标签:
网络爬虫基础
通用搜索引擎的处理对象就是互联网网页,目前网页数量以百亿计,所以搜索引擎首先面临的问题就是:如何能够设计出高效的下载系统,以将如此海量的网页数据传送到本地,在本地形成互联网网页的镜像备份。
网络爬虫即起此作用,它是搜索引擎系统中很关键也很基础的构建。本次总结以及接下来的几次总结主要给大家简单介绍一下与网络爬虫相关的技术。说到爬虫,又想到了Python,所以首先了解一下爬虫的简单机制,这样对学习Python爬虫会有很大的帮助。
如图所示
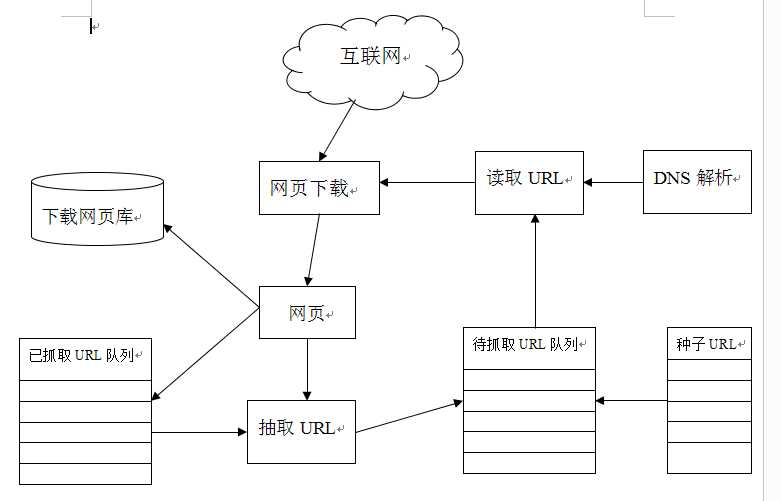
这是一个通用的爬虫框架流程。
首先从互联网页面中精心选择一部分网页,以这些网页的链接地址作为种子URL,将这些种子URL放入待抓取URL队列中,爬虫从待抓取URL队列依次读取,并将URL通过DNS解析,把链接地址转换成为网站服务器对应的IP地址。然后将其和网页相对路径名称交给网页下载器,网页下载器负责页面内容的下载。对于下载到本地的网页,一方面将其存储到页面库中,等待建立索引等后续处理;另一方面将下载网页的URL放入已抓取URL队列中,这个队列记载了爬虫系统已经下载过的网页URL,以避免网页的重复抓取。对于刚下载的网页,从中抽取出所包含的所有链接信息,并在已抓取URL队列中检查,如果发现链接还没有被抓取过,则将这个URL放入待抓取URL队列末尾,在之后的抓取调度中会下载这个URL对应的网页。这样一直进行下去,直到待抓取URL队列为空,这就代表着爬虫系统已将能够抓取的网页尽数抓完,此时完成了一轮完整的抓取过程。
对于爬虫来说,往往还需要进行网页去重以及网页反作弊(我的读书笔记一中的插图有提到反作弊),而且这是非常重要的一个过滤过程,在这里,我先不讲解反作弊,后面我会慢慢讲解给大家(因为此时的我也不懂反作弊的原理,还在进一步的学习中,所以抱歉)。
上述是一个通用爬虫的整体流程,读完想想还是蛮简单的,我们可以想象成为一只蜘蛛在蜘蛛网上爬行。这里我们再总结一下上述的那段话,宏观角度看爬虫抓取过程中与互联网网页之间的关系可以分为以下5种:
已下载网页集合:爬虫已经从互联网下载到本地进行索引的网页集合。
已过期网页集合:由于网页数量巨大,爬虫完整抓取一轮需要较长时间,在抓取过程中,很多已经下载的网页可能过期。之所以如此,是因为互联网网页处于不断的更新状态中,所以容易产生本地网页中内容和真实互联网里网页的内容不一致的情况。
待下载网页集合:即处于待抓取URL队列中的网页,这些网页即将被爬虫下载。
可知网页集合:这些网页还没有被爬虫下载,也没有出现在待抓取URL队列中,不过通过已经抓取的网页或者在待抓取URL队列中的网页,总是能够通过链接关系发现它们,稍晚时候会被爬虫抓取并索引。
不可知网页集合:有些网页对于爬虫来说是无法抓取到的,这部分网页构成了不可知网页集合。事实上,这部分的网页所占的比例还是很高的。
现在,我们已经知道了通用的爬虫框架,绝大多数爬虫系统遵循此流程,但是并非意味着所有爬虫都如此。大体而言,可以将爬虫划分为3中类型:
批量型爬虫:批量性爬虫有比较明确的抓取范围和目标,当爬虫达到这个设定的目标后,即停止抓取过程。至于具体目标可能各异,也许是设定抓取一定数量的网页即可,也许是设定抓取消耗的时间等。
增量型爬虫:这种爬虫系统会不断地抓取,对于抓取到的网页,要定期更新,因为互联网网页处于不断变化中,新增网页、网页被删除或者网页内容更改都很常见,而增量型爬虫需要及时反映这种情况和变化,所以要处于持续不断的抓取过程中。
垂直型爬虫:垂直型爬虫关注特定主题内容或者属于特定行业的网页,比如对于体育网站来说,就只需要从互联网页面里找到和体育相关的页面内容即可,其他行业的内容不在考虑范围里。
爬虫系统和算法设计有一样的道理,如果设计的不是很好,那么不能算作一套优秀的爬虫系统,那么,优秀的爬虫系统具有什么样的特性呢?
高性能
互联网的网页数量庞大如海,所以爬虫的性能至关重要,这里的性能主要是指爬虫下载网页的抓取速度,常见的评价方式是以爬虫每秒能够下载的网页数量作为性能指标,单位时间能够下载的网页数量越多,爬虫的性能就越高。
还有一个方面也是凸显出高性能的特点,那就是爬虫系统得具有针对性。刚才我们有说到爬虫系统需要不断抓取,实时更新,那么如果我们用一套爬虫系统来抓取内容更新速度慢的网页和内容更新速度快的网页,是不是没有那么高效。此时,我们可以采用两套爬虫系统,一套爬虫系统针对更新较慢的网页集合,我们可以以天作为更新周期,另一套爬虫系统针对更新较快的网页集合,我们以秒作为更新周期。这样,明显比只用一套爬虫系统的情况下的性能高的多。
可扩展性
爬虫需要抓取的网页数量巨大,即使单个爬虫的性能很高,要将所有网页都下载到本地,仍然需要相当长的时间周期,为了能够尽可能的缩短抓取周期,爬虫系统应该有很好的可扩展性,即很容易通过增加抓取服务器和爬虫数量来达到目的。
健壮性
不光只有算法设计出现错误时会死循环,爬虫在访问各种类型的网站服务器时,也有可能会遇到很多种非正常状况,比如网页HTML编写不规范,被抓取服务器突然死机,甚至是爬虫陷阱等等。那么在这些情况下,健壮的爬虫系统应该是怎么样的呢?当爬虫程序死掉时,我们再次启动爬虫,能够恢复之前抓取的内容和数据结构,而不是每次都需要把所有工作完全从头做起。
友好性
爬虫的友好性包含两个方面的含义:一是保护网站的部分隐私性,另一方面就是尽量减少被抓取网站的网络负荷。
爬虫抓取的对象是各种类型的网站,对于网站拥有者来说,有些内容并不希望被所有人搜索到,所以需要设定协议来告知爬虫哪些内容是不允许抓取的。目前有两种流行的方法:爬虫禁抓协议和网页禁抓协议。
爬虫技术是一种非常考验实战的技术,如果想要熟悉或了解搜索引擎,那么爬虫应该是必须要学会的。在不久的日子里,我会结合所学的Python基础知识来和大家一起学习Python爬虫。
零搜索引擎经验,零爬虫经验,初手有谦逊的态度和一颗热爱技术的心。
加油!
标签:
原文地址:http://www.cnblogs.com/BaiYiShaoNian/p/4536446.html