标签:
本文目的
当前spark(1.3版)随机森林实现,没有包括OOB错误评估和变量权重计算。而这两个功能在实际工作中比较常用。OOB错误评估可以代替交叉检验,评估模型整体结果,避免交叉检验带来的计算开销。现在的数据集,变量动辄成百上千,变量权重有助于变量过滤,去掉无用变量,提高计算效率,同时也可以帮助理解业务。所以,本人在原始代码基础上,扩展了这两个功能,下面记录实现过程,作为备忘录(参考代码)。
整体思路
Random Forest实现中,大多数内部对象是私有(private[tree])的,所以扩展代码使用了org.apache.spark.mllib.tree的命名空间,复用这些内部对象。实现过程中,需要放回抽样数据,Random Forest的原始实现是放在局部变量baggedInput中,外部无法访问,所以扩展代码必须冗余部分原始代码,用于访问baggedInput变量。原始实现中,会先将LabeledPoint转成装箱对象TreePoint,但是在计算OOB时,需要LabeledPoint,所以需要实现TreePoint到LabeledPoint的转换逻辑。对于连续变量,取每个箱的中间值作为反转后的结果;离散变量不需要做修改。当然为什么取中间值,为什么取三分之一或其他什么地方?因为在装箱过程中,数据的分布信息已丢失,所以取0.5是一个可以接受的选择。
OOB错误评估
原理
OOB是Out-Of-Bag的缩写,顾名思义,使用那些out of bag的数据进行错误度量。随机森林在训练开始时,会根据树的数量n,进行n次有放回采样,用于训练每一棵树。放回采样,必然导致一部分数据被选中,另外一部分数据没有选中,选中了就放到bag中,没有选中的就是out of bag。平均而言,每次放回采用中,37%的数据不会被选中,详细推导见附录【Out Of Bag概率】。这些没有选中的数据不参与建模,所以可以作为验证数据,评估模型效果。对于每一条记录,若参与了m棵树的建模,则n-m树没有参与建模,那么就可以将这剩下的n-m棵树作为子森林,进行分类验证,列子如下:
|
Tree 1 |
Tree 2 |
Tree 3 |
Tree 4 |
Tree 5 |
Tree 6 |
Tree 7 |
|
|
Data 1 |
* |
* |
* |
||||
|
Data 2 |
* |
* |
* |
* |
|||
|
Data 3 |
* |
* |
* |
||||
|
Data 4 |
* |
* |
* |
* |
|||
|
Data 5 |
* |
* |
* |
上面的表格中,每行表示一个记录,每列表示一颗树,"*"表示该记录参与了某棵树的建模。对于Data 1,参与了Tree 2,4,6的建模过程,那么可选取Tree 3,5,7作为子随机森林模型,并计算Data 1的分类结果。
实现
上面提到了OOB的原理和评估方法,下面介绍如何实现,
|
private def computeOobError( strategy: Strategy, baggedInput: RDD[BaggedPoint[TreePoint]], bins: EnhancedRandomForest.BinList, forest: RandomForestModel): Double = {
val actualPredictPair = baggedInput .map(x => { val labeledPoint = EnhancedTreePoint.treePointToLabeledPoint( x.datum, bins, strategy) (x.subsampleWeights.zipWithIndex.filter(_._1 == 0) .map(_._2).map(index => forest.trees(index)), labeledPoint) }) .filter(_._1.size > 0) // 过滤掉无树的森林 .map({ case (oobTrees, labeledPoint) => { val subForest = new RandomForestModel(strategy.algo, oobTrees) (labeledPoint.label, subForest.predict(labeledPoint.features)) } })
val totalCount = actualPredictPair.count assert(totalCount > 0, s"OOB error measure: data number is zeror") strategy.algo match { case Regression => actualPredictPair.map(x => Math.pow(x._1 - x._2, 2)).reduce(_ + _) / totalCount case Classification => actualPredictPair.filter(x => x._1 != x._2).count.toDouble / totalCount }
} |
上面函数截取了oob实现的主逻辑,baggedInput是一个特殊的数据结构,用于记录每一条记录选中的信息。比如需要建立10棵树,那么bagged有10列,每一列记录了在当前这棵树,该记录被选中了几次。所以,使用0标示那些没有选中的记录。得到了那些当前数据没有参与建模的树后,构建字随机森林模型并预测结果,最后通过真实数据与预测数据,计算OOB错误评估。对于回归问题,使用平方错误;分类问题,使用错误率。当然,错误的评估方式,后面还可以扩展。
变量重要性
原理
如何描述变量重要性,一种直观的理解是变量越重要,如果混淆它,那么模型效果会越差。混淆处理有几种方案,比如根据某种随机分布,加减随机值,或者随机填充值。但是需要额外的参数,并且会影响原有的数据分布。所以,采取随机排序混淆变量,这样不会改变原始的数据分布,也不需要而外的参数。
具体做法是如下:
I(i)越高,说明变量i越重要;如果I(i) = 0,那么说明变量i没有什么作用;如果I(i) < 0,那么说明变量i有很明显的噪音,对模型产生了负面影响。
实现
实现的难点是随机排序,在大规模分布式数据上,实现随机排序至少需要一次排序,会非常消耗计算资源。扩展代码中使用了一个小技巧,利用spark随机森林的内部结构TreePoint,避免排序,提高随机排序效率。因为TreePoint是装箱数据,每个变量的值是箱索引,一般不超过100个。所以只需要将箱索引进行随机排序,就可以达到对整个数据进行随机排序的目的。
|
private def computeVariableImportance( strategy: Strategy, baggedInput: RDD[BaggedPoint[TreePoint]], bins: EnhancedRandomForest.BinList, forest: RandomForestModel, oobError: Double): Array[Double] = {
(0 until bins.size).par.map(featureIndex => {
val binCount = if (strategy.categoricalFeaturesInfo.contains(featureIndex)) { // category feature strategy.categoricalFeaturesInfo(featureIndex) } else { // continuous feature bins(featureIndex).size } val shuffleBinFeature = Random.shuffle((0 until binCount).toList) // 每个元素对应shuffle后的数据 val shuffleOneFeatureBaggedInput = baggedInput.map(x => { val currentFeatureBinIndex = x.datum.binnedFeatures(featureIndex) x.datum.binnedFeatures(featureIndex) = shuffleBinFeature(currentFeatureBinIndex) x }) computeOobError(strategy, shuffleOneFeatureBaggedInput, bins, forest) - oobError }).toArray
} |
上面的使用中,使用list.par.map的并发操作,同时对所有的变量计算重要性,具体的调度有spark服务器控制,最大限度利用spark的资源。
聚合模型稳定的理论依据
随机森林背后的主要思想是聚合模型(Ensemble Model)。为什么聚合模型效果好于单一模型(理论推导,请参考附录【聚合模型错误评估】)?直观的理解,当很多模型进行投票时,有一些模型会犯错,另外一些模型正确,那么正确的投票会与错误的投票抵消,整体上只要最终正确的投票多于错误的投票,哪怕多一票,那么就会得到正确的结果。由于相互抵消,所以聚合效果比单一模型稳定。聚合模型中,需要模型间具有较大差异,这样才能覆盖数据的不同方面,这也是为什么随机森林在数据的行和列两个维度上,添加随机过程,用于增大模型之间的差异。
引用一句谚语,"三个臭皮匠,顶一个诸葛亮",可以形象的解释。比如这里有101个臭皮匠,假设他们对一件事情的判断正确的概率是0.57,而诸葛亮对这件事情判断正确的概率是0.9。那么,假设这101个臭皮匠通过投票判断,那么概率可以达到0.92(R代码:sum(dbinom(51:101,101,0.57))),比诸葛亮强!
总结
通过扩展这两个功能,重新温习了台大《机器学习技法》相关课程,同时在真实数据上检验了Random Forest的模型效果。实践检验了整理,学以致用,感觉很满足。同时,在阅读org.apache.spark.mllib.tree源代码的时候,学习到了一些分布式数据集上算法实现的技巧。希望这些分享对你有用。
参考资料
附录
Out Of Bag概率
设N为样本大小,那么N次有放回抽样中,一次没有选中的概率可以表示如下,
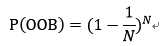
当N趋近于无求大时,P(OOB)会收敛到常量,下面给出证明,
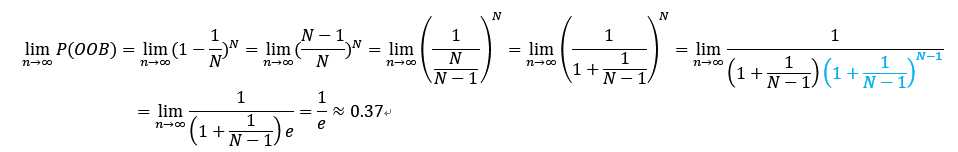
其中数学常数定义如下:
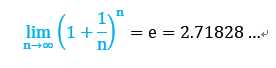
聚合模型错误评估
下面通过聚合回归模型进行简单推导,gt是相同数据集D中,使用T个算法生成的T个模型中随机选择的一个模型,G是这T个模型聚合,使用平均作为最终结果,有
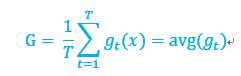
f模型用于生成数据D,需要用T个机器学习算法逼近。现在期望研究(G(x)-f(x))2与avg((gt(x)-f(x))2)的关系。x是固定值,后面的公式为了简单,会省略。
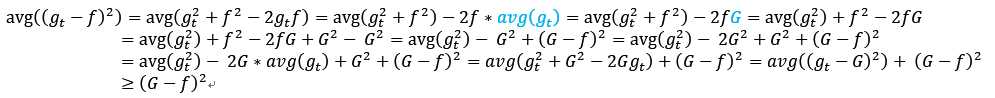
直观的理解,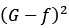 是偏差(Bias),
是偏差(Bias),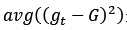 是方差(Variance),任意单一模型的平方错误期望大于等于平均模型的错误的平方。而且,模型差异如果越大,那么方差variance越大,那么Bias越小,也就是聚合模型与f越接近。
是方差(Variance),任意单一模型的平方错误期望大于等于平均模型的错误的平方。而且,模型差异如果越大,那么方差variance越大,那么Bias越小,也就是聚合模型与f越接近。
标签:
原文地址:http://www.cnblogs.com/bourneli/p/4536778.html