标签:style class blog code http color
什么是回归?
假设现在有些数据点,我用直线对这些点进行拟合(该线叫做最佳拟合直线),这个拟合的过程就叫做回归。
Logistic回归?
这里,Logistic回归进行分类的主要思想:根据现有数据对分类的边界线建立回归公式,以此边界线进行分类。这里的回归指的是最佳拟合,就是要找到边界线的回归公式的最佳拟合的参数集。训练时使用最优化算法寻找最佳拟合参数。
基于Logistic回归和Sigmoid函数的分类
对于边界线建立的回归函数,能够接受所有的输入然后预测出类别。例如,对于二分类的情况下,上述函数输出为0或者1。具有这样的性质的函数有Heaviside step function(海维塞德阶跃函数或者直接称为单位阶跃函数),然而海维塞德阶跃函数的问题在于:该函数在跳跃点上从0瞬间跳跃到1,这个瞬间跳跃的过程有时很难处理。幸好,另一个函数也有这个的性质,且数学上更容易处理,这就是Sigmoid函数。公式如下:
\(\sigma(z) = \frac{1}{1+e^{-z}}\)
Sigmoid函数图:
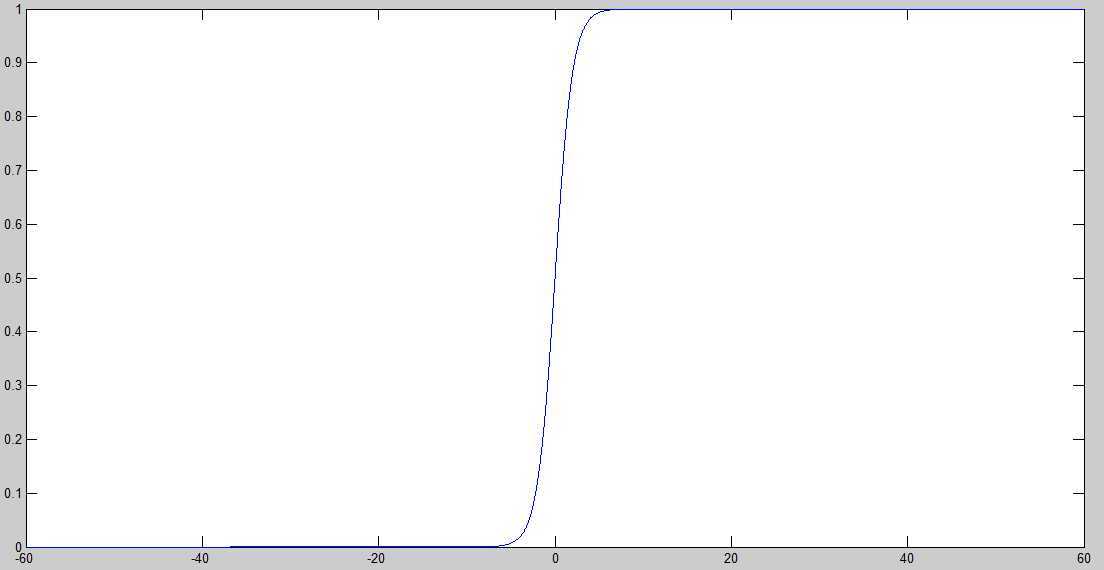
当x为0时,函数值为0.5。随着x的增大,对应的函数值将逼近1;而随着x的减小,函数值将逼近0。如果横坐标足够的大,Sigmoid函数看起来像一个阶跃函数。
因此为了实现Logistic回归分类器,我们把每个特征乘上一个回归系数,然后求和,代入Sigmoid函数,进而得到一个范围在0到1的数值,我们将如何大于0.5的数据分类为1类,而小于0.5的归为0类。所以Logistic回归可以看成一个概率的估计。
确定分类器后,现在的问题变成:最佳的回归系数是多少?如何求?
基于最优化方法的最佳回归系数求解
Sigmoidh函数的输入记为z,有下面的公式:
\(z = w_0x_0+w_1x_1+w_2x_2+...+w_nx_n\)
采用向量的写法为:\(z = w^Tx\),它表示为将系数和特征相应相乘然后全部加起来得到z值。其中x为分类器的输入数据,w是我们要求的最佳回归参数。
使用梯度上升的最优化方法求最佳回归系数
梯度上升基于的思想:沿着该函数的梯度方向寻找函数的最大值。如果梯度记为\(\nabla\),函数的梯度表示为:
\(\nabla f(x,y) = \dbinom{\frac{\partial f(x,y)}{\partial x}}{\frac{\partial f(x,y)}{\partial y}}\)
梯度的意义就是就是沿着x的方向移动\frac{\partial f(x,y)}{\partial x},沿着y移动\frac{\partial f(x,y)}{\partial y},其中函数在该店必须可微。
例子如图: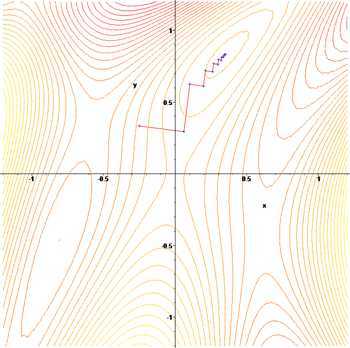
梯度算子总是指向函数值增长最快的方向,这里所说的是移动方向,而未提到移动的距离。该量值称为步长,记为\alpha。用向量的方法表示的话,梯度算法的迭代公式为:
\(w=w+\alpha \partial_wf(w)\)
该公式一直迭代执行,直到达到某个停止条件,比如迭代次数或者达到误差范围。
梯度下降算法,与这里的梯度上升方一样,只不过迭代公式中的加号改为减号。梯度上升方法求函数最大值,而梯度下降方法求函数最小值。
训练算法,使用梯度上升找到最佳参数
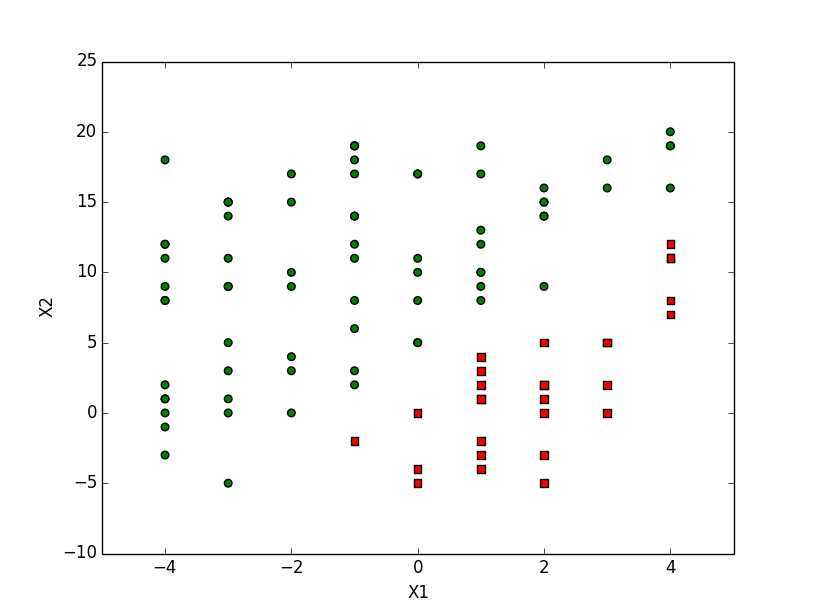
下图的样本点中绿色为0类,红色为1类,每个点包含两个数值型特征:x1和x2。在此数据集上,我们将通过使用梯度上升法找到最佳回归系数。
梯度上升法伪代码:
每个回归系数初始化为1
重复R次:
计算整个数据集的梯度
使用alpha * gradient更新回归系数的向量(也就是上面的梯度算法的迭代公式)
发挥回归系数
代码如下:
def loadDataSet(): import random dataMat = []; labelMat = [] a = random.randint(-4, 4) b = random.randint(-4, 4) c = random.randint(-4, 4) for i in range(100): x = random.randint(-4, 4) y = random.randint(-5, 20) dataMat.append([1.0, x, y]) if a + b * x + c * y >= 0: labelMat.append(1) else: labelMat.append(0) return dataMat, labelMat def sigmoid(inX): return 1.0 / (1 + exp(-inX)) def gradAscent(inDataMat, classLabels, alpha = 0.001, maxCycles = 500): dataMatrix = mat(inDataMat) labelMat = mat(classLabels).transpose() m, n = shape(dataMatrix) weights = ones((n, 1)) for k in range(maxCycles): h = sigmoid(dataMatrix * weights) error = (labelMat - h) weights = weights + alpha * dataMatrix.transpose() * error return weights
分析数据画出决策的边界
代码如下:
def plotBestFit(dataMat, labelMat, wei): import matplotlib.pyplot as plt # weights = wei.getA() weights = wei dataArr = array(dataMat) n = shape(dataArr)[0] xcord1 = []; ycord1 = [] xcord2 = []; ycord2 = [] for i in range(n): if int(labelMat[i]) == 1: xcord1.append(dataArr[i, 1]); ycord1.append(dataArr[i, 2]) else: xcord2.append(dataArr[i, 1]); ycord2.append(dataArr[i, 2]) fig = plt.figure() ax = fig.add_subplot(111) ax.scatter(xcord1, ycord1, s = 30, c = ‘red‘, marker = ‘s‘) ax.scatter(xcord2, ycord2, s = 30, c = ‘green‘) x = arange(-4.0, 4.0, 0.1) y = (-weights[0] - weights[1] * x) / weights[2] ax.plot(x, y) plt.xlabel(‘X1‘); plt.ylabel(‘X2‘) plt.show()
效果如下:
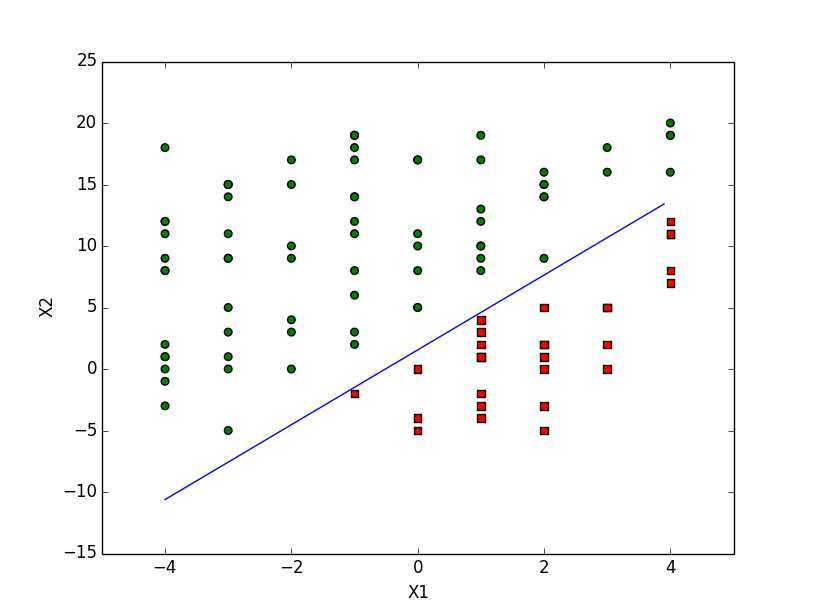
上述代码中的
y = (-weights[0] - weights[1] * x) / weights[2]
设置了sigmoid函数的输入为0,因为我们上面分类器设计是sigmoid的输入为0时,sigmoid函数值为0.5,为分类的边界值。因此这里的0就是\(z = w^Tx\)函数的分界处。因此,设定\(0 = w_0x_0 + w_1x_1 + w_2x_2\),然后解出x2和x1的关系式(注意\(x_0=1\))。
梯度上升方法的改进:随机梯度上升法
梯度上升算法每次更新回归系数时都需要遍历整个数据集,一种改进的方法就是一次仅用一个样本点更新回归系数,该方法称为随机梯度上升法。由于可以在样本点到来时对分类器进行增量式更新,因而随机梯度上升方法是一个在线的学习算法。
伪代码如下:
所有回归系数初始化为1、
对于数据集的每个样本:
计算该样本的梯度
使用alpha * gradient更新回归系数
返回回归系数
实现的代码如下:
def stocGradAscent0(inDataMat, classLabels, alpha = 0.01): dataMatrix = array(inDataMat) m, n = shape(dataMatrix) weights = ones(n) for i in range(m): h = sigmoid(sum(dataMatrix[i] * weights)) error = classLabels[i] - h weights = weights + alpha * error * dataMatrix[i] return weights
再次改进随机梯度上升方法,每次迭代是步长alpha逐渐变小,趋于0,以减小回归系数的波动,代码如下:
def stocGradAscent1(inDataMat, classLabels, maxCycles = 150): import random dataMatrix = array(inDataMat) m, n = shape(dataMatrix) weights = ones(n) for j in range(maxCycles): dataIndex = range(m) for i in range(m): alpha = 4 / (1.0 + j + i) + 0.01 randIndex = int(random.uniform(0, len(dataIndex))) h = sigmoid(sum(dataMatrix[randIndex] * weights)) error = classLabels[randIndex] - h weights = weights + alpha * error * dataMatrix[randIndex] return weights
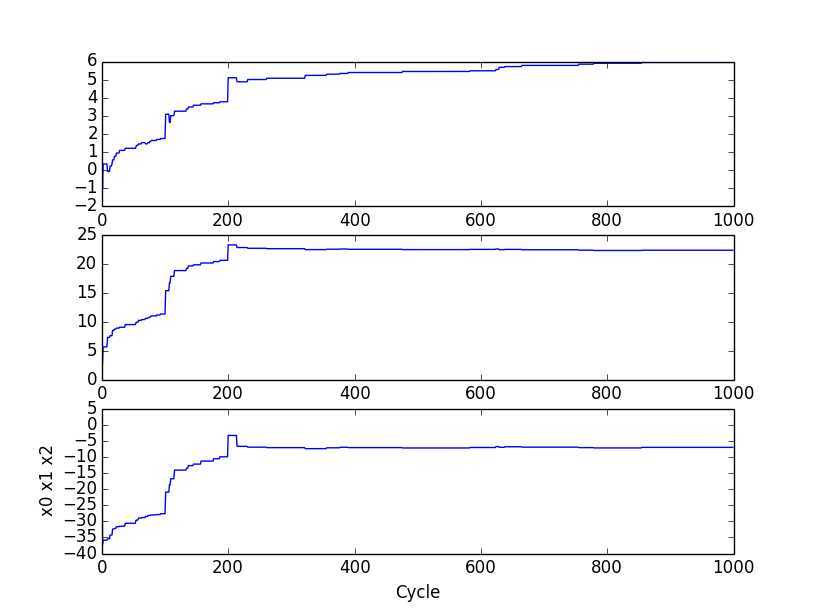
下图显示每次迭代各个回归系数的变化情况。
标签:style class blog code http color
原文地址:http://www.cnblogs.com/zjwzcnjsy/p/3791653.html