标签:
TCP/UDP编程中的问题汇总
答:
发送端:
发送时,先发送文件的名称及大小等信息。
然后,设置一个缓冲区的大小,假设为4K。
再循环读4K的文件内容,并发送,直到发送完成。
最后,再发送完成标记。
接收端:
接收到第一个包时,得到文件的大小等信息。
计算出要接收多少个包。
然后,循环接收包,并将接收到的数据写入到文件中。
直到,接收到的数据长度等于文件的大小。
struct package
{
文件标识 //GUID
偏移量 //001-
数据段 //Byte[]
};
UDP服务端和客户端,同时实现发送和接收数据。
答:
1,客户端与服务端在同一局域网,或客户端有公网IP。
2,客户端与服务端不在同一局域网,且客户端无公网IP。
NAT技术。
答:
如果C给S发报文。则S收到报文后,给C发一个收到报文的响应。C对此进行记录。
如果C在某段时间内未收到响应,则重发此报文。
答:
发送端在报文中加入发送序号。接收端就可以按照发送序号进行重新排列。
1.UDP缺乏流量控制的概念
UDP协议没有TCP协议所具有的滑动窗口概念,接收数据的时候直接将数据放到缓冲区中。如果用户不有及时地从缓冲区中将数据复制出来
,后面到来的数据会接着向缓冲区中放入。当缓冲区满的时候,后面到来的数据会覆盖之前的数据造成数据的丢失。
2.缓冲区溢出对策
解决UDP接收缓冲区溢出的现象需要根据实际情况确定,一般可以用增大接收数据缓冲区和接收方接收单独处理的方法来解决局部的UDP数
据接收缓冲区溢出问题。
当然,这个没有唯一答案,相对于不同的系统,不同的要求,其得到的答案是不一样的,我这里仅对像ICQ一类的发送聊天消息的情况作分析,对于其他情况,你或许也能得到一点帮助:
首先,我们知道,TCP/IP通常被认为是一个四层协议系统,包括链路层,网络层,运输层,应用层.
UDP属于运输层,下面我们由下至上一步一步来看:
以太网(Ethernet)数据帧的长度必须在46-1500字节之间,这是由以太网的物理特性决定的. 这个1500字节被称为链路层的MTU(最大传输单元).
但这并不是指链路层的长度被限制在1500字节,其实这这个MTU指的是链路层的数据区. 并不包括链路层的首部和尾部的18个字节.
所以,事实上,这个1500字节就是网络层IP数据报的长度限制.
因为IP数据报的首部为20字节,所以IP数据报的数据区长度最大为1480字节.
而这个1480字节就是用来放TCP传来的TCP报文段或UDP传来的UDP数据报的.
又因为UDP数据报的首部8字节,所以UDP数据报的数据区最大长度为1472字节.
这个1472字节就是我们可以使用的字节数。:)
当我们发送的UDP数据大于1472的时候会怎样呢?
这也就是说IP数据报大于1500字节,大于MTU.这个时候发送方IP层就需要分片(fragmentation).
把数据报分成若干片,使每一片都小于MTU.而接收方IP层则需要进行数据报的重组.
这样就会多做许多事情,而更严重的是,由于UDP的特性,当某一片数据传送中丢失时,接收方便无法重组数据报.将导致丢弃整个UDP数据报。
因此,在普通的局域网环境下,我建议将UDP的数据控制在1472字节以下为好.
进行Internet编程时则不同,因为Internet上的路由器可能会将MTU设为不同的值.
如果我们假定MTU为1500来发送数据的,而途经的某个网络的MTU值小于1500字节,那么系统将会使用一系列的机制来调整MTU值,使数据报能够顺利到达目的地,这样就会做许多不必要的操作.鉴于Internet上的标准MTU值为576字节,所以我建议在进行Internet的UDP编程时. 最好将UDP的数据长度控件在548字节(576-8-20)以内.
理论上,IP数据报的最大长度是65535字节,这是由IP首部16比特总长度字段所限制的。去除20字节的IP首部和8个字节的UDP首部,UDP数据报中用户数据的最长长度为65507字节。但是,大多数实现所提供的长度比这个最大值小。
我们将遇到两个限制因素。第一,应用程序可能会受到其程序接口的限制。socket API提供了一个可供应用程序调用的函数,以设置接收和发送缓存的长度。对于UDP socket,这个长度与应用程序可以读写的最大UDP数据报的长度直接相关。现在的大部分系统都默认提供了可读写大于8192字节的UDP数据报(使用这个默认值是因为8192是NFS读写用户数据数的默认值)。
第二个限制来自于TCP/IP的内核实现。可能存在一些实现特性(或差错),使IP数据报长度小于65535字节。
在SunOS 4.1.3下使用环回接口的最大IP数据报长度是32767字节。比它大的值都会发生差错。
但是从BSD/386到SunOS 4.1.3的情况下,Sun所能接收到最大IP数据报长度为32786字节(即32758字节用户数据)。
在Solaris 2.2下使用环回接口,最大可收发IP数据报长度为65535字节。
从Solaris 2.2到AIX 3.2.2,发送的最大IP数据报长度可以是65535字节。很显然,这个限制与源端和目的端的实现有关。
主机必须能够接收最短为576字节的IP数据报。在许多UDP应用程序的设计中,其应用程序数据被限制成512字节或更小,因此比这个限制值小。
由于IP能够发送或接收特定长度的数据报并不意味着接收应用程序可以读取该长度的数据。因此,UDP编程接口允许应用程序指定每次返回的最大字节数。如果接收到的数据报长度大于应用程序所能处理的长度,那么会发生什么情况呢?不幸的是,该问题的答案取决于编程接口和实现。
典型的Berkeley版socket API对数据报进行截断,并丢弃任何多余的数据。应用程序何时能够知道,则与版本有关(4.3BSD Reno及其后的版本可以通知应用程序数据报被截断)。
SVR4下的socket API(包括Solaris 2.x) 并不截断数据报。超出部分数据在后面的读取中返回。它也不通知应用程序从单个UDP数据报中多次进行读取操作。TLI API不丢弃数据。相反,它返回一个标志表明可以获得更多的数据,而应用程序后面的读操作将返回数据报的其余部分。在讨论TCP时,我们发现它为应用程序提供连续的字节流,而没有任何信息边界。TCP以应用程序读操作时所要求的长度来传送数据,因此,在这个接口下,不会发生数据丢失。
通过套接字或其助手类来接收信息时,是从缓存区里一次性把全部的缘存都读取出来,只要你设置的缓存够大,它就能读取这么多,这样就会导致这样的情况出现。如果服务端连续发送信息到客户端,如我连续发送字符串"message 1"、"message 2"、"message 3"、"message 4"、"message 5",我预想的是在客户端也是能够收到这样的五个完整的字符串,如果用前二篇中讲的方法,在同台机子上测试的话,是正常的,因为同台机子上网络信息传送出现的异常会比较少,但如果把客户端与服务端部署在不同的机器上,则会出现一些异想不到的现象。你会发现接收到的字符都被打乱了,会出现如"3message 4"的字符串,这样的话,我们就不能把服务端发送的信息正常的还原。这个就是消息的边界问题,要解决这个问题,方法有很多,现抽取其中几个来讲一下:
1、固定尺寸的消息
这是最简单但也是最昂贵的解决TCP消息问题的方案。就是要设计一种协议,永远以固定的长度传递消息,通过将所有的消息都设置为固定的尺寸,在从远程设备中接收到完整的消息时,TCP接收程序就能够了解发送的情况了。用这各地意味着必须将短消息加长,造成网络带宽资源的浪费。
2、使用消息尺寸信息
这个方案允许使用可变长度的消息,惟一的不足就是接收端的远程设置必须了解每一个变长消息的确切长度。具体的方法是,在发送消息的时候,一起发送该消息的长度。那么在客户端接收的时候就能知道该消息的长度是多少,再来读取消息。
3、使用消息标记
该方案使用预先确定的一个字符(或多个字符)来指定消息的结束,通过这种方式来分隔不同的消息。但用这种方法必须对所接收到的每一个字符进行检查以便确定为结束标记,这对于大型消息来说,可能导致系统性能的下降,不过对于C#语言来说,提供了一些类,能够用于简化这个过程,那就是System.IO命名空间流类,下面我们也着重来讲一下这各方法。至于第二种方法,将在下一篇中与在消息中传送实体类信息相结合来讲述。
在上一篇中,我们已经提到NetworkStream类,利用该类来传送和接收消息。在这里,再提一下另外的二个流类,那就是StreamReader和StreamWriter,这二个类也可用于TCP协议发送和接收文本消息。
当我们得到Socket连接的一个NetworkStream对象时,可以通过下面的方法得到StreamWriter和StreamReader对象。
1NetworkStream ns = s.GetStream();
2 StreamReader sr = new StreamReader(ns);
3 StreamWriter sw = new StreamWriter(ns);
这样我们就可以通过StreamWriter来发送消息,通过StreamReader来接收消息:
1//发送消息
2string welcome = "Welcome to my test sever ";
3
4 sw.WriteLine(welcome);
5 sw.Flush();
接收消息:
1//接收消息
2string data = "";
3data = sr.ReadLine();
这样是不是比以前的做法更简单了,而且同时也解决了TCP消息边界问题了。
但是用这各方法必须得注意以下二点:
1、这种方法其实就是利用消息标记来解决边界问题的,这里的标记就是换行符,也就是说,StreamWriter中的WriteLine()和StreamReader中的ReadLine()一定要成对使用,不然如果发送的信息中没有换行符,则客户机中用ReadLine()读取信息时,将无法结束,将堵塞程序的执行,一直等待换行符。
2、另外还要保证在发送的消息本身不应该带有换行符,如果消息本身带有换行符,则这些换行符将被ReadLine()方法错误地作为标记,影响数据的完整性。
2个小时。
如何实现在传文件时的断点续传。
答案:
其实在tcp/ip协议中传输文件可以保证传输的有效性,但有一个问题文件传了一部分连接意外断开了怎样;那这种情况只能在重新连接后继续传输,由于文件那部分已经传了那部分没有完成并不是tcp/ip的范围,所以需要自己来制定协议达到到这个目的。实现这个续传的协议制定其实也是非常简单,通过协议把文件按块来划分,每完成一个块就打上一个标记;即使是连接断了通过标记状态就知道还需要传那些内容。下面通过beetle来实现一个简单断点续传的程序(包括服务端和客户端)。
在实现之前先整理一下流程思路,首先提交一个发送请求信息包括(文件名,块大小,块的数量等),等对方确认后就进行文件块发送,对方接收块写入后返回一个标记,然后再继续发直到所有发送完成。思路明确后就制定协了:
文件传输申请信息
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
public class Post:MessageBase { public string FileName; public long Size; public int PackageSize; public int Packages; public Post() { FileID = Guid.NewGuid().ToString("N"); } } public class PostResponse : MessageBase { public string Status; } |
FileID这个值是用来协同工作的,两端根据这个ID来找到具体操作的文件和相关信息;Response提供了一个Status属性,可以用来提供一个错误的描述,如果无有任何值的情况说明对方允许这个行为.
文件块传输信息
|
1 2 3 4 5 6 7 8 9 10 |
public class PostPackage:MessageBase { public byte[] Data; public int Index; } public class PostPackageResponse : MessageBase { public int Index; public string Status; } |
文件块传输也是一个请求,一个应答;分别带的信息就是块数据信息和块的位置,同样也是根据Status信息来标记块的处理是否成功。
结构定义完成了,那就进行逻辑处理部分;不过为了调用更方便还需要封装一些东西,如根据块大小来划分文件块的数目,获取某一文件块的内容和写入文件某一些的内容等功能。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
public static int GetFilePackages(long filesize) { int count; if (filesize % PackageSize > 0) { count = Convert.ToInt32(filesize / PackageSize) + 1; } else { count = Convert.ToInt32(filesize / PackageSize); }
return count; } public static byte[] FileRead(string filename, int index, int size) { using (Smark.Core.ObjectEnter oe = new Smark.Core.ObjectEnter(filename)) { byte[] resutl = null; long length = (long)index * (long)size + size; using (System.IO.FileStream stream = System.IO.File.OpenRead(filename)) { if (length > stream.Length) { resutl = new byte[stream.Length - ((long)index * (long)size)]; } else { resutl = new byte[size]; } stream.Seek((long)index * (long)size, System.IO.SeekOrigin.Begin); stream.Read(resutl, 0, resutl.Length); } return resutl; } } public static void FileWrite(string filename, int index, int size, byte[] data) { using (Smark.Core.ObjectEnter oe = new Smark.Core.ObjectEnter(filename)) { using (System.IO.FileStream stream = System.IO.File.OpenWrite(filename)) { stream.Seek((long)index * (long)size, System.IO.SeekOrigin.Begin); stream.Write(data, 0, data.Length); stream.Flush(); } }
} |
准备工作完成了,就开始写接收端的代码了。之前的文章已经介绍了Beetle如果创建一个服务和绑定分包机制,在这里就不多说了;看下接收的逻辑是怎样处理了.
接收传文件请求
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
public void Post(ChannelAdapter adapter, Beetle.FileTransfer.Post e) { string file = txtFolder.Text + e.FileName; PostResponse response = new PostResponse(); response.FileID = e.FileID; response.ID = e.ID; try { if (FileTransferUtils.CreateFile(file, e.Size)) { Logics.FileItem item = new Logics.FileItem(); item.FileID = e.FileID; item.FileName = file; item.Packages = e.Packages; item.PackageSize = e.PackageSize; item.Completed = 0; item.Size = e.Size; Logics.Access.Update(item); AddItem(item); } else { response.Status = "不能创建文件!"; } } catch (Exception e_) { response.Status = e_.Message; } adapter.Send(response);
} |
接收请求后根据信息创建临时文件,创建成功就把文件相关信息保存到数据库中,如果失败或处理异常就设置相关Status信息返回.
接收文件块请求
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
public void PostPackage(ChannelAdapter adapter, Beetle.FileTransfer.PostPackage e) { PostPackageResponse response = new PostPackageResponse(); response.FileID = e.FileID; response.ID = e.ID; try { Logics.FileListItem item = fileListBox1.GetAtFileID(e.FileID); if (item != null) { FileTransferUtils.FileWrite( item.Item.FileName + ".up", e.Index, item.Item.PackageSize, e.Data); item.Completed(e.Index); response.Index = e.Index; if (item.Status == Logics.FileItemStatus.Completed) FileTransferUtils.Rename(item.Item.FileName); } else { response.Status = "不存在上传信息!"; } } catch (Exception e_) { response.Status = e_.Message; } adapter.Send(response); } |
接收块请求后处理也很简单,根据FileID获取相关信息,然后把数据写入到文件对应的位置中;当所有块都已经完成后把临时文件名改会来就行了。如果处理异常很简单通过设置到Status成员中告诉请求方。
以下就是请求端的代码了,其代码比接收端更加简单了
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
public void PostResponse(ChannelAdapter adapter, Beetle.FileTransfer.PostResponse e) { mResponse = e; mResetEvent.Set(); } public void PostPackageResponse(ChannelAdapter adapter, Beetle.FileTransfer.PostPackageResponse e) { Logics.FileListItem item = fileListBox1.GetAtFileID(e.FileID); if (item != null) { if (string.IsNullOrEmpty(e.Status)) { item.Completed(e.Index); PostPacakge(item); } else item.Status = Logics.FileItemStatus.Default; } } private void PostPacakge(Logics.FileListItem item) { if (mChannel != null && mChannel.Socket != null && item.Status == Logics.FileItemStatus.Working && item.Item.Completed != item.Item.Packages) { PostPackage post = new PostPackage(); post.FileID = item.Item.FileID; post.Index = item.Item.Completed; post.Data = FileTransferUtils.FileRead(item.Item.FileName, item.Item.Completed, item.Item.PackageSize); mAdapter.Send(post); } } |
请求端要做的工作就是发送文件传输请求,等回应后就处理PostPacakge进行文件块发送,接收到当前文件块处理成功后就发送下一块直接完成。
到这里断点续传的功能代码就已经完成,两边的程序已经可以工作。不过对于一些使用者来说希望程序更友好的表现工作情况,这个时候还得对UI下一点功夫,如看到当前传输的状态和每个文件进度情况等。
以上效果看起来很不错,那接下来就把它实现吧,程序使用ListBox来显示传输文件信息,要达到以上效果需要简单地重写一下OnDrawItem达到我们需要的。在讲述代码之前介绍一个图标网站http://www.iconfinder.com/,毕竟好的图标可以让程序生色不少。下面看下这个重写的代码:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
protected override void OnDrawItem(DrawItemEventArgs e) { base.OnDrawItem(e); StringFormat ListSF; Point imgpoint = new Point(e.Bounds.X + 2, e.Bounds.Y + 1); ListSF = StringFormat.GenericDefault; ListSF.LineAlignment = StringAlignment.Center; ListSF.FormatFlags = StringFormatFlags.LineLimit | StringFormatFlags.NoWrap; ListSF.Trimming = StringTrimming.EllipsisCharacter; Rectangle labelrect = new Rectangle(e.Bounds.X + 44, e.Bounds.Y, e.Bounds.Width - 44, e.Bounds.Height); if (Site == null || Site.DesignMode == false) { if (e.Index >= 0) { FileListItem item = (FileListItem)Items[e.Index]; LinearGradientBrush brush; brush = new LinearGradientBrush(e.Bounds, Color.FromArgb(208, 231, 253), Color.FromArgb(10, 94, 177), LinearGradientMode.Horizontal); double pent = (double)item.Item.Completed / (double)item.Item.Packages; using (brush) { e.Graphics.FillRectangle(brush, e.Bounds.X + 40, e.Bounds.Y + 2, Convert.ToInt32((e.Bounds.Width - 40) * pent), e.Bounds.Height - 4); } if (item.Status == FileItemStatus.Working) { mImgList.Draw(e.Graphics, imgpoint, 1); } else if (item.Status == FileItemStatus.Completed) { mImgList.Draw(e.Graphics, imgpoint, 2); } else { mImgList.Draw(e.Graphics, imgpoint, 0); } e.Graphics.DrawString(item.ToString(),new Font("Ariel", 9), new SolidBrush(Color.Black),labelrect, ListSF); } } } |
重绘代码就是根据当前文件的进度内容来计算出填冲的宽度,还有根据当前文件状态绘制不同的图标,是不是比较简单:)
整个功能完成了看下总体的效果怎样:
下载完整代码
如果需要Smark名称空间的代码可以到 http://smark.codeplex.com/
多线程下载的原理:
各个线程任务分配是这样实现的。在开始下载时,文件平均分成若干块进行下载。如第一个线程一开始的任务是从文件的0位置开始下载一直到72908位置处。 线程1每次下载一块数据后就要调整任务,如第一次下载了20800字节的数据,那么线程1的任务将改为:20800-72908。如此下去,直到任务为 72908-72908时表示线程1完成了当前的下载任务。此时,线程1就分析各个线程的任务,找出任务最为繁忙的一个线程:如线程 3:14816-218724。那么线程1就自动去调整任务,拿50%的任务来再次下载。周而复始直到各个线程都完成任务。
不过这里有一点需要注意:为了避免重复下载部分数据,在调整任务的时候,起始的文件偏移量必须加上接受缓冲器的字节数,因为如前面所举的例子来看。线程1和线程3在平衡负载的时候,线程正在下载数据,如果所剩的数据比接受缓冲器的大小还小,线程1和线程3的部分下载数据将会重复。
UDP协议在IP协议上增加了复用、分用和差错检测功能。UDP的特点:
A)是无连接的。相比于TCP协议,UDP协议在传送数据前不需要建立连接,当然也就没有释放连接。
B)是尽最大努力交付的。也就是说UDP协议无法保证数据能够准确的交付到目的主机。也不需要对接收到的UDP报文进行确认。
C)是面向报文的。也就是说UDP协议将应用层传输下来的数据封装在一个UDP包中,不进行拆分或合并。因此,运输层在收到对方的UDP包后,会去掉首部后,将数据原封不动的交给应用进程。
D)没有拥塞控制。因此UDP协议的发送速率不送网络的拥塞度影响。
E)UDP支持一对一、一对多、多对一和多对多的交互通信。
F)UDP的头部占用较小,只占用8个字节。
UDP报文格式
UDP协议分为首部字段和数据字段,其中首部字段只占用8个字节,分别是个占用两个字节的源端口、目的端口、长度和检验和。
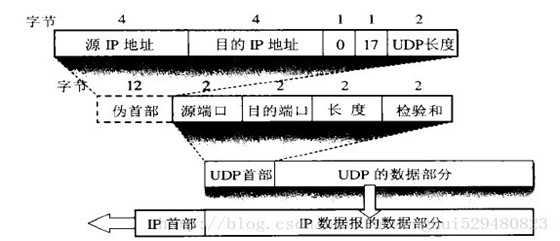
长度:UDP报文的整个大小,最小为8个字节(仅为首部)。
检验和:在进行检验和计算时,会添加一个伪首部一起进行运算。伪首部(占用12个字节)为:4个字节的源IP地址、4个字节的目的IP地址、1个字节的0、一个字节的数字17、以及占用2个字节UDP长度。这个伪首部不是报文的真正首部,只是引入为了计算校验和。相对于IP协议的只计算首部,UDP检验和会把首部和数据一起进行校验。接收端进行的校验和与UDP报文中的校验和相与,如果无差错应该全为1。如果有误,则将报文丢弃或者发给应用层、并附上差错警告。

TCP协议的特点:
A)是面向连接的。应用程序在使用TCP协议时,必须进行连接;当然,数据传输结束后,要断开TCP连接。
B)TCP连接是点对点的。
C)TCP连接时可靠的。也就是说传输的数据时无差错的、不丢失、不重复、有序到达的。
D)是全双工的。即TCP连接的两端都设有发送缓存和接收缓存,用来存放双向通信的数据。
E)是面向字节流的。也就是说TCP将应用程序交下来的数据看成仅仅是一连串的无结构的字节流,其不知道这些字节流的具体含义。TCP协议无法保证发送的数据块的具体大小,因为TCP协议的发送的数据大小收到对方给出的窗口值和当前的网络拥塞度的影响。
TCP的连接端点是套接字。套接字是IP地址拼接上端口号组成的,即点分方式的十进制后面是端口号,中间用逗号或冒号隔开。如下方式:
套接字Socket=(IP地址:端口号)
TCP报文段的首部
TCP协议的首部有20字节的固定长度,以及4N字节的变长段,因此TCP报文段首部最小为20字节。其格式如下:
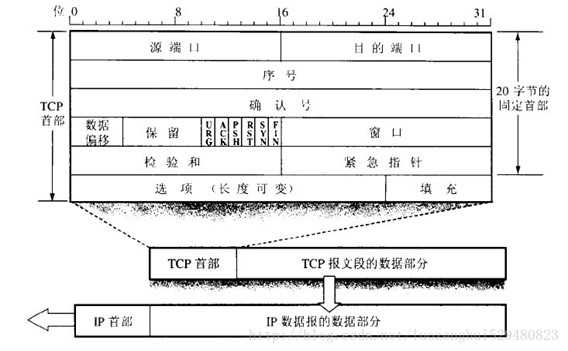
A)分别占用两个字节的源端口和目的端口。
B)序号。占用4个字节。序号是循环的,当增加到最大值后又回到0。TCP是面向字节流的,这样会个发送的数据按顺序给每个字节编上号。在建立连接时,会指出发送的字节流的起始序号。首部中的序号表示发送的报文段的数据的第一个字节的序号,而报文的给字节的序号是顺序的。如第一个字节为401,报文的数据长度为100,则首部的序号为401,最后一个字节的序号为500,也就是说下一个报文的首部序号为501。
C)确认号。占用4个字节。表示期望收到下一个报文段的第一个数据字节的序号,也是下一个报文段的首部序号。如:B收到了A的200个字节数据的TCP报文段,而这个TCP报文段的首部序号为601,则B希望收到的下一个报文段确认号为801。也可以说如果确认号为N,则前面N-1为止的数据已经收到。
D)数据偏移。占用4位。其表示数据起始位置相对于报文段起始的位置的偏移量,也就是报文段首部的长度。其单位为32位字,也就是说其表示的值应该乘上4个字节。如:该字段的值为4,则其报文段首部长度为16个字节。其最大值只能表示15,也就是说报文段的首部最大只能为60个字节(即变长只能为20个字节)。其最小值为5,因为首部最小值为20。
E)保留。占用6位。其值设为0。
F)紧急URG。其占用1位。如果URG设为1,表示首部中的紧急指针有效。表示其发送的报文段数据有紧急数据,其需要马上发送出去(也就是取得最高优先权),TCP会将紧急数据插入到该报文的最前端,后面任然为普通数据。
G)确认ACK。占用1位。当ACK=1时,表示首部中确认号字段有效,为0时,确认号字段无效。TCP规定,在连接建立后ACK字段必须为1。
H)推送PSH。占用1位。两个应用程序通信,有时应用程序希望键入一个命令马上能够得到对方回应,这是就可以使用这个字段。将PSH设为1,TCP会马上建立一个报文将其发送出去。接收端在收到该报文后,会尽快的将其交给应用程序,不用得到缓冲区满。
I)复位RST。占用1位。当RST=1时,表示连接出现严重错误,需要释放连接,然后重新进行连接。其还用于拒绝打开一个连接或拒绝非法报文。
J)同步SYN。占用1位。用于在连接建立时同步序号。当SYN=而ACK=0时,表示这是一个连接请求报文段。当SYN=1且ACK=1时,表示对方接收建立连接报文段。因此SYN=1,表示这是一个连接请求或连接接受报文段。
K)终止FIN。占用1位。当FIN=1时,表示发送方的数据发送完毕,并要求释放连接。
L)窗口。占用2个字节。表示发送该报文段的一方的接收窗口,表示允许对方发送的数据量。窗口值告诉对方:从报文段首部中的确认好算起,接收方目前允许对方发送的数据量。如:确认为801,窗口值为1000,则表示其还有接收1000个字节数据(801-1800)的接收缓存空间。
M)检验和。占2个字节。其也和UDP一样需要加上伪首部,但是其中的17会变为6。
N)紧急指针。占用2个字节。当URG=1时有效,其指出了紧急数据在报文端中的末尾位置。紧急数据在报文数据段的开始。
O)选项。可选,最大为40个字节。包括MSS、窗口扩大、时间戳、选择确认等。
TCP连接的建立采用客户服务器方式。TCP连接可分为通信双方一方发起连接和双方同时发起连接。
一方发起连接
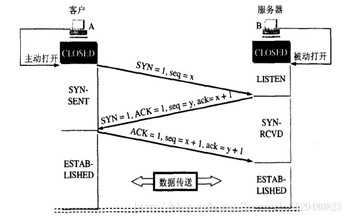
假设A方为客服端,B为服务器端,由A向B发起建立连接请求。
B的服务器进程创建传输控制块TCB,准备接受客户进程的连接请求。然后服务器进程处于LISTEN状态,等待客服端的连接请求。
A打的TCP客服端进程创建控制块TCB,然后向B发送连接请求报文段。该报文的首部SYN=1,并且假设序号seq=x。TCP规定,该连接请求报文段不携带任何数据,但需要占用一个序号。A发送了连接请求报文后进入SYN-SENT状态。
B收到A的连接请求报文后,会向A返回连接接受报文。该报文的首部SYN=1,ACK=1,seq=y,ack=x+1。TCP也规定,连接接受报文段也不携带任何数据,但也需要占用一个序号。B发送该报文后立即进入SYN-RECD状态。
A收到B的连接接受报文后,还需要向B发送一个确认报文段。在该报文中ACK=1,seq=x+1,ack=y+1。TCP规定,在该报文段中可以携带数据,也可不携带数据。但,不携带数据时,不会消耗一个序号,也就会说下一个发送的报文段的序号仍为x+1。该报文段发送成功后,进入ESTAB-LISHED状态,。
B收到A的确认后,也进入ESTAB-ISHED状态。
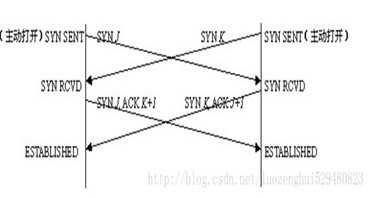
同时发起连接
出现这种同时发起连接的情况可能性极小,但TCP仍然支持这种方式,这种方式没有客户端和服务器区分,一个既是客户端又是服务器。这种方式,双方同时发起连接请求报文,并进入SYN-SENT状态。当收到对方的连接请求报文后,马上发送一个连接接受报文,并马上进入SYN-REVD状态。当收到对方的连接接受报文后,进入ESTABISHED状态。
断开连接
断开连接也可以分为由连接一方发起断开连接请求和同时发起断开连接请求。
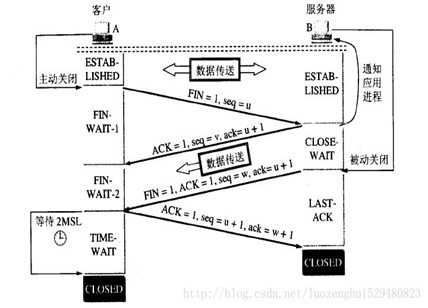
一方发起断开连接
A向B发起断开连接请求报文。该报文的首部中FIN=1,假设序列号seq=u,其为前面发送的报文段的数据的最后一个序列号加一。这是A进入FIN-WAI-1状态。TCP规定,断开连接请求报文不携带任何数据,但要消耗一个序列号。发送该报文之前会将缓冲区中的数据全部发送出去,该报文可以附加数据。
B在收到A的断开连接请求报文后,会发回一个确认报文。该报文的首部中ACK=1,ack=u+1,假设seq=v。B进入了CLOSE-WAIT状态。这时B会通知上层应用进程,这是A到B方向的连接释放了,表明A没有数据发给B了。这是可能会在该状态持续一段时间,等待B将没发送完的数据发送给A。这时A不能够发送数据给B,但A还可以接收数据。
A在收到B的确认报文后,会进入FIN-WAIT-2状态,等待B向A发送断开连接请求报文。
当B没有数据需要发送给A时,其会释放TCP连接。B向A发送断开连接请求报文。该报文的首部中FIN=1,ACK=1,ack=u+1,假设序列号为seq=w(因为可能在等待的这段时间里,B向A发送了一些数据)。这是B进入LAST-ACK状态。该报文也可以附加数据。
A收到B的断开连接请求报恩后,也会发回个确认报文。该报文中ACK=1,ack=w+1,seq=u+1。这时A进入TIME-WAIT状态。
B在收到A饿确认报文后,就彻底的断开了连接,并且会撤去相应的传输控制块。
快速断开连接:这种情况出现B发送给A断开连接确认报文,不仅为ACK而且FIN=1,也就是说在该确认报文中还包括了B的断开连接请求。这是A在收到该报文后,会给B发送一个确认报文,并进入TIME-WAIT状态。(相对于正常断开的4次握手,快速断开连接方式将第二次和第三次握手合成了一次)。
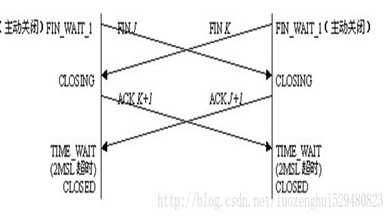
同时断开连接
两端应用层同时发出关闭命令时,两端均从 ESTABLISHED 变为 FIN_WAIT_1 。这将导致双方各发送一个 FIN ,两个 FIN 经过网络传送后分别到达另一端。收到 FIN 后,状态由 FIN_WAIT_1 变迁到 CLOSING ,并发送最后的 ACK 。当收到最后的 ACK 时,状态变化为 TIME_WAIT 状态。
答:
可以。不同的协议没有冲突。相同的协议有冲突。
SSL
标签:
原文地址:http://www.cnblogs.com/heavyhe/p/4547065.html