这篇文章将讨论:
1) 分治策略的思想和理论
2) 几个分治策略的例子:合并排序,快速排序,折半查找,二叉遍历树及其相关特性。
说明:这几个例子在前面都写过了,这里又拿出来,从算法设计的策略的角度把它们放在一起来比较,看看分治是如何实现滴。
由于内容太多,我将再花一篇文章来写4个之前没有写过的分治算法:1,大整数乘法 2,矩阵乘法的分治策略 3,最近点对 4,凸包问题,请见下一篇。
好了,切入正题。
---------------------------------------------------------------------------------------------------------------------------------------------------
分治算法是按照下列方案来工作的:
1)将问题的实例划分为几个较小的实例,最好具有相等的规模(事实上,一般来说就是这样来分的,而且分为2个实例的居多,注意是递归的分!!!)
2)对这些较小的实例求解(一般使用递归的方法,但在问题规模足够小的时候也可以采用采用另一个算法(停止递归))
3)如果有必要的话,合并这些较小问题的解,以得到原始问题的解(事实上,一个分治算法的精华就在于合并解的过程)
不要忽视这三句话!!!它是许多分治算法经验的总结,有助于在分析问题中考虑如何去使用分治算法,提请注意括号里我的注释!!!
形象的表示一下,截张图: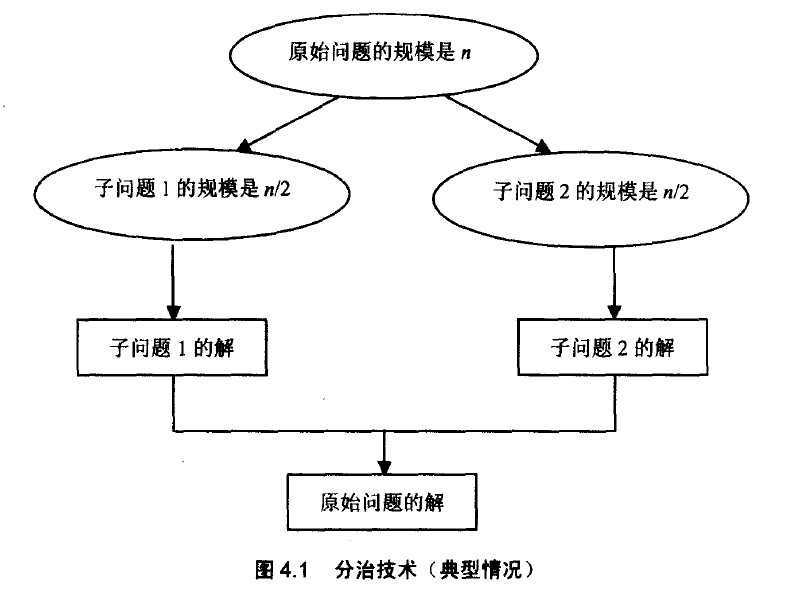
大多数都是规模为n的问题,被划分为2个规模为n/2的问题,更一般的情况下,从理论上分析一下:
一个规模为n的实例可以划分为b个规模为n/b的实例,其中a个实例是需要求解的,为了简化分析,我们假设n是b的幂(每次都可以整的划分),对算法的运行时间,下面的递推关系式是显然的: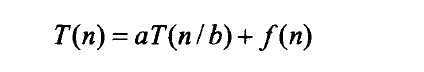
其中,a,b的含义已经说过了,f(n)表示将求解得到的a个子问题的解合并起来所需要的时间复杂度。
如何根据a,b以及f的阶来确定这个算法的时间复杂度呢?有下列主定理:(证明参见算法导论)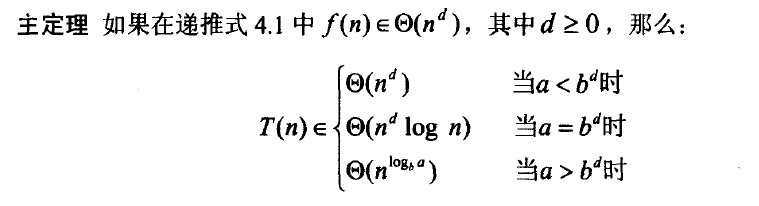
看起来似乎是有一点复杂,证明又比较复杂,这样的式子又不好记。看到这个我也觉得茫然。好吧,根据自己的理解,我来做一点解析,挖掘一下这个式子:
1)b,a,f(n)的含义,这个要弄清楚,要不然恐怕你是无法记住这个结论的。
2)这个式子是一个通用的数学表达式,在计算机的常用算法策略中,它太概括了,我们往往用到的只是它范围很小的一部分。
分析1:a和b的关系,其实a绝大多数时候都是等于b的吧(因为规模n划分为了b个子规模,需要处理的是a个,参见a,b的含义),a,b的含义告诉我们a <= b(当这是最基本要满足的条件)。常常要么是 a==b(分成的子规模都要处理,然后去合并),要么是a==1(实际上这是减治的思想,分成了b个子规模,但最终却可以排除其他的,只在其中一个子规模中去处理)。一般来说就是这样,所以a,b并不是随意的。
分析2:其实b要么为2(几乎所有情况)要么为3(极少数情况)吧,这个分治思想里面就说啦,一般来说都是分为2个规模相等的子规模(当然谁都想分的越多越好,这样算法就更快,但是现实是问题往往没有那么高效的算法,找到一个3的分治就已经很不错了)
分析3:由上面2条可知,a,b的值几乎就那么几个(当然我说的是几乎所有书上可以看到的常见算法案例),所以不用那么担心。
分析4:f(n)是线性的的情况很多(即d=1的情况是最多的)。再来看看a和b^d比较大小的关系说明了什么:f(n)代表的是合并的复杂度,1<=a <= b,定性的分析,可以知道:
第一种情况:a < b^d
因为1<=a <= b,所以只要d>1,不管a,b是什么(不管怎么划分规模,也不关需要处理几个规模),总是第一种情况,时间复杂度是n^d。
如果d=1呢,只要a < b(处理的比划分的少),那么还是第一种情况,时间复杂度也是n^d = n
第二种情况:a = b^d
因为1<=a <= b,所以如果a=b(划分多少处理多少),那么d只能为1才能是这种情况。-----常见的归并排序都是这样
而如果a < b,那b就只能<1才能是这种情况,一般很少见。
第三种情况:a > b^d
非常少见,我还木有见过这样的算法,一开始我认为这种情况不可能,但在理论上它是存在的。因为1<=a <= b,所以要满足这个式子d必须<1 。
从这也可以看出这三个参数之间的关系,事实上是划分的复杂度和合并的复杂度在争抢复杂度的控制权。
说了这么多,感觉越分析越复杂了吗,其实不是,把这些分析想清楚,对递推式的理解就更进一步了,有了上述分析,其实下面几个常见的递推式就包含了大多数的算法:
T(n) = a * T(n/b) + f(n)的常见式子:
1) T(n) = 2 * T(n/2) + O(n) 时间复杂度n*log(n)
一般来说分治算法就是这样,分成2个子规模的问题,需要处理的也是2个,对这两个子规模合并又是线性的
a = b = 2, d = 1; a == b^d 由主定理得n*log(n)
只要a=b,d=1,就都是这个复杂度
2) T(n) = T(n/2) + O(n) 时间复杂度为n,线性的
a = 1,b = 2,d=1(分为2个子规模,但只对一个子规模处理,合并也是线性的)
a < b^d, 时间复杂度是n^d = n
其实质押a < b,d=1,都是这个。
感觉对一个定理解读了这么多,确实让它变得更加复杂了,但如果你做了上述思考,相信对这个式子认识也更加深刻了一点。当然,如果你觉得直接记住上面这个公式就可以了,可以无视以上解读。
----------------------------------------------------------------------------------------------------------------------------------------------------
4.1 合并排序
数据结构里面写过了,再从分治实现策略的角度想一想:
合并排序递归的将规模n分为2个子规模,对2个子规模分别排好序后(划分并处理),再来合并这2个子规模为有序(合并解)。
其递推关系式是这样的: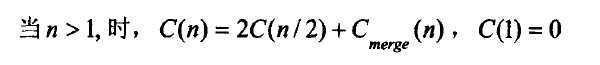
合并解的过程是线性的,即: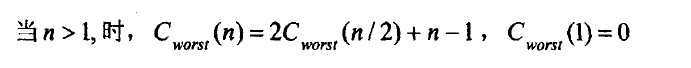
由主定理得,时间复杂度是n * logn的。
几道习题的思考:
7,合并排序稳定吗?yes
10,也可以不用递归的方法来实现合并排序,合并排序是采用递归从上往下构造,我们也可以合并2个相邻序列从底向上构造。这样就需要不断地申请一个大的数组,把当前相邻的2个部分合并起来,直到整个合并。
--------------------------------------------------------------------------------------------------------------------------------------------------
4.2 快速排序
前面数据结构里写过了,从分治实现策略的解读来看看:
归并排序是按照元素在数组里的位置来对它们进行划分的,而快速排序是按照元素的值对它们进行划分。
递推关系式: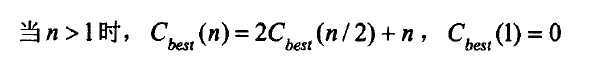
根据主定理得知,时间复杂度和归并排序一样。
1)其关键在于寻找分裂位置!!!!(2个指针左右扫描,交换。注意这种方法)
2)学会快排采用的分区这种思想。
几道习题的思考:
3,快排稳定吗? ---- no
8,将一个乱序数组排成所有负数在正数之前。-----借用快排2个指针左右扫描交换的思想,线性时间内完成
9,荷兰国旗问题------分区思想
---------------------------------------------------------------------------------------------------------------------------------------------------
4.3 折半查找
前面数据结构写过了,从分治策略的角度看看:
对有序数组采用折半查找:递归和非递归实现都比较简单。
分治的递推式: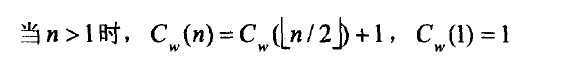
根据主定理,它的复杂度是logn。
实际上分治算法一般是分成了几个子规模就对这几个子规模处理然后合并结果,然而折半查找分成了2个子规模,每次却总能排除一个子规模,只对一个子规模进行处理,准确的说,它是一种减治策略。或者说可以把它看做是分治算法的退化。
--------------------------------------------------------------------------------------------------------------------------------------------------
4.4 二叉树遍历及相关特性
很多算法也在前面写过了,还是从分治策略的角度再来看看它的一些特性:
二叉树的定义本身(参见一般的数据结构书),把一颗二叉树递归的定义为了左右子树构成的树。这意味着,分治法是典型可以用于解决二叉树相关问题的策略。
来看看可以做些什么:
1)计算二叉树的高度

注意初始条件是判断是否为空集返回一个 -1,后面有一个习题说是否可以写成返回0,然后else里面不加1。这是不行的!!这样没有考虑单节点的情况。
它的递推关系式:
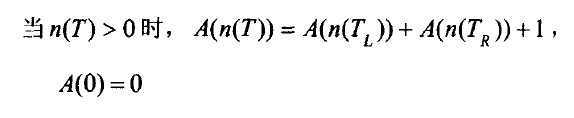
你能由这个递归关系给出它的时间复杂度吗?想想~
事实上,可以简化它为A(n) = 2 * A(n / 2) + 1 -------把左右的处理当做一个数量级,不会影响复杂度,根据主定理,它是O(n)的。
来看看怎么证明它吧----》
参见第 2)点
2)应当指出,加法并不是上述算法中执行最多的次数,每得到一个左子树和右子树,才执行一次加法(先求max,再执行+1),而比较次数(指检查树是否为空,即if语句)显然不止一次(要判断根节点是否为空,还要判断左右子树是否为空)。
这里引入内部节点和外部结点的概念(定义略)来分析问题!!!:
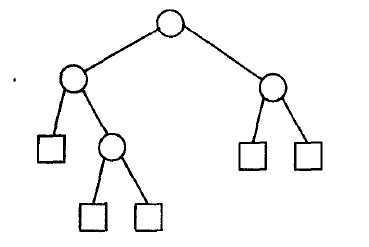
显然对于每个内部节点都要计算一次加法,对于内部节点和外部结点,都要执行一次比较(判断是否为空)。
可以证明,有n个结点的二叉树的外部结点个数为 x = n + 1;(如上图,用数学归纳法或者图论相关知识都很好证明,证明略)
根据上述分析,对一个n个顶点的二叉树求高度,
加法的操作次数为内顶点个数:n
比较判断是否为空的操作次数为内部点加外部点的个数:n + (n + 1) = 2n + 1;
无论怎么说,该算法是线性的!
3)其他一些如三种经典的遍历算法,都可以递归的来定义,这些都是数据结构课程的标准组成部分,前面已写,不再详述。
最后指出一点,并不是所有的二叉树算法都要遍历左右子树,例如二叉查找树的插入查找删除只需要遍历一棵(每次总能排除一棵),这种策略应该归于减可变规模的策略(参见下一章减治策略)。
几道习题的思考:
1)设计一个分治算法来计算二叉树的层数。-----------递归的返回左右子树层数较大值+1,注意空树和单节点时的情况
最后,扩展一下本节最开始的计算二叉树高度的算法:
一道腾讯面试题:怎么求二叉树上最远的2个节点的距离?-------左子树高度+右子树高度+2,注意特殊情况(只有一边右子树)就行了。
--------------------------------------------------------------------------------------------------------------------------------------------------
总结:
1)分治的思想:一般递归来实现,划分子问题,合并子问题的解。
2)主定理,要很熟悉,常见的递推式应该一眼判断其复杂度。
3)合并排序,快速排序,折半查找,二叉遍历树相关特性,这些都是数据结构的经典内容,之前也都写过了,代码参见前面的相关文章。
这里再次复习,从不同的视角来看它们都是如何用用到了分治的策略。这些内容应当非常熟练。
原文地址:http://www.cnblogs.com/wuchanming/p/3790341.html