标签:
What is HDInsight?
Microsoft Azure HDInsight 是基于 Hortonoworks Data Platform (HDP) 的 Hadoop 集群,包括Storm, HBase, Pig, Hive, Sqoop, Oozie, Ambari等(具体的组件请参看最后的附录)。Azure HDInsight 支持 Windows的集群部署,也支持 Linux 集群部署。Hortonworks 是我目前所知唯一支持在 Windows 上部署的 Hadoop Cluster。
以下是 HDInsight 在两个平台上部署的比较:
|
Category |
Hadoop on Linux |
Hadoop on Windows |
|
Cluster OS |
Ubuntu 12.04 Long Term Support (LTS) |
Windows Server 2012 R2 |
|
Cluster Type |
Hadoop |
Hadoop, HBase, Storm |
|
Deployment |
Azure Management Portal, Azure CLI, Azure PowerShell |
Azure Management Portal, Azure CLI, Azure PowerShell, HDInsight .NET SDK |
|
Cluster UI |
Ambari |
Cluster Dashboard |
|
Remote Access |
Secure Shell (SSH) |
Remote Desktop Protocol (RDP) |
What is Spark?
Spark 是基于内存计算的大数据并行计算框架,快如闪电的大数据分析工具。Spark 于2009年诞生于加州大学伯克利分校 AMP Lab,目前已是 Apache 软件基金旗下的顶级开源项目。Spark支持Python、Java和Scala编程语言。您无需是专家级的编程者即可从 Spark 中受益。
Spark本身用Scala语言编写,运行于Java虚拟机(JVM)。只要在安装了Java 6以上版本的便携式计算机或者集群。如果您想使用Python API需要安装Python解释器(2.6或者更高版本),请注意Spark暂不支持Python 3。
Which version of Spark can I install?
In this topic, we use a Script Action custom script to install Spark on an HDInsight cluster. This script can install Spark 1.2.0 or Spark 1.0.2 depending on the version of the HDInsight cluster you provision.
You can modify this script or create your own script to install other versions of Spark.
Using the Spark shell to run interactive queries
Perform the following steps to run Spark queries from an interactive Spark shell. In this section, we run a Spark query on a sample data file (/example/data/gutenberg/davinci.txt) that is available on HDInsight clusters by default.
.\bin\spark-shell --master yarn
After the command finishes running, you should get a Scala prompt:
scala>
val file = sc.textFile("/example/data/gutenberg/davinci.txt")
val counts = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
counts.toArray().foreach(println)

:q
Spark核心概念
现在您已经在shell中运行了第一个Spark代码,是时候开始学习更深入的编程了。
每一个Spark应用程序都包含在集群上运行各种并行操作的驱动程序,驱动程序包含应用程序的主函数和定义在集群上的分布式数据集。在前面的示例中,驱动程序是Spark shell本身,您只需输入您想要执行的操作即可。
驱动程序通过 SparkContext 对象访问Spark计算集群。在shell中,SparkContext被自动创建为名称是sc的变量,在示例1-1中我们输入sc,则shell显示其类型。
Example 1-1. Examining the sc variable
>>> sc
<pyspark.context.SparkContext object at 0x1025b8f90>
在创建了SparkContext对象之后,您就可创建RDD。在示例2-1和示例2-2中,我们调用 sc.textFile() 创建RDD,以变量lines记录读入的文本文件内容。
若要运行这些操作,驱动程序通常管理者多个拥有 executor的工作节点。比如,我们在集群中执行count()操作,不同的机器可能计算lines变量不同的部分。我们只在本地运行Spark shell,则它被执行在单机中,如果我们将shell连接至集群它也可并行的分析数据。示例1-1展示如何将Spark执行在集群之上。
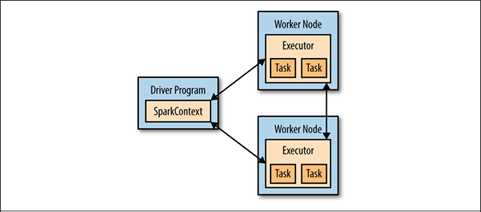
图1-1. Components for distributed execution in Spark
Spark 的 API 很大程度上依靠在驱动程序里传递函数到集群上运行。比如,我们扩展上面的README示例,筛选文本中包含的特定关键词"Python",代码如示例1-2(Python),示例1-3(Scala)。
示例1-2 Python filtering example
>>> lines = sc.textFile("README.md")
>>> pythonLines = lines.filter(lambda line: "Python" in line)
>>> pythonLines.first() u‘## Interactive Python Shell‘
Example 1-3. Scala filtering example
scala> val lines = sc.textFile("README.md") // Create an RDD called lines lines: spark.RDD[String] = MappedRDD[...]
scala> val pythonLines = lines.filter(line => line.contains("Python")) pythonLines: spark.RDD[String] = FilteredRDD[...]
scala> pythonLines.first() res0: String = ## Interactive Python Shell
|
Spark传递函数 如果您不熟悉示例1-2和1-3中的 lambda表达式 或者 => 语法,那么在此说明其实它是在Python和Scala中的定义内联函数的简短写法。如果您在Spark中使用这些语言,您可定义函数然后将其名称传递给Spark。比如,在Python语言中: def hasPython(line): return "Python" in line pythonLines = lines.filter(hasPython)
Spark传递函数也支持Java语言,但在此情况下传递函数被定义为类,实现调用函数的接口。比如: JavaRDD<String> pythonLines = lines.filter( new Function<String, Boolean>() { Boolean call(String line) { return line.contains("Python"); } } ); Java 8 中介绍了调用了lambda的的简短写法,与Python和Scala很类似。 JavaRDD<String> pythonLines = lines.filter(line -> line.contains("Python"));
We discuss passing functions further in "Passing Functions to Spark" on page 30. 我们在30页的"Spark传递函数"中深入讨论传递函数。 |
Spark API包含许多魅力无穷的基于函数的操作可基于集群并行计算,比如筛选(filter)操作,我们在后面的文章详细介绍。Spark自动将您的函数传递给执行(executor)节点。因此,您可在单独的驱动程序中编写代码,它会自动的在多个节点中运行。
What are the Hadoop components?
In addition to the previous overall configurations, the following individual components are also included on HDInsight clusters.
Azure HDInsight 和 Spark 大数据分析(一)
标签:
原文地址:http://www.cnblogs.com/xuesong/p/4544506.html