标签:
全局变量使用具有说明性的名字,局部变量使用短名字。全局变量可以出现在整个程序中的任何地方,因此它们的名字应该足够长,具有足够的说明性。
人们常常鼓励程序员使用长的变量名,而不管用在什么地方。这种认识完全是错误的,清晰性往往是随着简洁而来的。
leap_year = ((y%4 == 0) && (y%100 != 0)) || (y%400 == 0);
避免函数宏
函数宏最常见的一个严重问题是:如果一个参数在定义中出现多次,它就可能被多次求值。下面的实现是错误的。
#define isupper(c) ((c) >= ‘A‘ && (c) <= ‘Z‘)while (isupper( c = getchar()))...
给宏的体和参数都加上括号
神秘的数包括各种常数、数组的大小、字符位置、变换因子以及程序中出现的其它以文字形式写出的数值。
把数定义为常数,不要定义为宏
给函数和全局数据加注释
书写良好的代码更容易阅读和理解,几乎可以保证其中的错误更少。
由于散列表是链接表的数组,其基本元素类型与链表相同。
typedef struct Nameval Nameval;struct Nameval{char *name;int value;Nameval *next; /*in chain */}Nameval *symtab[NHASH]; /* a symbol table*/
数组到底应该取多大?
普遍的想法是要求它足够大,使每个链表至多只有几个元素,以保证查询能够是O(1)操作。
hash函数
对于字符串,最常见的散列算法之一是:逐个把字节加到已经构造的部分散列值的一个倍数上。根据经验,在对于ASCII串的散列函数中,选择31和37作为乘数是很好的。(注:另有times33算法)
enum { MULTIPLIER = 31};/*hash: compute hash value of string*/unsigned int hash(char* str){unsigned int h;unsigned char *p;h = 0;for (p = (unsigned char*)str; *p != ‘\0‘; p++)h = MULTIPLTER * h += *p;return h % NHASH;}
times33经典实现算法
uint nHash = 0;while (*key)nHash = (nHash << 5) + nHash + *key++;return nHash;
对于一类输入集合(例如短的变量名字)工作得非常好的散列函数,也可能对另一类输入集合(例如URL)工作得很差
数据结构是程序构造过程的中心环节。一旦数据结构安排好了,算法就像是瓜熟蒂落,编码也比较容易。
算法描述
设置w1w2为文本的前两个词
输出w1w2
循环:
随机地选出w3,它是文本中w1w2的后缀中的一个
打印w3
把w1w2替换成w2w3
重复循环
下图与上述描述不符,后文的程序是严格按照上面的伪算法描述来写的,没有下图描述的智能。

前缀中词的个数为2(NPREF)。如果将前缀缩短,产生出来的句子将趋向于无聊词语,更加缺乏内聚力;如果加长前缀,则趋向于产生原始输入的逐字拷贝。对于英语文本而言,用两个词的前缀选择第三个是一个很好的折衷方式。
enum {NPREF = 2, /*number of prefix word*/NHASH = 4093, /*size of state hash table array*/MAXGEN = 10000 /*maximum words generated*/};struct State{ /* prefix + suffix list */char *pref[NPREF]; /*prefix words*/Suffix *suf; /*list of suffixes*/State *next; /*next in hash table*/};struct Suffix {/* list of suffixes*/char *word; /*suffix*/Suffix *next; /*next in list of suffixes*/};State *statetab[NHASH]; /*hash table of states*/
整个数据结构看起来是这样的: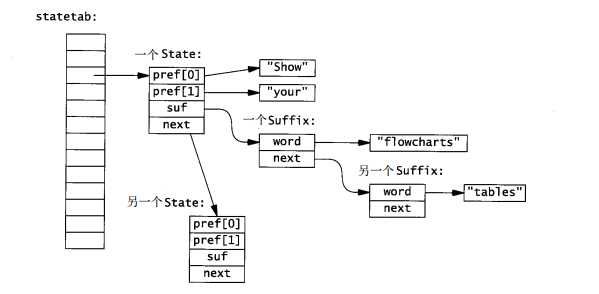
哈希函数对前缀字符串进行散列
查找:
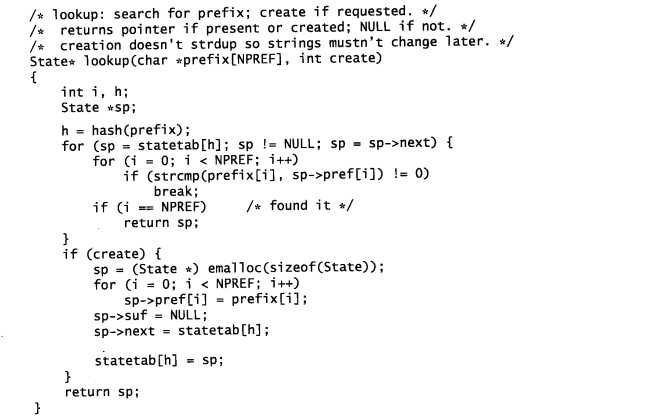
在读入文件的同时构造散列表:
/*build : read input, build prefix table*/void build( char* prefix[NPREF], FILE* f){char buf[100], fmt[10];/* create a format string; %s could overflow buf */sprintf( fmt, "%%%ds", sizeof(buf) - 1);while ( fscanf( f, fmt, buf) != EOF)add( prefix, estrdup(buf));}
说明:以%s作为格式符调用fscanf,那就是要求把文件里的下一个由空白界定的词读入缓冲区。但是,假如在这种情况下没有长度限制,特别长的词就可能导致输入缓冲区溢出,从而酿成大祸。假设 缓冲区的大小 为100个字节(这远远超出正常文本中可能出现的词的长度),我们可以用%99s(留一个字符给串的结束符‘\0‘),这是告诉fscanf读到99个字符就结束。这样做有可能把长的词分成段,虽然是不幸的,但却是安全的。
/*add: add word to suffix list, update prefix */void add(char* prefix[NPREF], char* suffix){State* sp;sp = lookup(prefix, 1); /*create if not found*/addsuffix(sp, suffix);/* move the words down the prefix */memmove(prefix, prefix+1, (NPREF-1)*sizeof(prefix[0]));prefix[NPREF-1] = suffix;}
memmove用于从src拷贝count个字符到dest,如果目标区域和源区域有重叠的话,memmove能够保证源串在被覆盖之前将重叠区域的字节拷贝到目标区域中。但复制后src内容会被更改。但是当目标区域与源区域没有重叠则和memcpy函数功能相同。原型:void memmove( void dest, const void* src, size_t count );
/* addsuffix: add to state, suffix must not change later*/void addsuffix(State* sp, char* suffix){Suffix* suf;suf = (Suffix*)emalloc(sizeof(Suffix));suf->word = suffix;suf->next = sp->suf;sp->suf = suf;}
产生输出
char NONWORD[] = "\n"; /*cannot appear as real word*//* generate: produce output, one word per line */void generate(int nwords){State* sp;Suffix* suf;char* prefix[NPREF],*w;int i, nmatch;for (i = 0; i < NPREF; i++)/* reset initial prefix*/prefix[i] = NONWORD;for (i = 0; i < nwords; i++) {sp = lookup(prefix, 0);nmatch = 0;for ( suf = sp->suf; suf != NULL; suf = suf->next)if (rand() % ++nmatch == 0) /*prob = 1/nmatch */w = suf->word;if (strcmmp(w, NONWORD) == 0)break;printf("%s\n",w);memmove(prefix, prefix+1, (NPREF-1)*sizeof(prefix[0]));prefix[NPREF-1] = w;}}
变量nmatch用于在扫描后缀表的过程中记录匹配的个数。表达式:rand()% ++nmatch == 0增加nmatch的值,而且使它为真的概率总是1/nmatch。在扫描过中,每一个项被选中的概率为1/nmatch。
/* markov main: markov-chain random text generation*/int main(void){int i, nwords = MAXGEN;char* prefix[NPREF]; /*current input prefix*/for (i = 0; i < NPREF; i++) /*set up initial prefix*/prefix[i] = NONWORD;build(prefix, stdin);add(prefix, NONWORD);generate(nwords);return 0;}
C++版
typedef deque<string> Prefix;map<Prefix, vector<string>> statetab; //prefix->suffixes//markov main: markov-chain random text generationint main(void){int nwords = MAXGEN;Prefix prefix; //current input prefixfor ( int i = 0; i < NPREF; i++) //set up initial prefixadd(prefix, NONWORD);build(prefix, cin);add(prefix, NONWORD);generate(nwords);return 0;}//build: read input words , build state tablevoid build(Prefix& prefix, istram& in){string buf;while (in >> buf)add(prefix, buf);}//add: add word to suffix list, update prefixvoid add(Prefix& prefix, const string& s){if (prefix.size() == NPREF) {statetab[prefix].push_back(s);prefix.pop_front();}prefix.push_back(s);}//generate: produce output, one word per linevoid generate(int nwords){Prefix prefix;int i;for ( i = 0; i <NPREF; i++) //reset initial prefixadd(prefix, NONWORD);for ( i = 0; i < nwords; i++) {vector<string>& suf = statetab[prefix];const string& w = suf[rand() % suf.size()];if ( w == NONWORD)break;cout << w << endl;prefix.pop_front(); //advanceprefix.push_back(w);}}
检查最近的改动仔细检查最近的改动能帮助问题定位。
产生无错代码的一个途径是用程序来生成代码如果所用的生成器或者翻译器是正确的,给出的描述完全正确,那么作为结果的程序必然也是正确的。
测试代码的边界情况
测试前条件和后条件验证在某段代码执行前所期望的或必须满足的性质(前条件)、执行的性质(后条件)是否成立。
例如,链表节点为空不能执行->next操作,函数执行后的返回值。
使用断言
如果一个程序有逆计算,那么就检查通过该逆计算能否重新得到输入
比较相互独立的实现,或许你可以写出一个程序的某种简单版本,作为一个慢的但却又是独立的参照物。
度量测试的覆盖面测试的一个目标是保证程序里的每个语句在一系列测试过程中都执行过,如果不能保证程序的每一行都在测试中至少经过了一次执行,那么这个测试就不能说是完全的。
花点时间写一个脚本程序或者一个简单程序,用它包装起来所有的测试是非常值得做的,这能使一个完整的测试集可以通过(文字或者图形)一个按键而得到执行。
自动回归测试回归测试实际上有一个隐含假定,假定程序以前的版本产生的输出是正确的。**
char的符号问题char数据类型到底是有符号的还是无符号的,C和C++并不没有对此给出明确规定。在结合了char和int的代码里,这个问题就有可能造成麻烦,例如getchar()函数得到int值,调用它的代码就会出现问题。
char c; /*should be int*/c = getchar();
如果char是无符号类型,条件s[i] == EOF总为false,EOF在stdio.h里通常定义为-1。如果char是有符号类型,那么代表正常字符的0xFF将会被被视为结束符。
int i;char s[MAX];for (i = 0; i < MAX -1 ; i++)if (( s[i] = getchar()) == ‘\n‘ || s[i] == EOF)break;s[i] = ‘\0‘;
无论char的符号情况如何,你都必须把getchar的返回值存入一个int以便与EOF做比较
int c, i;char s[MAX];for (i = 0; i < MAX -1 ; i++) {if (( c = getchar()) == ‘\n‘ || c == EOF)break;s[i] = c;}s[i] = ‘\0‘;
位域对机器的依赖太强,无论如何都不应该用它。
不要用char与EOF做比较
程序组织达到可移植性的方式,最重要的有两种,我们将它们称为联合的方式和取交集的方式。
联合方式使用各个特殊途径的最佳特征,采用条件式编译和安装,根据各个具体环境的特殊情况进行处理。优点是可以利用各系统在能力方面的优点。缺点是安装过程的规模和复杂性,由代码中大量费解的编译条件造成的复杂性等。
取交集的方式,即:只体表和那些在所有目标系统里都存在的特性,绝不使用那些并不是到处都能用的特征。强求使用普遍可用特性也有危险,这可能限制了目标系统的范围,或者限制了程序的功能。此外,也可能在某些系统里导致性能方面的损失。
把系统依赖性隐藏在界面后面抽象是一种强有力的技术,应该通过它划清程序的可移植性部分与不可移植部分之间的界限。(congnima注:例如java中的File类)
数据交换文本数据很容易从一个系统搬到另一个系统去,这是在不同系统间交换任意信息的最简单方式。
字节序
书中提供了一种比较笨的方法来判断系统的字节序
/* byteorder: display bytes of a long */int main(void){unsigned long x;unsigned char* p;int i;/* 11 22 33 44 => big-endian*//* 44 33 22 11 => little-endian*//* x = 0x1122334455667788UL; for 64-bit long*/x = 0x11223344UL;p = (unsigned char* )&x;for ( i = 0; i < sizeof(long); i++)printf("%x ",*p++);printf("\n");return 0;}
引自《C语言深度剖析》
bool checkSystem(){union chech{int i;char ch;}c;c.i = 1;//return true means little-endianreturn (c.ch == 1);}
采用正确的语言有可能使某个程序的书写变得容易许多。
思考printf及cout各自的优缺点
语法分析树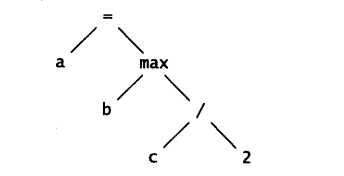
一旦这种树构造好了,我们就有很多可能的方法来处理它。最直接的方法是在树中运动,并在这个过程中求出各个结点的值。
版本1:
typedef struct Symbol Symbol;typedef struct Tree Tree;struct Symbol {int value;char *name;};struct Tree {int op;/*operation code*/int value;/*value if number*/Symbol *symbol;/*Symbol entry if variable*/Tree *left;Tree *right;};/*eval: version 1: evaluate tree expression*/int eval(Tree* t){int left, right;switch (t->op) {case NUMBER:return t->value;case VARIABLE:return t->symbol->value;case ADD:return eval(t->left) + eval(t->right);case DIVIDE:left = eval(t->left);right = eval(t->right_;if (right == 0)eprintf("divide %d by zero",left);return left / right;case MAX:left = eval(t->left);right = eval(t->right);return left>right ? left : right;case ASSIGN:t->left->symbol->value = eval(t->right);return t->left->symbol->value;/*...*/}}
版本2:
/* addop: return sum of two tree expressions */int addop( Tree* t){return eval(t->left) + eval(t->right);}/*...*/enum { /*operation codes, Tree.op*/NUMBER,VARIABLE,ADD,DIVIDE,/*...*/};/* optab: operator function table */int (*optab[])(Tree *) = {pushop, /*NUMBER*/pushsymop, /*VARIABLE*/addop, /*ADD*/divop, /*DIVIDE*//*..*/};/* eval: version 2: evaluate tree from operator table */int eval(Tree *t){return (*optab[t->op])(t);}
上面这个递归函数已经计算了整个语法树
版本3:
typedef union Code Code;union Code {void (*op)(void); /*function if operator*/int value; /*value if number*/Symbol *symbol; /*Symbol entry if variable*/};/*generate: generate instructions by walking tree*/int generate(int codep, Tree* t){switch (t->op) {case NUMBER:code[codep++].op = pushop;code[codep++].value = t->value;return codep;case VARIABLE:code[codep++].op = pushsymop;code[codep++].symbol = t->symbol;return codep;case ADD:codep = generate(codep,t->left);codep = generate(codep,t->right);code[codep++].op = addop;return codep;case DIVIDE:codep = generate(codep,t->left);codep = generate(codep,t->right);code[codep++].op = divop;return codep;case MAX:/*...*/}}Code code[NCODE];int stack[NSTACK];int stackp;int pc; /*program counter*//*eval: version 3: evaluate expression from generated code*/int eval(Tree* t){pc = generate(0,t);code[pc].op = NULL;stackp = 0;pc = 0;while ( code[pc].op != NULL)(*code[pc++].op)();return stack[0];}/*pushop: push number; value is next word in code stream*/void pushop(void){stack[stackp++] = code[pc++].value;};/*divop: compute ratio of two expressions*/void divop(void){int left, right;right = stack[--stackp];left = stack[--stackp];if (0 == right)eprintf("divide %d by zero\n", left);stack[stackp++] = left / right;}
标签:
原文地址:http://www.cnblogs.com/codetravel/p/4534607.html