标签:
Mapreduce 工作机制图:
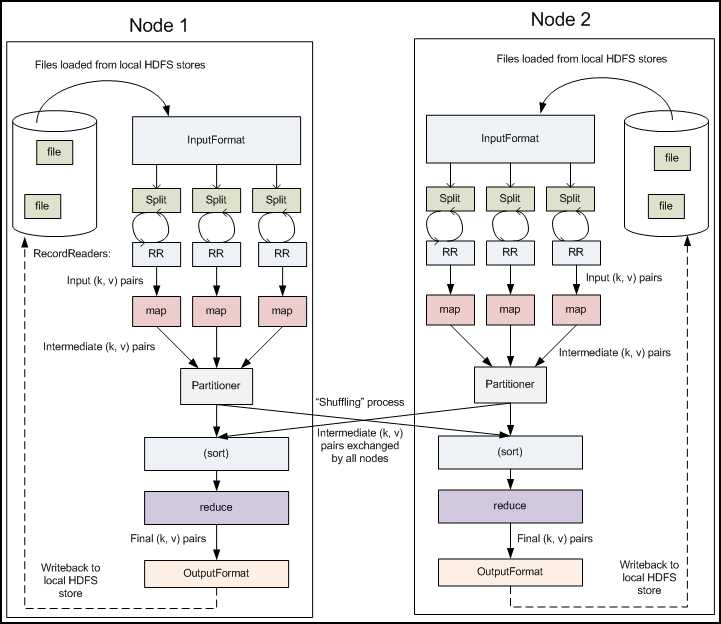
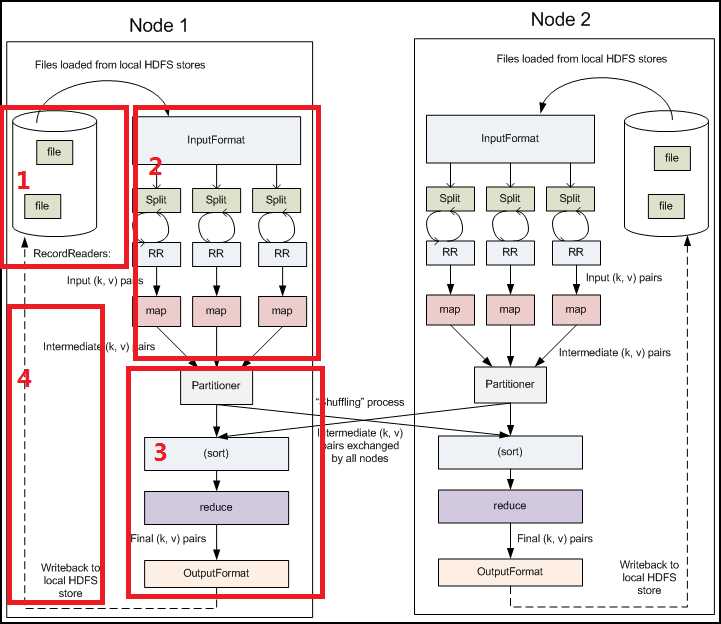
图中1:表示待处理数据,比如日志,比如单词计数
图中2:表示map阶段,对他们split,然后送到不同分区
图中3:表示reduce阶段,对这些数据整合处理。
图中4:表示二次mapreduce,这个是mapreduce的链式
MapReduce组合式,迭代式,链式
问题导读:
1.比如我们输出的mapreduce结果,需要进入下一个mapreduce,该怎么解决?
可以使用迭代式
2.那么什么是迭代式?
3.什么是依赖式?
4.什么是链式?
5.三种模式各自的应用场景是什么?
1.迭代式mapreduce
一些复杂的任务难以用一次MapReduce处理完成,需要多次 MapReduce 才能完成任务,例如Pagrank,K-means算法都需要多次的迭代,关于 MapReduce 迭代在Mahout中运用较多。有兴趣的可以参考一下Mahout的源码。
在MapReduce的迭代思想,类似for循环,前一个 MapReduce的输出结果,作为下一个 MapReduce的输入,任务完成后中间结果都可以删除。
代码示例:
1 Configuration conf1 = new Configuration(); 2 Job job1 = new Job(conf1,"job1"); 3 ..... 4 FileInputFormat.addInputPath(job1,InputPaht1); 5 FileOutputFromat.setOoutputPath(job1,Outpath1); 6 job1.waitForCompletion(true); 7 //sub Mapreduce 8 Configuration conf2 = new Configuration(); 9 Job job2 = new Job(conf1,"job1"); 10 ..... 11 FileInputFormat.addInputPath(job2,Outpath1); 12 FileOutputFromat.setOoutputPath(job2,Outpath2); 13 job2.waitForCompletion(true); 14 //sub Mapreduce 15 Configuration conf3 = new Configuration(); 16 Job job3 = new Job(conf1,"job1"); 17 ..... 18 FileInputFormat.addInputPath(job3,Outpath2); 19 FileOutputFromat.setOoutputPath(job3,Outpath3); 20 job3.waitForCompletion(true); 21 .....
关键点:
上面满眼的代码,下面列出关键代码:
第一个job的输出路径为Outpath1
FileOutputFromat.setOoutputPath(job1,Outpath1);
第二个job的输入路径为Outpath1,输出路径为Outpath2
FileInputFormat.addInputPath(job2,Outpath1);
FileOutputFromat.setOoutputPath(job2,Outpath2);
第三个job的输入路径为Outpath2
FileInputFormat.addInputPath(job3,Outpath2);
换句话说:第一个job的输出路径为第二个job的输入路径,以此类推。
上面采用的是一种直线式,那么他们能不能更省事,成为循环样式。
成为循环式,是可以的,但是有不少需要解决的问题:这里只是举例,你可能还会碰到其它问题。
1.需要他们的key,value等值是完全一致的,也就是说两个job或则说job之间必须是一致的。
2.输入输出路径需要区分等。
2.依赖关系组合式MapReduce
我们可以设想一下MapReduce有3个子任务job1,job2,job3构成,其中job1和job2相互独立,job3要在job1和job2完成之后才执行。这种关系就叫复杂数据依赖关系的组合时mapreduce。hadoop为这种组合关系提供了一种执行和控制机制,hadoop通过job和jobControl类提供具体的编程方法。Job除了维护子任务的配置信息,还维护子任务的依赖关系,而jobControl控制整个作业流程,把所有的子任务作业加入到JobControl中,执行JobControl的run()方法即可运行程序。
下面给出伪代码:
1 Configuration job1conf = new Configuration(); 2 Job job1 = new Job(job1conf,"Job1"); 3 .........//job1 其他设置 4 Configuration job2conf = new Configuration(); 5 Job job2 = new Job(job2conf,"Job2"); 6 .........//job2 其他设置 7 Configuration job3conf = new Configuration(); 8 Job job3 = new Job(job3conf,"Job3"); 9 .........//job3 其他设置 10 job3.addDepending(job1);//设置job3和job1的依赖关系 11 job3.addDepending(job2); 12 JobControl JC = new JobControl("123"); 13 JC.addJob(job1);//把三个job加入到jobcontorl中 14 JC.addJob(job2); 15 JC.addJob(job3); 16 JC.run();
关键点:
下面代码:addDepending()这个函数,作用的是建立两个job之间的依赖关系。那么如何建立,看下面两行
//下面面代码的作用是设置job3和job1的依赖关系
job3.addDepending(job1);
//下面代码的作用是设置job3和job2的依赖关系
job3.addDepending(job2);
建立依赖关系之后,还有一步骤,也就是还有一个类需要我们了解JobControl,通过这个类来控制他们之间的依赖关系。如何做到,通过下面代码:
//实例化
JobControl JC = new JobControl("123");
//把三个job加入到jobcontorl中
JC.addJob(job1);
JC.addJob(job2);
JC.addJob(job3);
JC.run();
3.链式MapReduce
首先看一下例子,来说明为什么要有链式MapReduce,假设在统计单词是,会出现这样的词,make,made,making等,他们都属于一个词,在单词累加的时候,都归于一个词。解决的方法为用一个单独的Mapreduce任务可以实现,单增加了多个Mapreduce作业,将增加整个作业处理的周期,还增加了I/O操作,因而处理效率不高。
一个较好的办法就是在核心的MapReduce之外,增加一个辅助的Map过程,然后将这个辅助的Map过程和核心的Mapreudce过程合并为一个链式的Mapreduce,从而完成整个作业。hadoop提供了专门的链式ChainMapper和ChainReducer来处理链式任务,ChainMapper允许一个Map任务中添加多个Map的子任务,ChainReducer可以在Reducer执行之后,在加入多个Map的子任务。其调用形式如下:
1 ChainMapper.addMapper(...); 2 ChainReducer.addMapper(...); 3 //addMapper()调用的方法形式如下: 4 public static void addMapper(JOb job, 5 Class<? extends Mapper> mclass, 6 Class<?> inputKeyClass, 7 Class<?> inputValueClass, 8 Class<?> outputKeyClass, 9 Class<?> outputValueClass, 10 Configuration conf 11 ){ 12 }
其中,ChainReducer专门提供了一个setRreducer()方法来设置整个作业唯一的Reducer。
note:这些Mapper和Reducer之间传递的键和值都必须保持一致。
下面举个例子:用ChainMapper把Map1加如并执行,然后用ChainReducer把Reduce和Map2加入到Reduce过程中。代码如下:Map1.class 要实现map方法
1 public void function throws IOException { 2 Configuration conf = new Configuration(); 3 Job job = new Job(conf); 4 job.setJobName("ChianJOb"); 5 // 在ChainMapper里面添加Map1 6 Configuration map1conf = new Configuration(false); 7 ChainMapper.addMapper(job, Map1.class, LongWritable.class, Text.class, 8 Text.class, Text.class, true, map1conf); 9 // 在ChainReduce中加入Reducer,Map2; 10 Configuration reduceConf = new Configuration(false); 11 ChainReducer.setReducer(job, Reduce.class, LongWritable.class, 12 Text.class, Text.class, Text.class, true, map1conf); 13 Configuration map2Conf = new Configuration(); 14 ChainReducer.addMapper(job, Map2.class, LongWritable.class, Text.class, 15 Text.class, Text.class, true, map1conf); 16 job.waitForCompletion(true); 17 }
关键点:
链式,那么什么是链式,链式是mapreduce中存在多个map.
那么是怎么实现的?通过链式ChainMapper和ChainReducer实现。
ChainMapper允许一个Map任务中添加多个Map的子任务,ChainReducer可以在Reducer执行之后,在加入多个Map的子任务。
下面为ChainMapper、ChainReducer:的具体实现。
ChainMapper.addMapper(job, Map1.class, LongWritable.class, Text.class,
Text.class, Text.class, true, map1conf);
ChainReducer.addMapper(job, Map2.class, LongWritable.class, Text.class,
Text.class, Text.class, true, map1conf);
Mapreduce 工作机制图,MapReduce组合式,迭代式,链式
标签:
原文地址:http://www.cnblogs.com/masonwang/p/4534340.html