E74 496E ..%.CreateFontIn 6469 7265 6374 4100 4744 4933 322E 646C directA.GDI32.dl 6C00 A000 4765 7444 6576 6963 6543 6170 l...GetDeviceCap 7300 C600 4765 7453 746F 636B 4F62 6A65 s...GetStockObje 6374 0000 D500 4765 7454 6578 744D 6574 ct....GetTextMet 7269 6373 4100 1001 5365 6C65 6374 4F62 ricsA...SelectOb 6A65 6374 0000 1601 5365 7442 6B43 6F6C ject....SetBkCol 6F72 0000 3501 5365 7454 6578 7443 6F6C or..5.SetTextCol 6F72 0000 4501 5465 7874 4F75 7441 0000 or..E.TextOutA..
以上的数据是EXEVIEW.EXE示例程序.idata段的一部分。这个特别的段表示了导入模块列表和函数名称列表的起始处。如果你开始检查数据中的这个段,你应该认出一些熟悉的Win32 API函数以及模块名称。从上往下读的话,你可以找到GetOpenFileNameA,紧接着是COMDLG32.DLL。然后你能发现CreateFontIndirectA,紧接着是模块GDI32.DLL,以及之后的GetDeviceCaps、GetStockObject、GetTextMetrics等等。
这样的式样会在.idata段中重复出现。第一个模块是COMDLG32.DLL,第二个是GDI32.DLL。请注意第一个模块只导出了一个函数,而第二个模块导出了很多函数。在这两种情况下,函数和模块的排列的方法是首先出现一个函数名,之后是模块名,然后是其它的函数名(如果有的话)。
以下的函数示范了如何获得指定模块的所有函数名。
// PEFILE.C
int WINAPI GetImportFunctionNamesByModule(LPVOID lpFile, HANDLE hHeap,
char *pszModule, char **pszFunctions)
{
PIMAGE_IMPORT_MODULE_DIRECTORY pid;
IMAGE_SECTION_HEADER idsh;
DWORD dwBase;
int nCnt = 0, nSize = 0;
DWORD dwFunction;
char *psz;
/* 定位.idata段的头部 */
if (!GetSectionHdrByName(lpFile, &idsh, ".idata"))
return 0;
pid = (PIMAGE_IMPORT_MODULE_DIRECTORY)ImageDirectoryOffset
(lpFile, IMAGE_DIRECTORY_ENTRY_IMPORT);
dwBase = ((DWORD)pid. idsh.VirtualAddress);
/* 查找模块的pid */
while (pid->dwRVAModuleName && strcmp (pszModule,
(char *)(pid->dwRVAModuleName+dwBase)))
pid++;
/* 如果模块未找到,就退出 */
if (!pid->dwRVAModuleName)
return 0;
/* 函数的总数和字符串长度 */
dwFunction = pid->dwRVAFunctionNameList;
while (dwFunction && *(DWORD *)(dwFunction + dwBase) &&
*(char *)((*(DWORD *)(dwFunction + dwBase)) + dwBase+2))
{
nSize += strlen ((char *)((*(DWORD *)(dwFunction +
dwBase)) + dwBase+2)) + 1;
dwFunction += 4;
nCnt++;
}
/* 在堆上分配函数名称的空间 */
*pszFunctions = HeapAlloc (hHeap, HEAP_ZERO_MEMORY, nSize);
psz = *pszFunctions;
/* 向内存指针复制函数名称 */
dwFunction = pid->dwRVAFunctionNameList;
while (dwFunction && *(DWORD *)(dwFunction + dwBase) &&
*((char *)((*(DWORD *)(dwFunction + dwBase)) + dwBase+2)))
{
strcpy (psz, (char *)((*(DWORD *)(dwFunction + dwBase)) +
dwBase+2));
psz += strlen((char *)((*(DWORD *)(dwFunction + dwBase))+
dwBase+2)) + 1;
dwFunction += 4;
}
return nCnt;
}
就像GetImportModuleNames函数一样,这一函数依靠每个信息列表的末端来获得一个置零的入口。这在种情况下,函数名称列表就是以零结尾的。
最后一个域dwRVAFunctionAddressList是一个相对虚拟地址,它指向一个虚拟地址表。在文件装载的时候,这个虚拟地址表会被装载器置于段数据之中。但是在文件装载前,这些虚拟地址会被一些严密符合函数名称列表的虚拟地址替换。所以在文件装载之前,有两个同样的虚拟地址列表,它们指向导入函数列表。
调试信息段,.debug
调试信息位于.debug段之中,同时PE文件格式也支持单独的调试文件(通常由.DBG扩展名标识)作为一种将调试信息集中的方法。调试段包含了调试信息,但是调试目录却位于早先提到的.rdata段之中。这其中每个目录都涉及了.debug段之中的调试信息。调试目录的结构IMAGE_DEBUG_DIRECTORY被定义为:
// WINNT.H
typedef struct _IMAGE_DEBUG_DIRECTORY {
ULONG Characteristics;
ULONG TimeDateStamp;
USHORT MajorVersion;
USHORT MinorVersion;
ULONG Type;
ULONG SizeOfData;
ULONG AddressOfRawData;
ULONG PointerToRawData;
} IMAGE_DEBUG_DIRECTORY, *PIMAGE_DEBUG_DIRECTORY;
这个段被分为单独的部分,每个部分为不同种类的调试信息数据。对于每个部分来说都是一个像上边一样的调试目录。不同的调试信息种类如下:
// WINNT.H #define IMAGE_DEBUG_TYPE_UNKNOWN 0 #define IMAGE_DEBUG_TYPE_COFF 1 #define IMAGE_DEBUG_TYPE_CODEVIEW 2 #define IMAGE_DEBUG_TYPE_FPO 3 #define IMAGE_DEBUG_TYPE_MISC 4
每个目录之中的Type域表示该目录的调试信息种类。如你所见,在上边的表中,PE文件格式支持很多不同的调试信息种类,以及一些其它的信息域。对于那些来说,IMAGE_DEBUG_TYPE_MISC信息是唯一的。这一信息被添加到描述可执行映像的混杂信息之中,这些混杂信息不能被添加到PE文件格式任何结构化的数据段之中。这就是映像文件中最合适的位置,映像名称则肯定会出现在这里。如果映像导出了信息,那么导出数据段也会包含这一映像名称。
每种调试信息都拥有自己的头部结构,该结构定义了它自己的数据。这些结构都列于WINNT.H之中。关于IMAGE_DEBUG_DIRECTORY一件有趣的事就是它包括了两个标识调试信息的域。第一个是AddressOfRawData,为相对文件装载的数据虚拟地址;另一个是PointerToRawData,为数据所在PE文件之中的实际偏移量。这就使得定位指定的调试信息相当容易了。
作为最后的例子,请你考虑以下的函数代码,它从IMAGE_DEBUG_MISC结构中提取了映像名称。
//PEFILE.C
int WINAPI RetrieveModuleName(LPVOID lpFile, HANDLE hHeap, char **pszModule)
{
PIMAGE_DEBUG_DIRECTORY pdd;
PIMAGE_DEBUG_MISC pdm = NULL;
int nCnt;
if (!(pdd = (PIMAGE_DEBUG_DIRECTORY)ImageDirectoryOffset(lpFile,
IMAGE_DIRECTORY_ENTRY_DEBUG)))
return 0;
while (pdd->SizeOfData)
{
if (pdd->Type == IMAGE_DEBUG_TYPE_MISC)
{
pdm = (PIMAGE_DEBUG_MISC)((DWORD)pdd->PointerToRawData + (DWORD)lpFile);
nCnt = lstrlen(pdm->Data) * (pdm->Unicode ? 2 : 1);
*pszModule = (char *)HeapAlloc(hHeap, HEAP_ZERO_MEMORY, nCnt+1);
CopyMemory(*pszModule, pdm->Data, nCnt);
break;
}
pdd ++;
}
if (pdm != NULL)
return nCnt;
else
return 0;
}
你看到了,调试目录结构使得定位一个特定种类的调试信息变得相对容易了些。只要定位了IMAGE_DEBUG_MISC结构,提取映像名称就如同调用CopyMemory函数一样简单。
如上所述,调试信息可以被剥离到单独的.DBG文件中。Windows NT SDK包含了一个名为REBASE.EXE的程序可以实现这一目的。例如,以下的语句可以将一个名为TEST.EXE的调试信息剥离:
rebase -b 40000 -x c:\samples\testdir test.exe
调试信息被置于一个新的文件中,这个文件名为TEST.DBG,位于c:\samples\testdir之中。这个文件起始于一个单独的IMAGE_SEPARATE_DEBUG_HEADER结构,接着是存在于原可执行映像之中的段头部的一份拷贝。在段头部之后,是.debug段的数据。也就是说,在段头部之后,就是一系列的IMAGE_DEBUG_DIRECTORY结构及其相关的数据了。调试信息本身保留了如上所描述的常规映像文件调试信息。
PE文件格式总结
Windows NT的PE文件格式向熟悉Windows和MS-DOS环境的开发者引入了一种全新的结构。然而熟悉UNIX环境的开发者会发现PE文件格式与COFF规范很相像(如果它不是以COFF为基础的话)。
整个格式的组成:一个MS-DOS的MZ头部,之后是一个实模式的残余程序、PE文件标志、PE文件头部、PE可选头部、所有的段头部,最后是所有的段实体。
可选头部的末尾是一个数据目录入口的数组,这些相对虚拟地址指向段实体之中的数据目录。每个数据目录都表示了一个特定的段实体数据是如何组织的。
PE文件格式有11个预定义段,这是对Windows NT应用程序所通用的,但是每个应用程序可以为它自己的代码以及数据定义它自己独特的段。
.debug预定义段也可以分离为一个单独的调试文件。如果这样的话,就会有一个特定的调试头部来用于解析这个调试文件,PE文件中也会有一个标志来表示调试数据被分离了出去。
PEFILE.DLL函数描述
PEFILE.DLL主要由一些函数组成,这些函数或者被用来获得一个给定的PE文件中的偏移量,或者被用来把文件中的一些数据复制到一个特定的结构中去。每个函数都有一个需求——第一个参数是一个指针,这个指针指向PE文件的起始处。也就是说,这个文件必须首先被映射到你进程的地址空间中,然后映射文件的位置就可以作为每个函数第一个参数的lpFile的值来传入了。
我意在使函数的名称使你能够一见而知其意,并且每个函数都随一个详细描述其目的的注释而列出。如果在读完函数列表之后,你仍然不明白某个函数的功能,那么请参考EXEVIEW.EXE示例来查明这个函数是如何使用的。以下的函数原型列表可以在PEFILE.H中找到:
// PEFILE.H /* 获得指向MS-DOS MZ头部的指针 */ BOOL WINAPI GetDosHeader(LPVOID, PIMAGE_DOS_HEADER); /* 决定.EXE文件的类型 */ DWORD WINAPI ImageFileType(LPVOID); /* 获得指向PE文件头部的指针 */ BOOL WINAPI GetPEFileHeader(LPVOID, PIMAGE_FILE_HEADER); /* 获得指向PE可选头部的指针 */ BOOL WINAPI GetPEOptionalHeader(LPVOID, PIMAGE_OPTIONAL_HEADER); /* 返回模块入口点的地址 */ LPVOID WINAPI GetModuleEntryPoint(LPVOID); /* 返回文件中段的总数 */ int WINAPI NumOfSections(LPVOID); /* 返回当可执行文件被装载入进程地址空间时的首选基地址 */ LPVOID WINAPI GetImageBase(LPVOID); /* 决定文件中一个特定的映像数据目录的位置 */ LPVOID WINAPI ImageDirectoryOffset(LPVOID, DWORD); /* 获得文件中所有段的名称 */ int WINAPI GetSectionNames(LPVOID, HANDLE, char **); /* 复制一个特定段的头部信息 */ BOOL WINAPI GetSectionHdrByName(LPVOID, PIMAGE_SECTION_HEADER, char *); /* 获得由空字符分隔的导入模块名称列表 */ int WINAPI GetImportModuleNames(LPVOID, HANDLE, char **); /* 获得一个模块由空字符分隔的导入函数列表 */ int WINAPI GetImportFunctionNamesByModule(LPVOID, HANDLE, char *, char **); /* 获得由空字符分隔的导出函数列表 */ int WINAPI GetExportFunctionNames(LPVOID, HANDLE, char **); /* 获得导出函数总数 */ int WINAPI GetNumberOfExportedFunctions(LPVOID); /* 获得导出函数的虚拟地址入口点列表 */ LPVOID WINAPI GetExportFunctionEntryPoints(LPVOID); /* 获得导出函数顺序值列表 */ LPVOID WINAPI GetExportFunctionOrdinals(LPVOID); /* 决定资源对象的种类 */ int WINAPI GetNumberOfResources (LPVOID); /* 返回文件中所使用的所有资源对象的种类 */ int WINAPI GetListOfResourceTypes(LPVOID, HANDLE, char **); /* 决定调试信息是否已从文件中分离 */ BOOL WINAPI IsDebugInfoStripped(LPVOID); /* 获得映像文件名称 */ int WINAPI RetrieveModuleName(LPVOID, HANDLE, char **); /* 决定文件是否是一个有效的调试文件 */ BOOL WINAPI IsDebugFile(LPVOID); /* 从调试文件中返回调试头部 */ BOOL WINAPI GetSeparateDebugHeader(LPVOID, PIMAGE_SEPARATE_DEBUG_HEADER); 除了以上所列的函数之外,本文中早先提到的宏也定义在了PEFILE.H中,完整的列表如下: /* PE文件标志的偏移量 */ #define NTSIGNATURE(a) ((LPVOID)((BYTE *)a + ((PIMAGE_DOS_HEADER)a)->e_lfanew)) /* MS操作系统头部标识了双字的NT PE文件标志;PE文件头部就紧跟在这个双字之后 */ #define PEFHDROFFSET(a) ((LPVOID)((BYTE *)a + ((PIMAGE_DOS_HEADER)a)->e_lfanew + SIZE_OF_NT_SIGNATURE)) /* PE可选头部紧跟在PE文件头部之后 */ #define OPTHDROFFSET(a) ((LPVOID)((BYTE *)a + ((PIMAGE_DOS_HEADER)a)->e_lfanew + SIZE_OF_NT_SIGNATURE + sizeof(IMAGE_FILE_HEADER))) /* 段头部紧跟在PE可选头部之后 */ #define SECHDROFFSET(a) ((LPVOID)((BYTE *)a + ((PIMAGE_DOS_HEADER)a)->e_lfanew + SIZE_OF_NT_SIGNATURE + sizeof(IMAGE_FILE_HEADER) + sizeof(IMAGE_OPTIONAL_HEADER)))
要使用PEFILE.DLL,你只用包含PEFILE.H文件并在应用程序中链接到这个DLL即可。所有的这些函数都是互斥性的函数,但是有些函数的功能可以相互支持以获得文件信息。例如,GetSectionNames可以用于获得所有段的名称,这样一来,为了获得一个拥有独特段名称(在编译期由应用程序开发者定义的)的段头部,你就需要首先获得所有名称的列表,然后再对那个准确的段名称调用函数GetSectionHeaderByName了。现在,你可以享受我为你带来的这一切了!
标签:
原文地址:http://www.cnblogs.com/yzl050819/p/4533337.html