标签:
1, 下载Solr4.4 Tomcat7
2, 拷贝 solr-4.4.0\dist\solr4.4.war => tomcat\webapps 下面 重命名为solr.war
3, 启动tomcat solr.war 将自动(注意是自动而不需要手动)解压成 solr文件夹
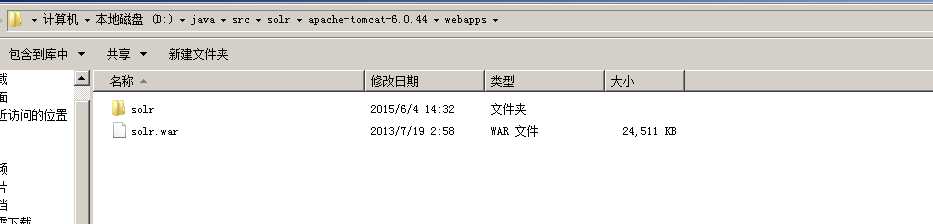
4, tomcat\webapps 下面新建目录home 把solr-4.4.0\example\solr下面的文件拷贝过来
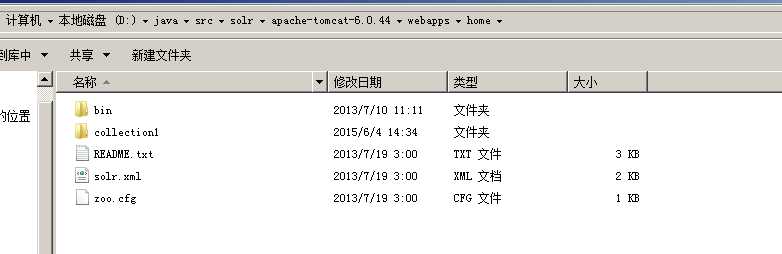
5, solr-4.4.0\example\lib\ext 下面的jar包拷贝到 tomcat\webapps\solr\WEB-INF\lib 下面
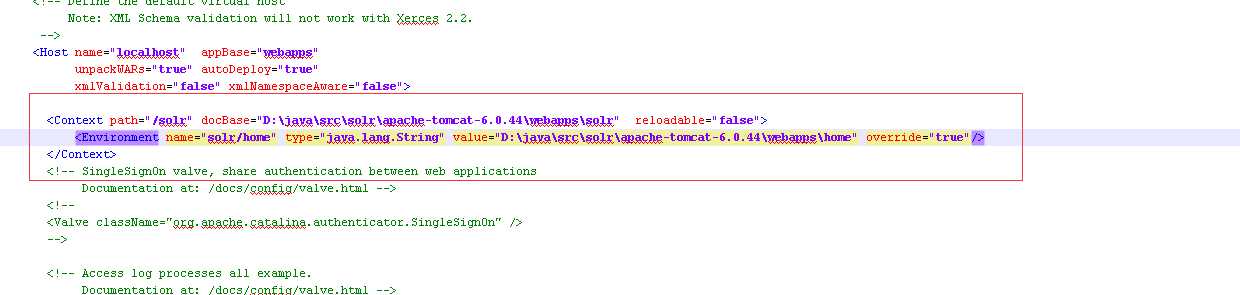
6, 修改tomcat\conf 下面的server.xml, docBase 分别改成你的 solr路径(服务器路径) home路径
<Context path="/solr" docBase="D:\java\src\solr\tomcat_solr_4.4\webapps\solr" reloadable="false"> <Environment name="solr/home" type="java.lang.String" value="D:\java\src\solr\tomcat_solr_4.4\webapps\home" override="true"/> </Context>
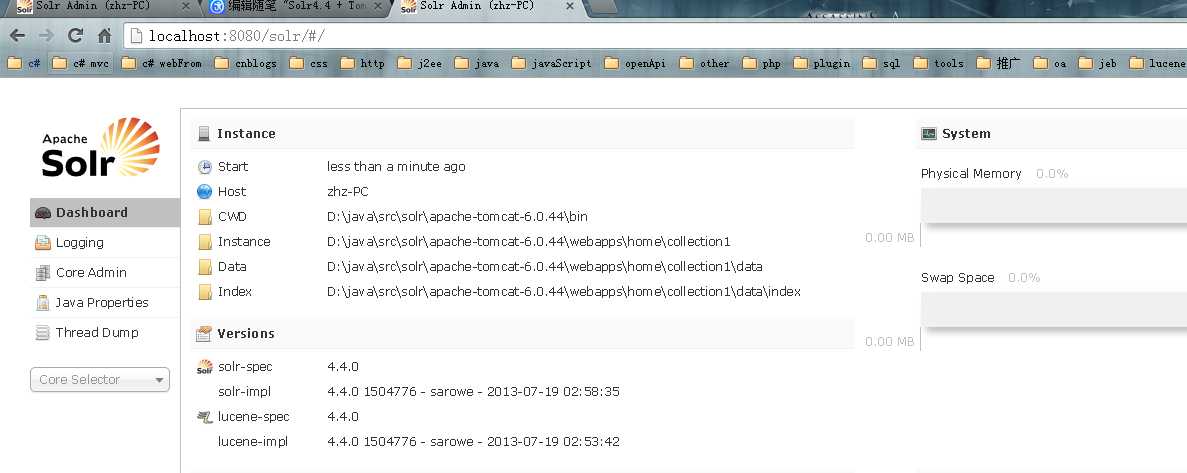
7, 重写启动即可
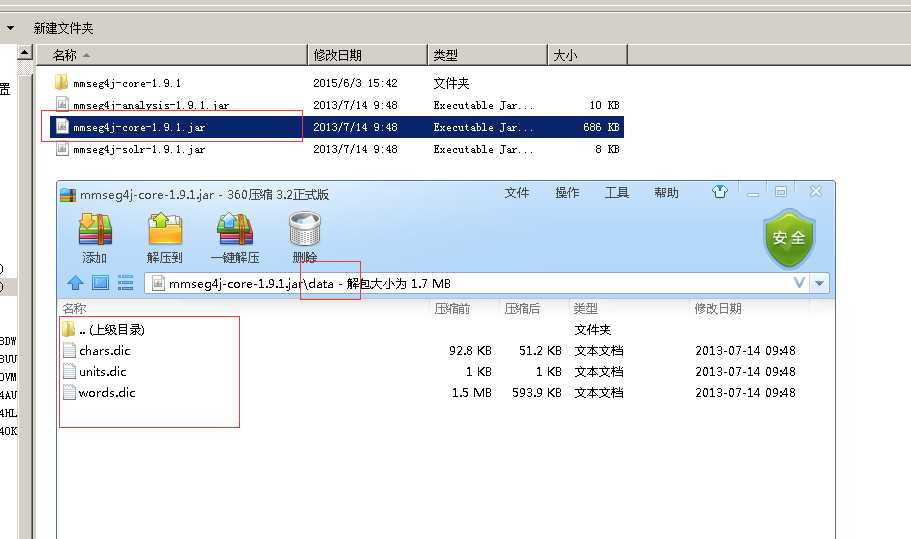
8, 加入中文分词. 下载 mmseg4j-1.9.1
9, tomcat\webapps\home\collection1\conf 下面的 schema.xml
<fieldType name="textComplex" class="solr.TextField" positionIncrementGap="100" > <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="dic"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType> <fieldType name="textMaxWord" class="solr.TextField" positionIncrementGap="100" > <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" dicPath="dic"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType> <fieldType name="textSimple" class="solr.TextField" positionIncrementGap="100" > <analyzer> <tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="dic"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
10, 加入mmseg4j1.9.1.jar 的jar包到tomcat\webapps\solr\WEB-INF\lib 下面
11, 重新启动tomcat
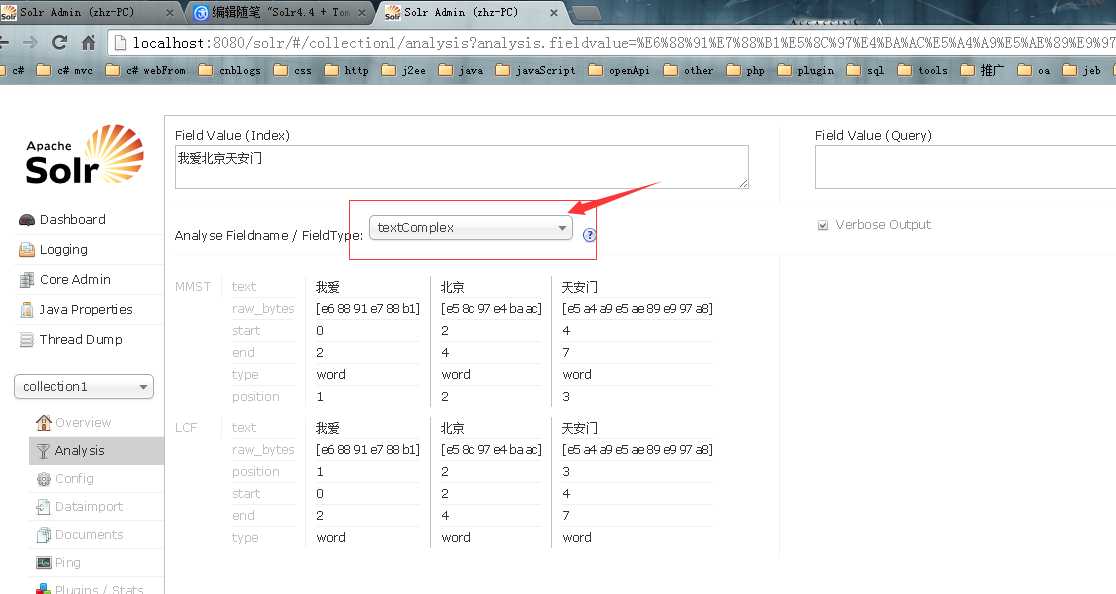
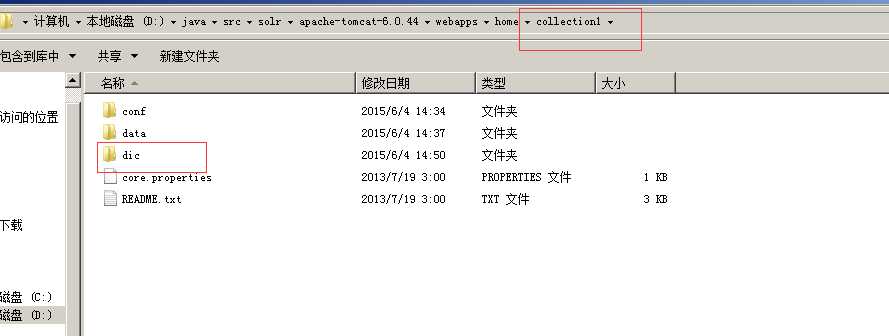
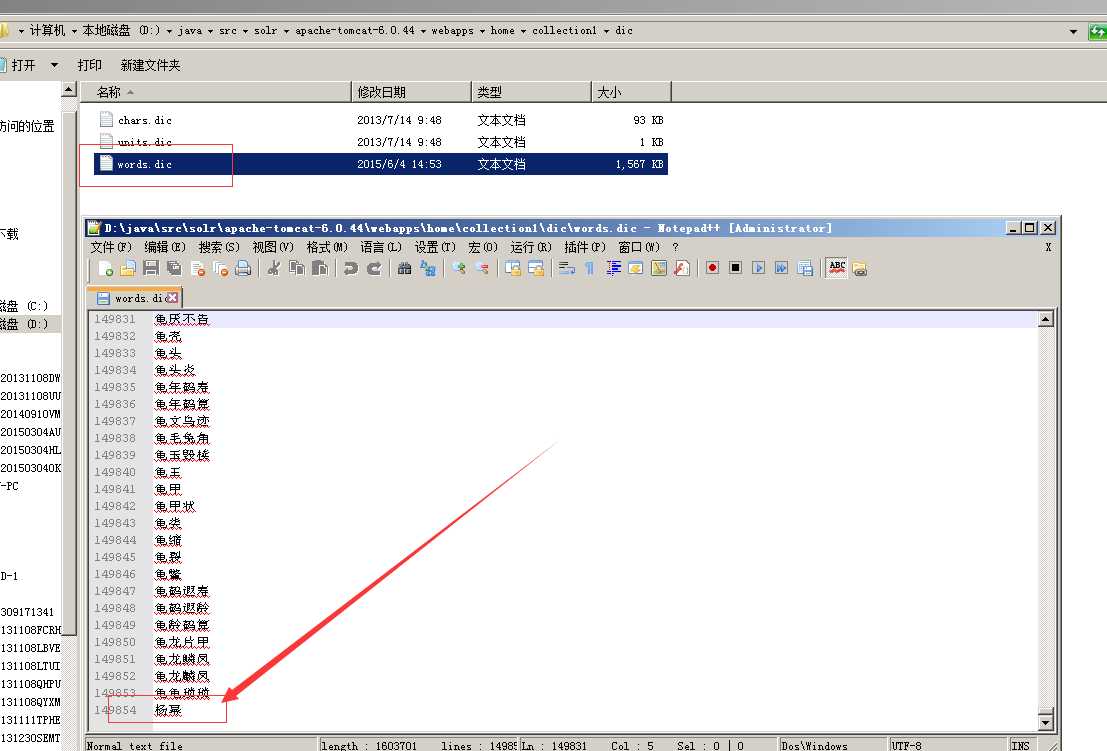
12. 其他 由于mmseg4j1.9.1.jar 内置了词库, 如果想增加词库的话, 在home目录也就是tomcat\webapps\home\collection1 目录下面新建dic 文件夹, 将mmseg4j1.9.1.jar 解压,里面的词库拷贝出来,复制进去便于新增自己的分词
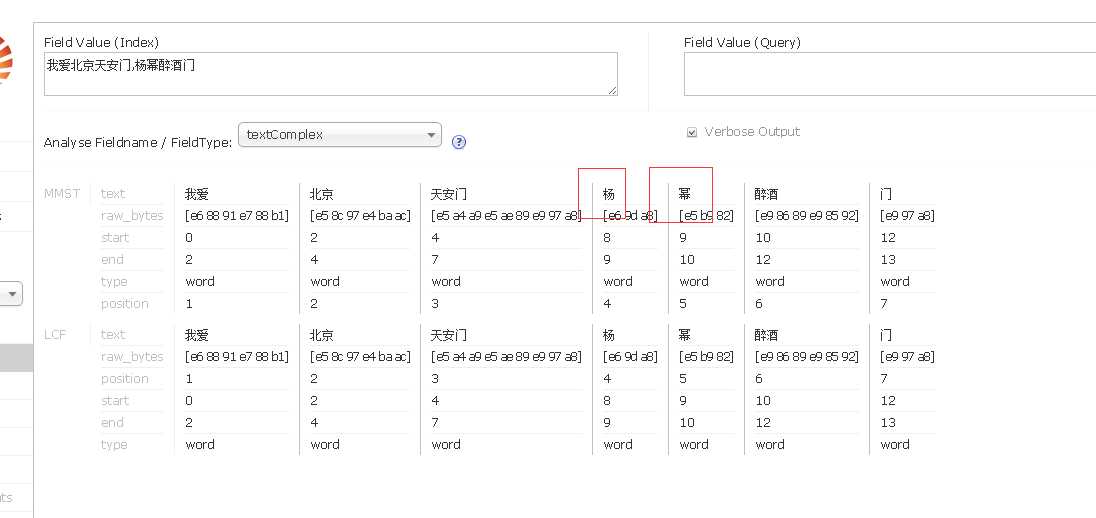
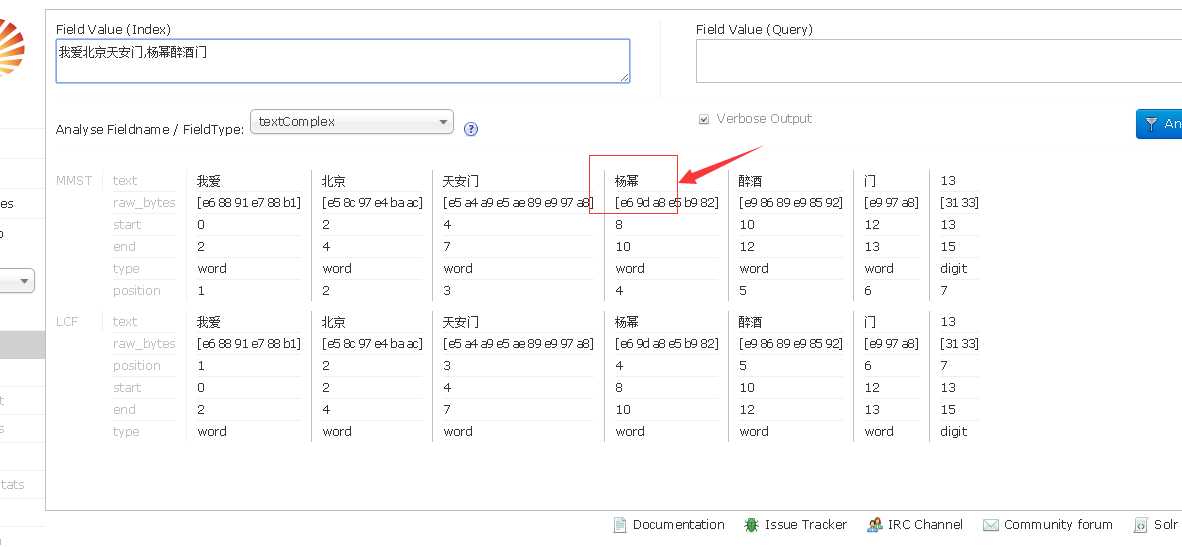
看到了吧这个鸟人他不认识
标签:
原文地址:http://www.cnblogs.com/jgl5981/p/4551765.html