标签:
搜索引擎索引基础
前几天我阅读了搜索引擎索引这一章,发现倒排索引这一方法确实很巧妙和迷人,它包含的原理和设计方法很独到。所以接下来,我想把我学习到的索引方面的知识给大家讲解一下,总共分为三篇:索引基础、索引建立和更新、索引查询。
我们首先认识倒排索引基本概念
文档:一般搜索引擎的处理对象是互联网网页,而文档这个概念要更宽泛些,代表以文本形式存在的存储对象,相比网页来说,涵盖了更多形式,比如Word、PDF、HTML、XML等不同格式的文件都可以称为文档。
文档集合:由若干文档构成的集合称为文档集合。
文档编号:在搜索引擎内部,会为文档集合中每一个文档赋予一个唯一的内部编号,以此编号来作为文档的唯一标识,这样方便内部处理。每个文档的内部编号称为文档编号。
单词编号:和文档编号类似,单词编号可以作为某个单词的唯一表征。
倒排索引:倒排索引是实现单词—文档矩阵的一种具体存储形式。通过倒排索引,可以通过单词快速获取包含这个单词的文档列表。倒排索引由两个部分组成:单词词典和倒排文件。
单词词典:搜索引起通常的索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息及指向倒排列表的指针(还记得链表吗?亲)。
倒排文件:所有单词的倒排列表往往顺序的存储在磁盘的某个文件里,这个文件即被称为倒排文件,倒排文件是存储倒排索引的物理文件。
倒排列表:倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项。根据倒排列表,就可以获知哪些文档包含某个单词。
倒排索引示意图如下所示
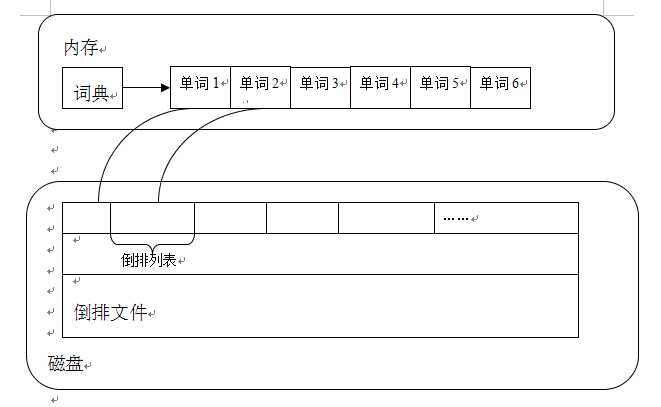
单词词典是倒排索引中非常重要的组成部分,它是用来维护文档集合中所有单词的相关信息,同时用来记载某个单词对应的倒排列表在倒排文件中的位置信息。在支持搜索时,根据用户的查询词,去单词词典里查询,就能够获得相应的倒排列表。
对于一个规模很大的文档集合来说,可能包含了几十万甚至上百万的不同单词,快速定位某个单词直接决定搜索的响应速度,所以我们需要很高效的数据结构对单词词典进行构建和查找。常用的数据结构包含哈希加链表和树形词典结构。
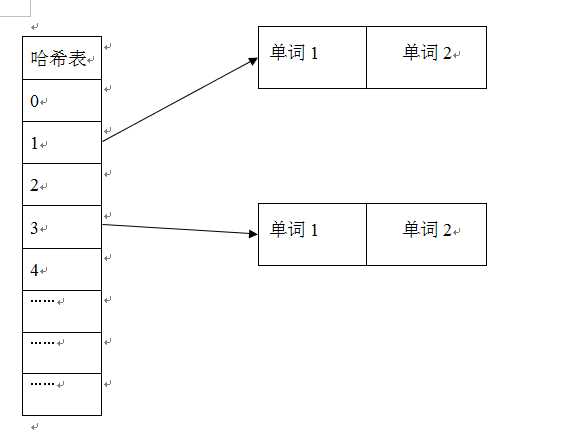
哈希加链表
这种词典结构主要由两个部分组成,主体部分是哈希表,每个哈希表项保存一个指针,指针指向冲突链表,在冲突链表中,相同哈希值的单词形成链表结构。
在建立索引的过程中,词典结构也会相应地被构建出来。比如在解析一个新文档的时候,对于某个在文档中出现的单词W,首先利用哈希函数获取其哈希值,之后根据哈希值对应的哈希表项读取其中保存的指针,就找到了对应的冲突链表。如果冲突链表里已经存在这个单词,说明单词在之前解析的文档里已经就出现过,此时就不用加进去了。如果没有发现这个单词,说明该单词是首次碰到,则将其加入冲突链表中。通过这种方式,当文档集合内所有文档解析完成时,相应的词典结构也就建立起来了。
树形结构
B树是另一种高效查找结构,它是一颗多叉树。和哈希方式查找不同,需要字典项能够按照大小排序,而哈希方式无需数据满足此要求。B树形成了层级查找结构,中间节点用于指出一定顺序范围的词典项目存储在哪个子树中,起到根据词典项比较大小进行导航的作用,最底层的叶子节点存储单词的地址信息,根据这个地址就可以提取出单词字符串。
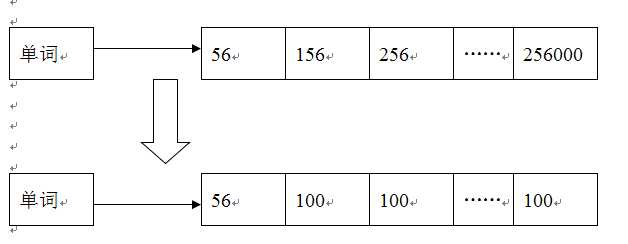
倒排列表用来记录有哪些文档包含了某个单词。一般在文档集合里会有很多文档包含了某个单词,每个文档会记录文档编号,单词在这个文档中出现的次数以及单词在文档中有哪些位置出现过等信息,这样与一个文档相关的信息称作倒排索引项,包含这个单词的一系列倒排索引项形成了列表结构,这就是某个单词对应的倒排列表。在文档集合中出现过的所有单词以及对应的倒排列表就组成了所谓的倒排索引。
然而在实际的搜索引擎系统中,并不存储倒排索引项中的实际文档编号,而是以文档编号差值(想想为什么要这样做呢?原因很简单,互联网中文档集合中的文档很多,对应的文档编号数字到最后也会很大,在倒排列表中不方便存储)。如下图所示,文档编号差值是倒排列表中相邻的两个倒排索引项文档编号的差值,一般在索引构建过程中,可以保证倒排列表中后面出现的文档编号大于之前出现的文档编号,所以文档编号差值总是大于0的整数。
标签:
原文地址:http://www.cnblogs.com/BaiYiShaoNian/p/4541914.html