标签:
转http://coolshell.cn/articles/11609.html
滑动窗口 -- 表征发送端和接收端的接收能力
拥塞窗口-- 表征中间设备的传输能力
需要说明一下,如果你不了解TCP的滑动窗口这个事,你等于不了解TCP协议。我们都知道,TCP必需要解决的可靠传输以及包乱序(reordering)的问题,所以,TCP必需要知道网络实际的数据处理带宽或是数据处理速度,这样才不会引起网络拥塞,导致丢包。
所以,TCP引入了一些技术和设计来做网络流控,Sliding Window是其中一个技术。 前面我们说过,TCP头里有一个字段叫Window,又叫Advertised-Window,这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。 为了说明滑动窗口,我们需要先看一下TCP缓冲区的一些数据结构:
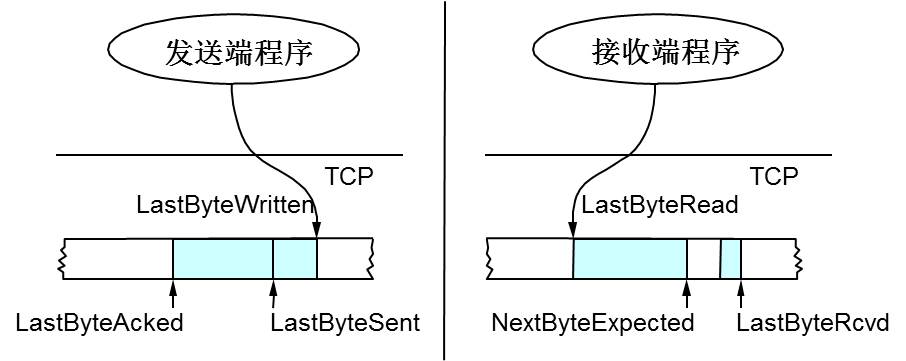
上图中,我们可以看到:
于是:
下面我们来看一下发送方的滑动窗口示意图:
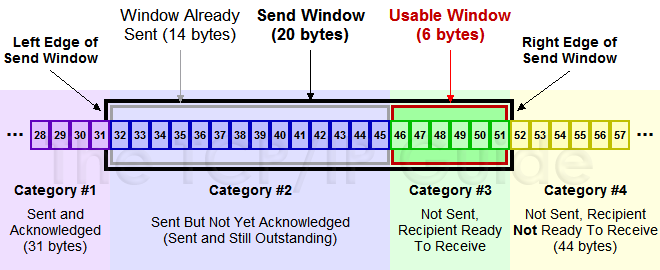
(图片来源)
上图中分成了四个部分,分别是:(其中那个黑模型就是滑动窗口)
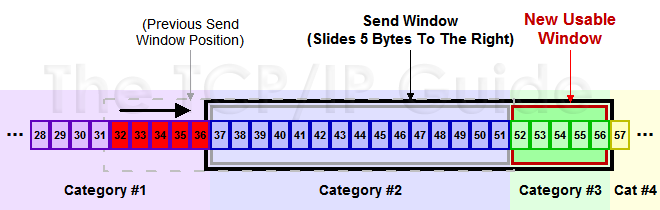
下面是个滑动后的示意图(收到36的ack,并发出了46-51的字节):
下面我们来看一个接受端控制发送端的图示:
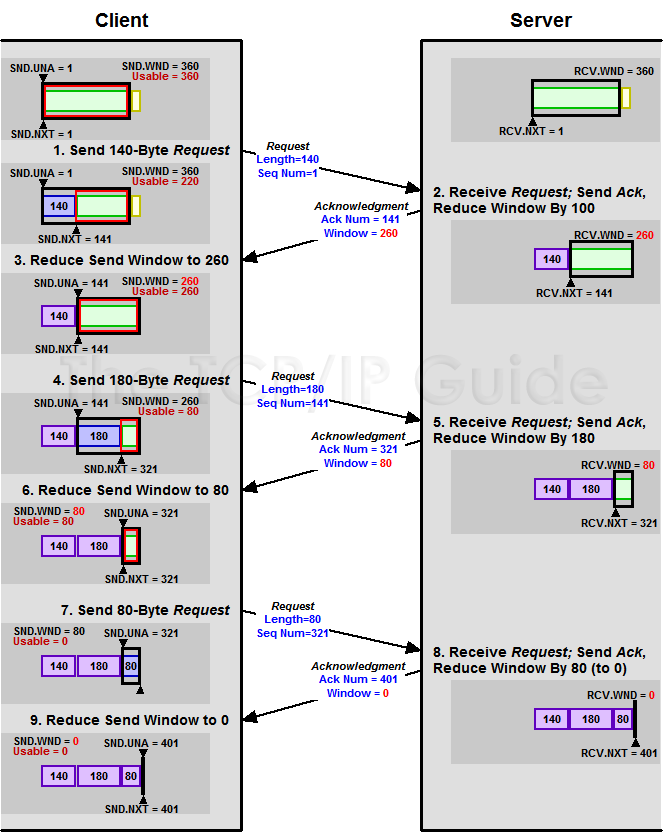
上面我们知道了,TCP通过Sliding Window来做流控(Flow Control),但是TCP觉得这还不够,因为Sliding Window需要依赖于连接的发送端和接收端,其并不知道网络中间发生了什么。TCP的设计者觉得,一个伟大而牛逼的协议仅仅做到流控并不够,因为流控只是网络模型4层以上的事,TCP的还应该更聪明地知道整个网络上的事。
具体一点,我们知道TCP通过一个timer采样了RTT并计算RTO,但是,如果网络上的延时突然增加,那么,TCP对这个事做出的应对只有重传数据,但是,重传会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,于是,这个情况就会进入恶性循环被不断地放大。试想一下,如果一个网络内有成千上万的TCP连接都这么行事,那么马上就会形成“网络风暴”,TCP这个协议就会拖垮整个网络。这是一个灾难。
所以,TCP不能忽略网络上发生的事情,而无脑地一个劲地重发数据,对网络造成更大的伤害。对此TCP的设计理念是:TCP不是一个自私的协议,当拥塞发生的时候,要做自我牺牲。就像交通阻塞一样,每个车都应该把路让出来,而不要再去抢路了。
关于拥塞控制的论文请参看《Congestion Avoidance and Control》(PDF)
拥塞控制主要是四个算法:1)慢启动,2)拥塞避免,3)拥塞发生,4)快速恢复。这四个算法不是一天都搞出来的,这个四算法的发展经历了很多时间,到今天都还在优化中。 备注:
首先,我们来看一下TCP的慢热启动。慢启动的意思是,刚刚加入网络的连接,一点一点地提速,不要一上来就像那些特权车一样霸道地把路占满。新同学上高速还是要慢一点,不要把已经在高速上的秩序给搞乱了。
慢启动的算法如下(cwnd全称Congestion Window):
1)连接建好的开始先初始化cwnd = 1,表明可以传一个MSS大小的数据。
2)每当收到一个ACK,cwnd++; 呈线性上升
3)每当过了一个RTT,cwnd = cwnd*2; 呈指数让升
4)还有一个ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”(后面会说这个算法)
所以,我们可以看到,如果网速很快的话,ACK也会返回得快,RTT也会短,那么,这个慢启动就一点也不慢。下图说明了这个过程。
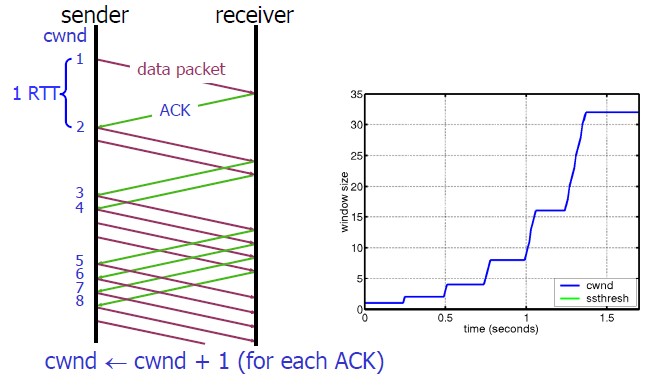
这里,我需要提一下的是一篇Google的论文《An Argument for Increasing TCP’s Initial Congestion Window》Linux 3.0后采用了这篇论文的建议——把cwnd 初始化成了 10个MSS。 而Linux 3.0以前,比如2.6,Linux采用了RFC3390,cwnd是跟MSS的值来变的,如果MSS< 1095,则cwnd = 4;如果MSS>2190,则cwnd=2;其它情况下,则是3。
前面说过,还有一个ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”。一般来说ssthresh的值是65535,单位是字节,当cwnd达到这个值时后,算法如下:
1)收到一个ACK时,cwnd = cwnd + 1/cwnd
2)当每过一个RTT时,cwnd = cwnd + 1
这样就可以避免增长过快导致网络拥塞,慢慢的增加调整到网络的最佳值。很明显,是一个线性上升的算法。
前面我们说过,当丢包的时候,会有两种情况:
1)等到RTO超时,重传数据包。TCP认为这种情况太糟糕,反应也很强烈。
2)Fast Retransmit算法,也就是在收到3个duplicate ACK时就开启重传,而不用等到RTO超时。
上面我们可以看到RTO超时后,sshthresh会变成cwnd的一半,这意味着,如果cwnd<=sshthresh时出现的丢包,那么TCP的sshthresh就会减了一半,然后等cwnd又很快地以指数级增涨爬到这个地方时,就会成慢慢的线性增涨。我们可以看到,TCP是怎么通过这种强烈地震荡快速而小心得找到网站流量的平衡点的。
TCP Reno
这个算法定义在RFC5681。快速重传和快速恢复算法一般同时使用。快速恢复算法是认为,你还有3个Duplicated Acks说明网络也不那么糟糕,所以没有必要像RTO超时那么强烈。 注意,正如前面所说,进入Fast Recovery之前,cwnd 和 sshthresh已被更新:
然后,真正的Fast Recovery算法如下:
如果你仔细思考一下上面的这个算法,你就会知道,上面这个算法也有问题,那就是——它依赖于3个重复的Acks。注意,3个重复的Acks并不代表只丢了一个数据包,很有可能是丢了好多包。但这个算法只会重传一个,而剩下的那些包只能等到RTO超时,于是,进入了恶梦模式——超时一个窗口就减半一下,多个超时会超成TCP的传输速度呈级数下降,而且也不会触发Fast Recovery算法了。
通常来说,正如我们前面所说的,SACK或D-SACK的方法可以让Fast Recovery或Sender在做决定时更聪明一些,但是并不是所有的TCP的实现都支持SACK(SACK需要两端都支持),所以,需要一个没有SACK的解决方案。而通过SACK进行拥塞控制的算法是FACK(后面会讲)
TCP New Reno
于是,1995年,TCP New Reno(参见 RFC 6582 )算法提出来,主要就是在没有SACK的支持下改进Fast Recovery算法的——
我们可以看到,这个“Fast Recovery的变更”是一个非常激进的玩法,他同时延长了Fast Retransmit和Fast Recovery的过程。
下面我们来看一个简单的图示以同时看一下上面的各种算法的样子:
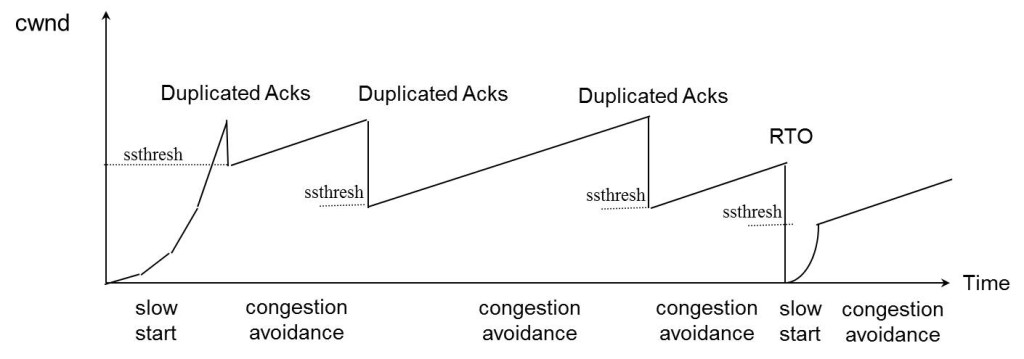
标签:
原文地址:http://www.cnblogs.com/diegodu/p/4538897.html