标签:
索引的查询处理
为搜索引擎构建索引,其目的是能更快速地提取与用户查询相关的文档信息,假设搜索引擎已经建立了索引,我们如何利用倒排索引来相应用户的查询呢?这一次的总结就是给大家分享一下搜索引擎对于用户查询的处理过程。
目前有两种常见的查询处理机制,一种称为一次一文档方式,另外一种称为一次一单词方式。
下面我们用一个具体例子来分别说明两种基本查询处理方式的运行机制。在这个例子里,假设用户输入的查询为“搜索引擎 技术”,而“搜索引擎”这个单词对应的倒排列表中,文档ID依次为{1,3,4},“技术”这个单词对应的倒排列表中,文档ID列表为{1,2,4}。此时我们可以看出,文档1和4同时包含了这两个查询词。
所谓的一次一文档,就是以倒排列表中包含的文档为单位,每次将其中某个文档与查询的最终相似性得分计算完毕,然后开始计算另外一个文档的最终得分,直到所有的文档的得分都计算完毕为止。
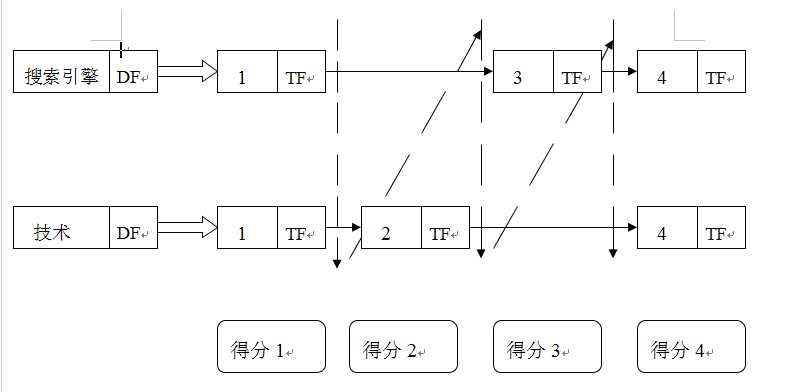
对于文档1来说,因为两个单词的倒排列表中都包含这个文档,所以可以根据各自的TF(单词在文档中出现的次数)和IDF(逆文档频率)等参数计算文档和查询单词的相似性,之后将两个分数相加就获得了文档1和用户查询的相似性得分。随后搜索系统开始处理文档2,因为文档2只在“技术”这个词汇的倒排列表中,所以通过TF和IDF即可得出文档2和用户查询的相似性得分。用类似的方法处理文档3和文档4。所有文档都计算完毕后,根据文档得分进行大小排序,输出得分最高的K个文档作为搜索结果输出,即可完成了一次用户查询的响应。
因为搜索系统的输出结果往往是限定个数的,比如指定输出10个结果,所以在实际实现一次一文档时,没有必要保存所有文档的相关性得分,我们只需要在内存中维护一个大小为10的优先级别队列,用来保存目前计算过程中得分最高的K个文档即可,这样可以节省内存和计算时间,一般采用堆来实现这个优先级别队列。
在一次一文档中,我们对单词—文档矩阵中以文档为单位,纵向进行分数累计。而一次一单词则是采取“先横向再纵向”的方式,即首先将某个单词对应的倒排列表中的每个文档ID都计算一个部分相似性得分,在计算完毕某个单词倒排列表中包含的所有文档之后,接着计算下一个单词的倒排列表中包含的文档。
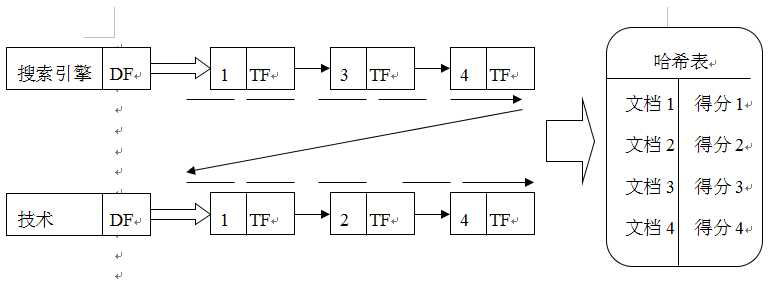
上图所示就是一次一单词的运算机制图示说明。为了保存数据,在内存中使用哈希表来保存中间结果以及最终计算结果。搜索系统首先对包含“搜索引擎”的所有文档进行部分得分计算,并把相似性得分保存在哈希表中。当“搜索引擎”这个单词的所有文档都计算完毕后,开始计算“技术”这个单词的相似性得分,对于文档1来说,同样根据TF和IDF等参数计算文档1和“技术”这个单词的相似性得分,之后查找哈希表,发现文档1已经存在得分(计算“搜索引擎”相似性得分所得),则将哈希表对应的得分和刚刚计算出的得分相加作为最终得分,之后采取相似的方法,依次计算文档2和文档4与“技术”的相似性得分。当全部计算完毕时,哈希表中存储了每个文档和用户查询的最终相似性得分,排序后输出得分最高的K个文档作为搜索的响应结果。这样,就以一次一单词的方式完成了对用户查询的响应。
跳跃指针:查询处理的优化
如果用户输入的查询包含了很多个查询词,搜索引擎一般默认是采取与逻辑来判别文档是否满足要求,即要求文档里必须全部包含查询词,就刚才的例子来说,查询“搜索引擎 技术”这两个关键词,就只有文档1和4符合条件。在这种情况下,很明显我们采用一次一文档的查询处理方式是比较适合的(为什么吗?这个可以自己思考)。
如果倒排列表直接存储包含查询词的文档ID,那么计算交集是非常直观和简单的,我们可以通过归并排序即可获得O(n+m)的时间复杂度的算法,效率还算可以吧。但是,我们之前就讲过,倒排列表中文档的ID是以差值的形式存储的,另外这个差值是以压缩后的方式编码的,那么如何求倒排列表的交集就会变得复杂。
跳跃指针的基本思想是将一个倒排列表数据化整为零,切分为若干个固定大小的数据块,一个数据块为一组,对于每个数据块,增加元信息来记录关于这个块的一些信息,这样即使面对压缩后的倒排列表,在进行倒排列表合并的时候也有两个好处:一个好处是无需解压缩所有倒排列表项,只解压部分数据即可;另一个好处就是无需比较任意两个文档ID,通过这两种方式有效节省了计算资源和存储资源。
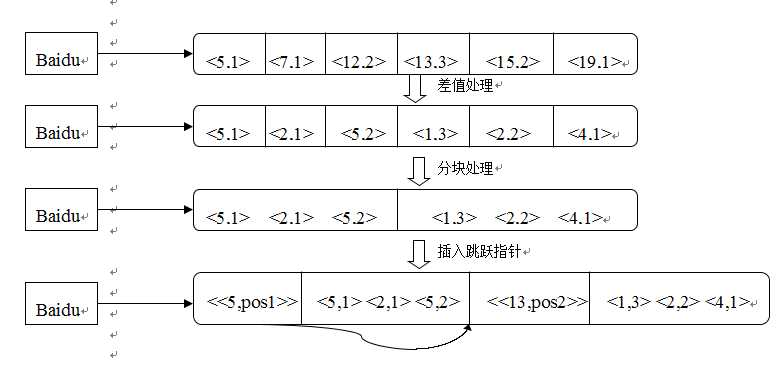
说明:图中设定的分组大小为3,书中提到假设倒排列表长度为L(即包含L个文档),使用根号L来作为块的大小效果较好。
问题马上来了,我们如何在一个带有跳跃指针的倒排列表里查找某个文档是否存在呢?
假如我们需要在单词“Baidu”压缩后的倒排列表里查找文档编号为7的文档。首先,对倒排列表前两个数值进行数据解压缩,读取第一组的跳跃指针数据,发现其值为<5,pos1>,其中pos1指出了第二组的跳跃指针在倒排列表中的起始位置,于是可以解压缩pos1位置处连续两个数值,得到了<13,pos2>。跳跃指针的数值分别为5和13,分别表示两组数据中最小编号文档的文档ID,所以我们查找的文档一定在第一组中,否则说明倒排列表中不包含这个文档。于是就对第一组中的数据进行解压缩,并根据最小文档编号逆向恢复其原始的文档编号。而求两个查询词的倒排列表交集就是反复在两个倒排列表中查找某个文档是否存在,将同时存在两个倒排列表中的文档ID作为计算结果。
从上面的查找说明来看,相对不包含跳跃指针的索引来说,我们只需要对其中一个数据块进行解压缩和文档编号查找即可获得结果,不用将所有索引数据都进行解压缩和比较操作。很明显这加快了查找速度,提高了效率。
标签:
原文地址:http://www.cnblogs.com/BaiYiShaoNian/p/4550060.html