标签:
CUDA是并行计算的平台和类C编程模型,我们能很容易的实现并行算法,就像写C代码一样。只要配备的NVIDIA GPU,就可以在许多设备上运行你的并行程序,无论是台式机、笔记本抑或平板电脑。熟悉C语言可以帮助你尽快掌握CUDA。
CUDA编程允许你的程序执行在异构系统上,即CUP和GPU,二者有各自的存储空间,并由PCI-Express 总线区分开。因此,我们应该先注意二者术语上的区分:
代码中,一般用h_前缀表示host memory,d_表示device memory。
kernel是CUDA编程中的关键,他是跑在GPU的代码,用标示符__global__注明。
host可以独立于host进行大部分操作。当一个kernel启动后,控制权会立刻返还给CPU来执行其他额外的任务。所以,CUDA编程是异步的。一个典型的CUDA程序包含由并行代码补足的串行代码,串行代码由host执行,并行代码在device中执行。host端代码是标准C,device是CUDA C代码。我们可以把所有代码放到一个单独的源文件,也可以使用多个文件或库。NVIDIA C编译器(nvcc)可以编译host和device生成可执行程序。
这里再次说明下CUDA程序的处理流程:
cuda程序将系统区分成host和device,二者有各自的memory。kernel可以操作device memory,为了能很好的控制device端内存,CUDA提供了几个内存操作函数:
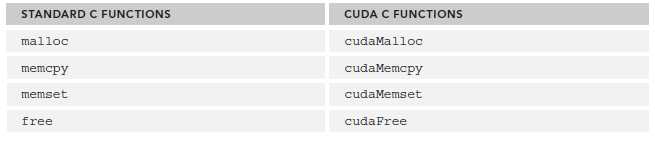
为了保证和易于学习,CUDA C 的风格跟C很接近,比如:
cudaError_t cudaMalloc ( void** devPtr, size_t size )
我们主要看看cudaMencpy,其函数原型为:
cudaError_t cudaMemcpy ( void* dst, const void* src, size_t count,cudaMemcpyKind kind )
其中cudaMemcpykind的可选类型有:
具体含义很好懂,就不多做解释了。
对于返回类型cudaError_t,如果正确调用,则返回cudaSuccess,否则返回cudaErrorMemoryAllocation。可以使用char* cudaGetErrorString(cudaError_t error)将其转化为易于理解的格式。
掌握如何组织线程是CUDA编程的重要部分。CUDA线程分成Grid和Block两个层次。
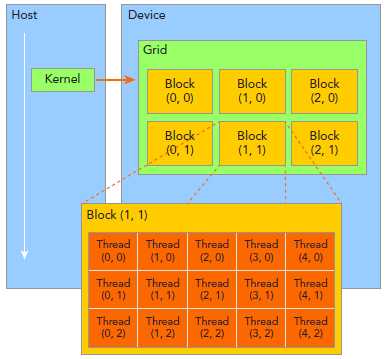
由一个单独的kernel启动的所有线程组成一个grid,grid中所有线程共享global memory。一个grid由许多block组成,block由许多线程组成,grid和block都可以是一维二维或者三维,上图是一个二维grid和二维block。
这里介绍几个CUDA内置变量:
一般会把grid组织成2D,block为3D。grid和block都使用dim3作为声明,例如:
dim3 block(3); // 后续博文会解释为何这样写grid dim3 grid((nElem+block.x-1)/block.x);
需要注意的是,dim3仅为host端可见,其对应的device端类型为uint3。
标签:
原文地址:http://www.cnblogs.com/1024incn/p/4537177.html