标签:style class blog code http tar
本文机器学习库使用的部分代码来源于spark1.0.0官方文档。
mllib是spark对机器学习算法和应用的实现库,包括分类、回归、聚类、协同过滤、降维等,本文的主要内容为如何使用scala语言创建sbt工程实现机器学习算法,并进行本地和集群的运行。(初学者建议先在RDD交互式模式下按行输入代码,以熟悉scala架构)若想了解SBT等相关信息,可参见这里。
1.SVM(linear support vector machine)
name := "SimpleSVM Project" version := "1.0" scalaVersion := "2.10.4" libraryDependencies += "org.apache.spark" %% "spark-core" % "1.0.0" libraryDependencies += "org.apache.spark" %% "spark-mllib" % "1.0.0" resolvers += "Akka Repository" at "http://repo.akka.io/releases/"
PS:由于该应用需要调用mllib,因此要特别注意在libraryDependencies加入spark-mllib,否则会编译不通过的哦。
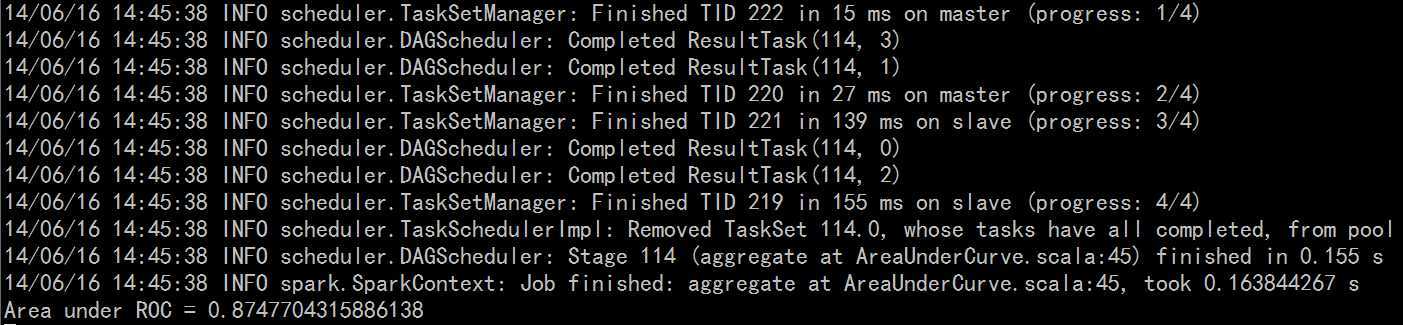
import org.apache.spark.SparkContext import org.apache.spark.mllib.classification.SVMWithSGD import org.apache.spark.mllib.evaluation.BinaryClassificationMetrics import org.apache.spark.mllib.regression.LabeledPoint import org.apache.spark.mllib.linalg.Vectors import org.apache.spark.mllib.util.MLUtils import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf object SimpleApp{ def main(args: Array[String]) { val conf = new SparkConf().setAppName("SimpleSVM Application") val sc = new SparkContext(conf) val data = MLUtils.loadLibSVMFile(sc, "mllib/test50.txt") val splits = data.randomSplit(Array(0.6, 0.4), seed = 11L) val training = splits(0).cache() val test = splits(1) val numIterations = 100 val model = SVMWithSGD.train(training, numIterations) model.clearThreshold() val scoreAndLabels = test.map { point => val score = model.predict(point.features) (score, point.label) } val metrics = new BinaryClassificationMetrics(scoreAndLabels) val auROC = metrics.areaUnderROC() println("Area under ROC = " + auROC) } }
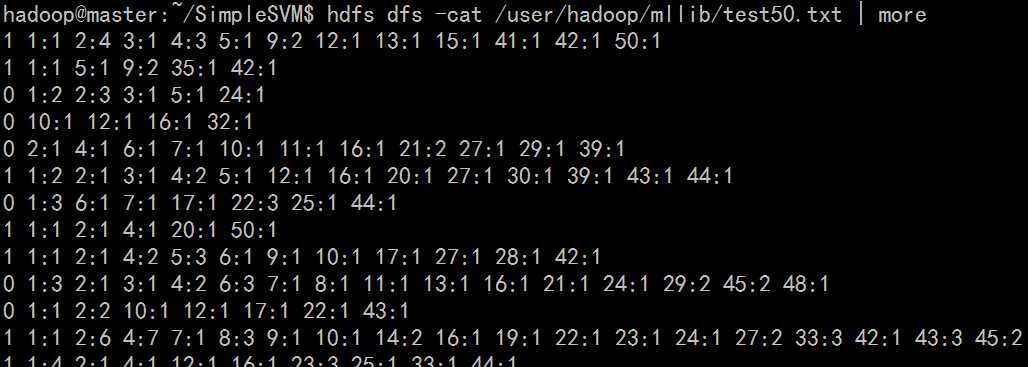
PS:由于我们之前在spark配置过程中将hadoop路径配置好了,因此这里的输入路径mllib/test50.txt
实际上为HDFS文件系统中的文件,存储位置与hadoop配置文件core-site.xml中的<name>相关(具体可参见这里,这个地方很容易出错)。因此需要先将test50.txt文件put到hdfs上面,另外test50.txt文件为libsvm文件的输入格式,实例如下:

cd ~/SimpleSVM
sbt package #打包过程,时间可能会比较长,最后会出现[success]XXX
PS:成功后会生成许多文件 target/scala-2.10/simplesvm-project_2.10-1.0.jar等
spark-submit --class "SimpleApp" --master local target/scala-2.10/simplesvm-project_2.10-1.0.jar
spark-submit --class "SimpleApp" --master spark://master:7077 target/scala-2.10/simplesvm-project_2.10-1.0.jar
PS:若希望在算法中添加正则项因子,可将SimpleApp.scala文件修改如下:
import org.apache.spark.mllib.optimization.L1Updater val svmAlg = new SVMWithSGD() svmAlg.optimizer. setNumIterations(200). setRegParam(0.1). setUpdater(new L1Updater) val modelL1 = svmAlg.run(training)
2.逻辑回归(Logistic Regression)
同理,若要实现逻辑回归算法则只需将SimpleApp.scala文件中的SVMWithSGD替换为 LogisticRegressionWithSGD。
3. 协同过滤(Collaborative filtering)
文件系统如上所示,协同过滤算法可以将只需将SimpleApp.scala文件进行如下修改:
import org.apache.spark.mllib.recommendation.ALS import org.apache.spark.mllib.recommendation.Rating import org.apache.spark.mllib.linalg.Vectors import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.SparkConf object SimpleApp{ def main(args: Array[String]) { val conf = new SparkConf().setAppName("SimpleCF Application") val sc = new SparkContext(conf) val data = sc.textFile("mllib/test.data") val ratings = data.map(_.split(‘,‘) match { case Array(user, item, rate) => Rating(user.toInt, item.toInt, rate.toDouble) }) val rank = 10 val numIterations = 5 val model = ALS.train(ratings, rank, numIterations, 0.01) val usersProducts = ratings.map { case Rating(user, product, rate) => (user, product) } val predictions = model.predict(usersProducts).map { case Rating(user, product, rate) => ((user, product), rate) } val ratesAndPreds = ratings.map { case Rating(user, product, rate) => ((user, product), rate) }.join(predictions) val MSE = ratesAndPreds.map { case ((user, product), (r1, r2)) => val err = (r1 - r2) err * err }.mean() println("Mean Squared Error = " + MSE) } }
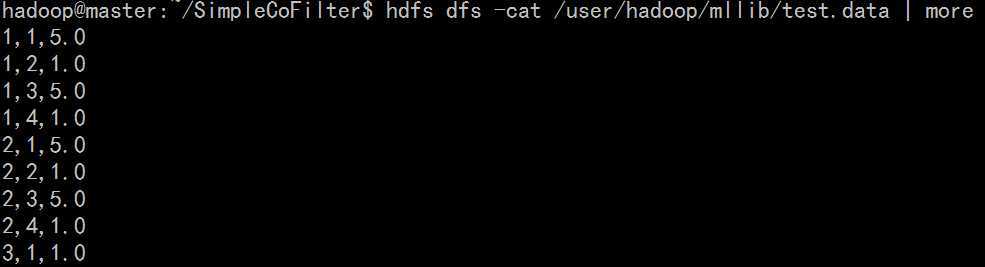
PS:同理,mllib/test.data存储于HDFS文件系统,为示例数据:
spark-submit --class "SimpleApp" --master local target/scala-2.10/simplecf-project_2.10-1.0.jar
spark-submit --class "SimpleApp" --master spark://master:7077 target/scala-2.10/simplecf-project_2.10-1.0.jar

PS:可以加入alpha参数控制:
val alpha = 0.01 val model = ALS.trainImplicit(ratings, rank, numIterations, alpha)
同理聚类算法、降维方法代码可参见这里。
本文为原创博客,若转载请注明出处。
spark1.0.0 mllib机器学习库使用初探,布布扣,bubuko.com
标签:style class blog code http tar
原文地址:http://www.cnblogs.com/tec-vegetables/p/3791398.html