标签:
统计是一组存储为柱状图的信息。柱状图是显示数据落入不通分类中的频率的一种统计结构。SQL Server存储的柱状图包括多大200行的列和索引键(或多列索引键的第一列)的数据分布采样。在两个连续采样值之间的索引键值范围上的信息被称为步骤。这些步骤由200个存储值之间的不通大小间隔组成。
一个步骤提供以下信息:
CREATE NONCLUSTERED INDEX IX_COLUMN2 ON ta1(column2)
DBCC SHOW_STATISTICS(ta1,IX_COLUMN2)
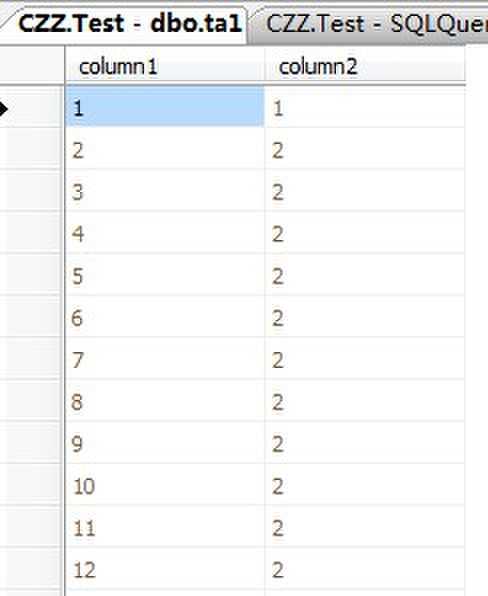
我们看到统计的信息如下:
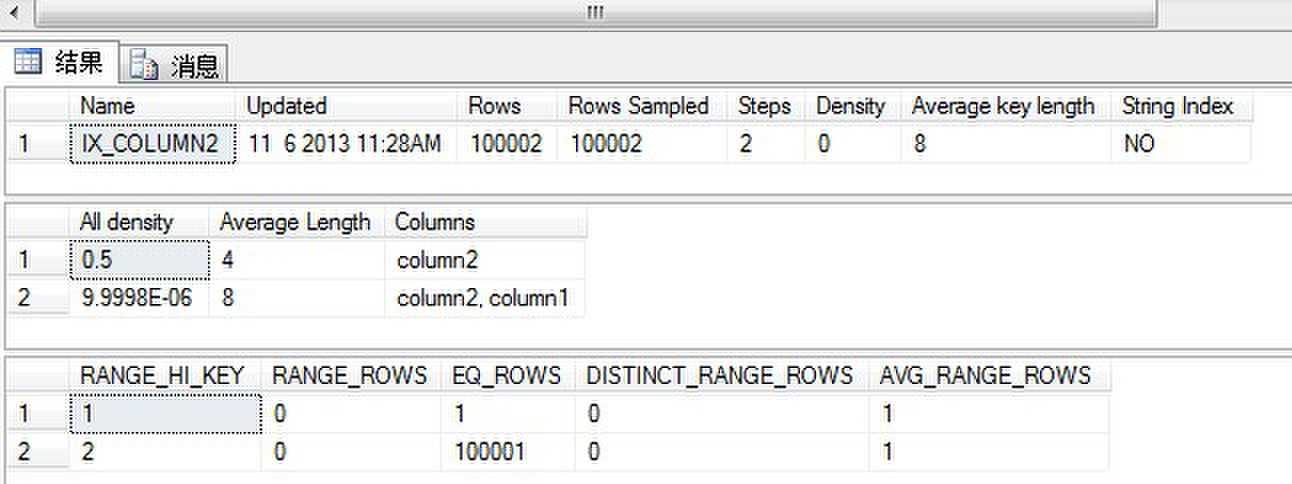
除了步骤上的信息,统计中的其他有用信息包括:
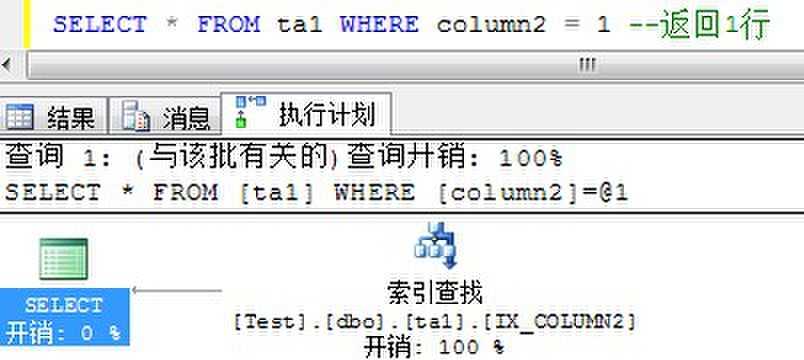
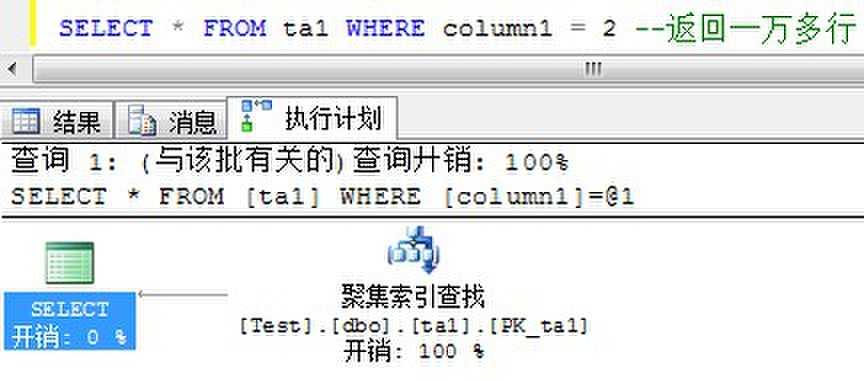
创建执行计划时,查询优化器分析用于过滤器和JOIN子句中的列的统计。具有高选择性的过滤条件将来自表的行数限制在一个小结果集内,并且帮助优化器保持低的查询开销。具有唯一索引的列将有非常高的选择性,因为它可以将匹配行数限制为1。
另一方面,低选择性的过滤条件将从表中返回一个大的结果集。非常低选择性的过滤条件使列上的非聚集索引变得无效。为大的结果集从非聚集索引导航到基本表通常比直接扫描基本表开销更大,因为非聚集索引相关的书签查找开销太大。
统计以密度(density)比率的形式跟踪列的选择性。高选择性(或唯一性)的列将有很低的密度。低密度的列(高选择性)适用于非聚集索引,因为它帮助优化器很快地检索少量的行。这也是过滤索引操作的主要依据,因为过滤器的目标是改进索引的选择性或密度。
密度可以表示为:
密度=1/列中不同值的数量
密度是0-1之间的数值。列密度越低,越适合于非聚集索引。你可以自己计算来确定索引和统计中列的密度。
例如上面ta1表中的column2列上的密度
SELECT 1.0/COUNT(DISTINCT Column2) FROM ta1
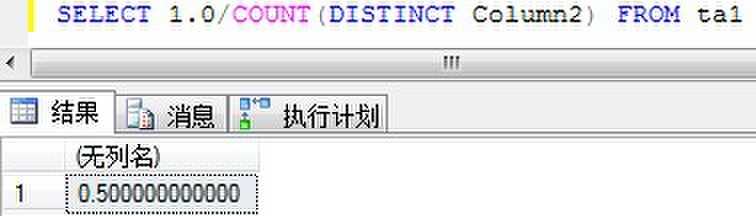
当然,也可以在DBCC SHOW_STATISTICS的输出中的All density列中看到真实的数据。这个列上的高密度值使其不适合于作为索引,即使是过滤索引也一样。但是,在步骤中维护的该索引键值统计帮助查询优化器使用断言c1=1来使用该索引。
在索引只有一列的情况下,统计包含一个柱状图和该列的一个密度值。有多列的复合索引的统计由仅包含第一列的柱状图和多个密度值组成。这就是在建立符合索引或符合统计时,明智的方法是将更高选择性的列即具有最低密度的列放在第一位的原因。密度值包含第一列和每个索引键列的前缀组合的密度。当WHERE和JOIN子句中断言引用多列时,多个密度值帮助优化器查找符合索引的选择性。尽管第一列能帮助确定柱状图,但是该列本身最后的密度将相同而不管列的顺序。
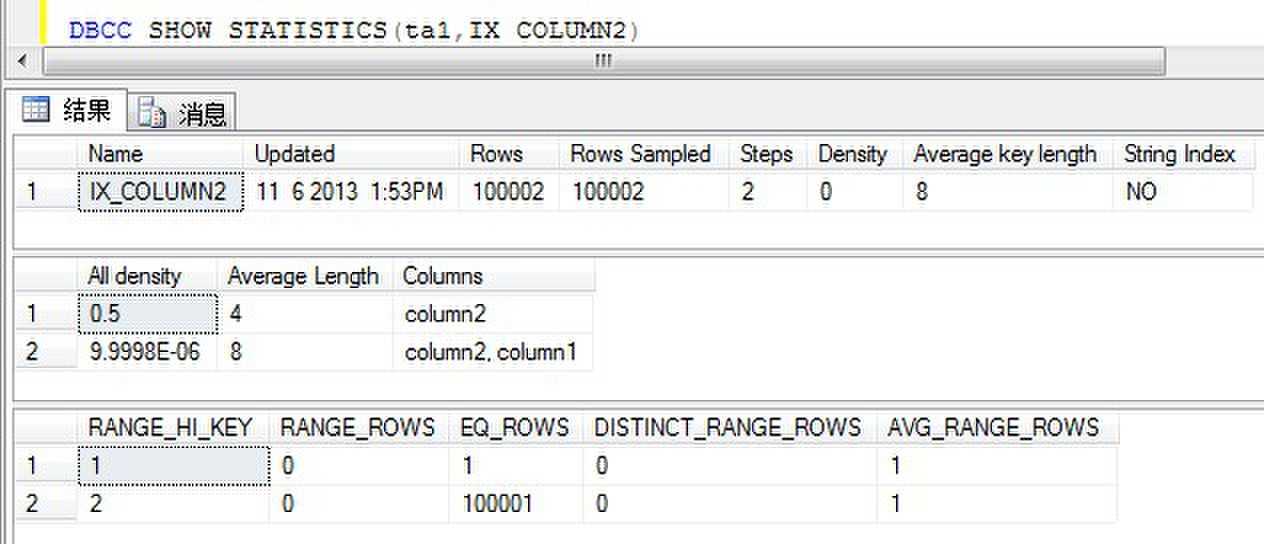
CREATE NONCLUSTERED INDEX IX_COLUMN2 ON ta1(column2,column1) WITH DROP_EXISTING
在来看看统计信息:
过滤索引的目的是改变组成索引的数据,从而改变柱状图和密度使索引性能更好。
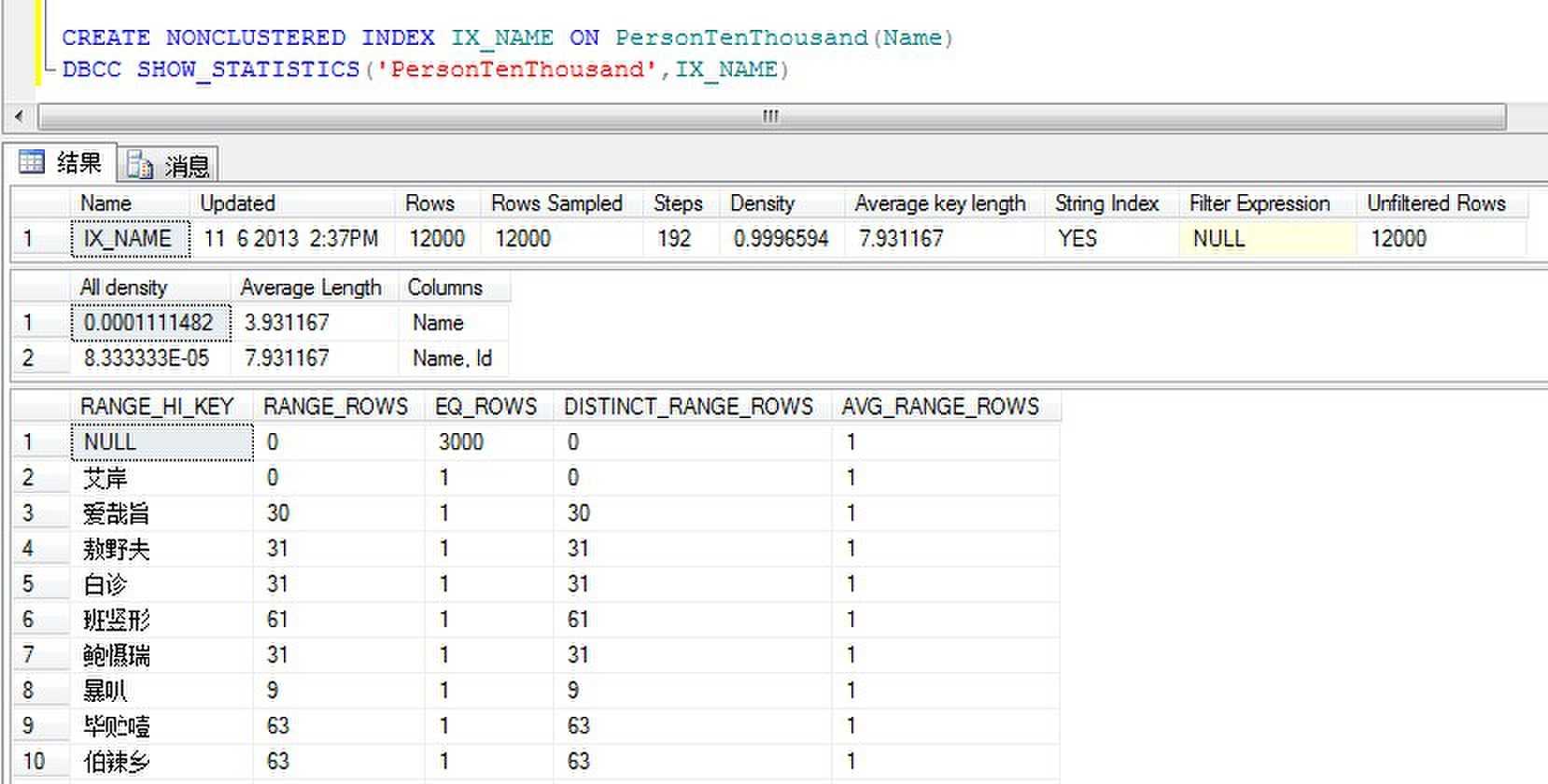
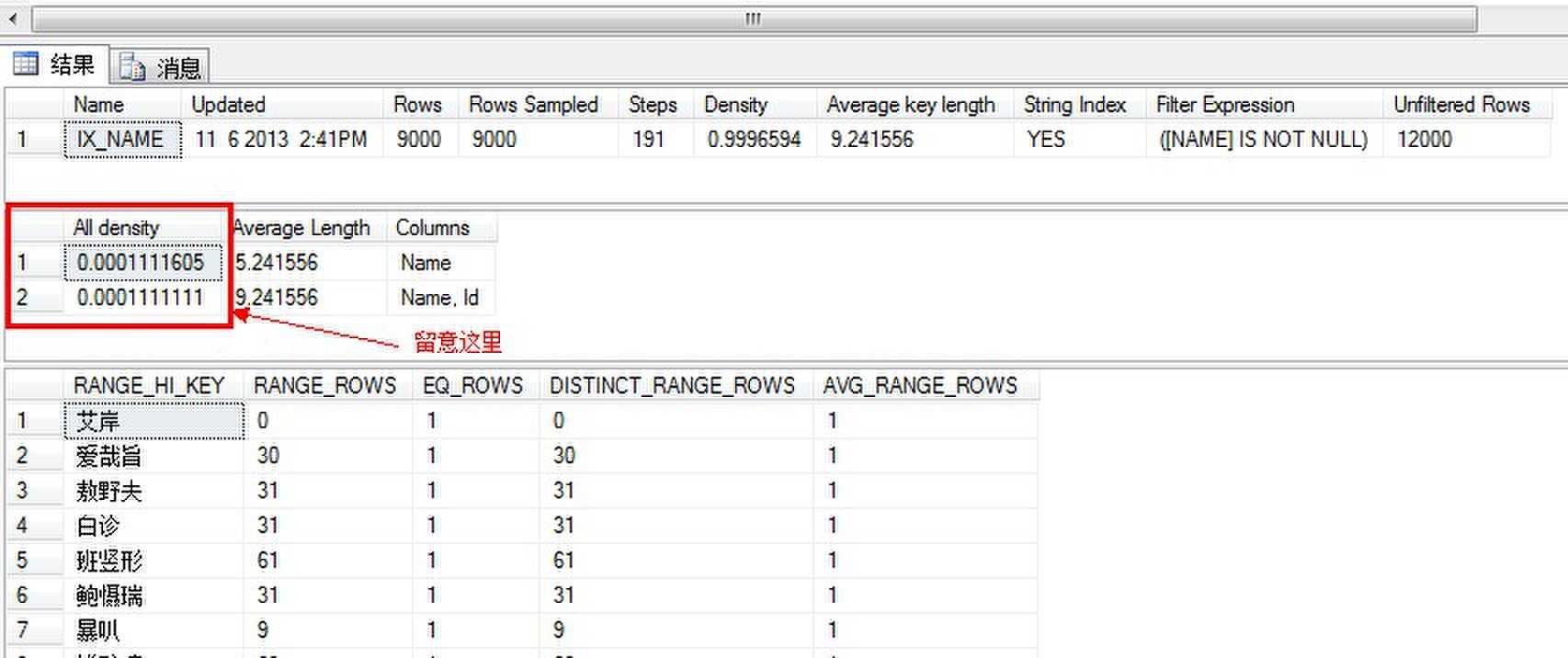
我们看到,组成统计的行数急剧下降,因为有一个过滤器,过滤了3000行,行数当然下降啦。平均关键字长度增加,因为不在处理长度为0的Name。
密度测量值非常有趣,两个值非常接近,但是过滤后的密度略低,说明更少的唯一值。这是因为过滤后的数据,虽然选择性稍微低一些,但是实际上更精确,消除了对搜索没有贡献的控制。第二个值密度表示聚集索引指针,与Name的单独密度值相同,因为都表示相同的唯一值数量。前一列附加的聚集索引的密度是一个小得多的数值,因为消除了null值而导致的所有不被包含在过滤后的数据的Id唯一值。
另一个开放的选项是创建过滤索引,这使你能在分区的表上创建更加精细调整过的柱状图。因为统计不会自动在分区表上创建,并且不能使用CREATE STATISTICS自行创建,所以这是必要的。可以通过分区创建过滤索引并获得统计或创建特定的过滤统计。
标签:
原文地址:http://www.cnblogs.com/feng-NET/p/4541768.html