标签:style class blog code http color
概述:排序算法可分为比较性的排序,以及运算性的排序;这里详细介绍这些排序的原理,性能,实现,以及应用场合。
前面是维基百科的介绍,这里介绍几个比较典型的算法。
理论
交换排序
选择排序
插入排序
归并排序
分布排序
并发排序
混合排序
其他
以下介绍典型的算法:::::----》》》》
比较排序
一:快速排序(交换排序2号)
1:原理
采用了分治思想,在序列A[p...r]中选取一个元素,当然这里是用了p或者r处的元素(规格一致);找到该元素的,满足前面的值都比它小,后面的都比它大;同理让子序列递归下去。
2:性能
最坏时间复杂度:θ(n²)---出现在序列是顺序的,导致极度不平衡划分,1:0效果划分。
最好时间复杂度:θ(nlog2(n))---出现在每次划分都是在中间处;
中间状态:比如划分比例是a:b;则复杂度就是a/(b+a);b/(b+a)取大的(假设为a/(b+a)),则复杂度为θ(nlog(b+a)/a(n))其实也可以是θ(nlog(n))
平均复杂度也就是θ(nlog(n));
空间复杂度为:O(logn)----递归引起;
3:应用
实际排序中比较好,适合对平均时间复杂度有要求,要求原址排序,且隐含因子比较小;应用场景多。百万数量级以下合适
4:实现----c++代码实现如下
void exchang(int * sort,int i,int j) { int temp=0; temp=sort[i]; sort[i]=sort[j]; sort[j]=temp; } int partition(int *sort ,int p,int r) { int x=sort[r]; int i=p-1; for(int j=p;j<r;j++)//p--->r-1 if(sort[j]<=x) { i++; if(i!=j) exchang(sort,i,j); } if((i+1)<r) exchang(sort,i+1,r); return i+1; } //栈溢出,原因是它递归太深了 void QuickSort(int *sort ,int sn,int en) { if(sn<en) { int q=partition(sort,sn,en); QuickSort(sort,sn,q-1); QuickSort(sort,q+1,en); } }
第二:插入排序
第三:归并排序
第四:堆排序
1:原理
2:性能
3:应用
4:实现
//数据交换 void Exchang(int * sort,int i,int j) { int temp=0; temp=sort[i]; sort[i]=sort[j]; sort[j]=temp; } //修改堆 void MaxHeapIfy(int *ops,int i,int heapsize) { int l=2*i+1;//left int r=2*(i+1); int max; if((l<=heapsize-1)&&ops[l]>ops[i]) max=l; else max=i; if((r<=heapsize-1)&&ops[r]>ops[max]) max=r; if(max!=i) { exchang(ops,i,max); maxheapify(ops,max,heapsize); } } //构建堆 void BuildMaxHeap(int *ops,int length) { for(int i=(length-2)/2;i>=0;i--) maxheapify(ops,i,length); } //树也有递归,但是树本身不会那么深。 void HeapSort(int *ops,int length) { buildmaxheap(ops,length); for(int i=length-1;i>=1;i--) { exchang(ops,0,i); length--; maxheapify(ops,0,length); } }
第五:选择排序
1:原理
通过比较,先找出最大值或者最小值,找到后就将其放到队首,这样下来就是顺序的了。
2:性能
最差时间复杂度О(n²)
最优时间复杂度О(n²)
平均时间复杂度О(n²)
空间复杂度:1
3:应用
n小时比较合适,算法简单,是比较后排序;使用场合少
4:c++实现
void SelectionSort(int* unsorted,int length) { for (int i = 0; i < length; i++) { int min = unsorted[i], min_index = i; for (int j = i; j < length; j++) { if (unsorted[j] < min)//选择最小值处 { min = unsorted[j]; min_index = j; } } if (min_index != i)//选出后交换 { int temp = unsorted[i]; unsorted[i] = unsorted[min_index]; unsorted[min_index] = temp; } } }
第六:冒泡排序(交换排序1号)
1:原理
通过比较,不断冒充最大值或者最小值,它和选择排序相似,选择排序是先找最小值,再交换;而冒泡是比较一次就会交换,从效率上将,冒泡排序不如选择排序。
2:性能
最差时间复杂度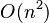
最优时间复杂度 为什么是这个值,因为可以往后冒泡,产生的结果就可以达到这个效果。。。。
为什么是这个值,因为可以往后冒泡,产生的结果就可以达到这个效果。。。。
平均时间复杂度
3:应用
应用类似插入算法
4:实现
1)往前冒泡
void BubbleSort(int *unsorted,int length) { for (int i = 0; i <length ; i++) { for (int j = i; j < length; j++) { if (unsorted[i] > unsorted[j]) { int temp = unsorted[i]; unsorted[i] = unsorted[j]; unsorted[j] = temp; } } } }
2)往后冒泡(C#)
public void bubbleSort(int arr[]) { boolean didSwap; for(int i = 0, len = arr.length; i < len - 1; i++) { didSwap = false; for(int j = 0; j < len - i - 1; j++) { if(arr[j + 1] < arr[j]) { swap(arr, j, j + 1); didSwap = true; } } if(didSwap == false) return; } }
第七:希尔排序
1:原理
通过分组排序,比如以某个增量d,也就是分成d组,在d组内中进行插入排序;不断让d减小,使的最后为1,也就是到达了直接排序效果;和插入比较有何体现呢?插入最坏是O(n²),最好是O(n)。但是在n小时相差不大,这就是用分组减小n,而后期的组数少了,但是排序好了,则会走向好的情况,故而总体是效率高了。

2:性能
最坏时间复杂度:O(ns),s大致是1~2;
平均时间复杂度:O(nlog(n));
最好时间复杂度:O(n)
注:n较大时目前一般是n1.25到1.6n1.25之间。
3:应用
它优于插入算法,不稳定。
4:实现
// //采取2的k次幂-1是最佳的,k表示第几趟 //最后一个步长是1 //k是趟数,这个可以自己设定。。。。 // //通俗版本,比较简单 void ShellSort(int* a, int length) { int gap; //增量,,组 for(gap = 3; gap >0; gap--) //3组。。。自己也可以设定大一点组, { for(int i=0; i<gap; i++) //显然这种分组的步长是1 { for(int j = i+gap; j<length; j=j+gap) // { if(a[j]<a[j-gap]) { int temp = a[j]; int k = j-gap; while(k>=0&&a[k]>temp) { a[k+gap] = a[k]; k = k-gap; } a[k+gap] = temp; } } } } } //通用版本,,比较灵活 void ShellSort(int a[], int n , int d[] ,int numOfD) { int i,j,k; int val; int span; //增量 for(int m=0; m<numOfD; m++) //m趟 { span=d[m]; for(k=0; k<span; k++) //span个小组 { //组内进行直接插入排序 ,区别在于每次不是增加1,而是增加span for(i=k; i<n-span; i+=span) { val=a[j+span]; j=i; while(j>-1 && val<a[j]) { a[j+span]=a[j]; j=j-span; } a[j+span]=val; } } } }
第八:鸡尾酒排序
1:原理
在冒泡基础上改进,让单向冒泡变成双向冒泡;结束时是两个冒泡起点重合时。
2:性能
最坏情况还是和冒泡一致;n的2次方
但是好的和插入相似了。为n;它比直接冒泡要好;
空间复杂度:1
3:应用
性能和直接插入算法相似,故而和插入算法应用相似。
4:实现
void CocktailSort(int * list, int list_length) { int bottom = 0; int top = list_length - 1; int bound = 0; //优化循环次数,记录已经排序的边界,减少循环次数 while(bottom!=top) //表示已全部冒泡完了,就是已经成为顺序了 { for(int i = bottom; i < top; i = i + 1) {//顺冒泡 if(list[i] > list[i+1]) { swap(list[i], list[i+1]); bound = i; } } top = bound; for(int i = top; i > bottom; i = i - 1) {//反顺冒泡 if(list[i] < list[i-1]) { swap(list[i], list[i-1]); bound = i; } } bottom = bound; } }
第九:地精排序
1:原理
在冒泡基础上改进的,它的效果和插入排序相似,号称是简单的排序算法,算法实现非常短。
2:性能
性能和插入排序一样
3:应用
应用和插入排序一样
4:实现
void GnomeSort(int* unsorted,int length) { int i = 0; while (i < length)//到达最后一个表示完成了 { if (i == 0 || unsorted[i - 1] <= unsorted[i]) {//表示能前进的条件,i=0或者是没有交换 i++; } else {//发生交换了 int tmp = unsorted[i]; unsorted[i] = unsorted[i - 1]; unsorted[i - 1] = tmp; i--; } } }
第十:奇偶排序
1:原理
选取奇数,和它相邻比较,排序;同样对偶数也这样,最后达到没有交换了,此时就是顺序的了
2:性能
平均时间复杂度:O(n2);
最好时间复杂度:O(n);
最差时间复杂度:O(n2);
可以看到有点像插入排序了;不稳定
3:应用
和插入排序应用相似。。。
4:实现
void OddEvenSort(int * szArray,int length) { bool sorted = false; while (!sorted) { sorted = true; for (int i = 1; i < length - 1; i += 2) { //偶数排 if (szArray[i]>szArray[i + 1]) { int tmp = szArray[i]; szArray[i] = szArray[i+1]; szArray[i+1] = tmp; sorted = false; } } for (int i = 0; i < length - 1; i+= 2) { //奇数排 if (szArray[i]>szArray[i + 1]) { int tmp = szArray[i]; szArray[i] = szArray[i+1]; szArray[i+1] = tmp; sorted = false; } } } }
第十一:梳排序
1:原理
它是基于冒泡和插入排序的结合品,选取了适合的比率,进行冒泡。
2:性能
最差时间复杂度
最优时间复杂度
平均时间复杂度 ,p是比率;
,p是比率;
空间复杂度:1。。。。不稳定
3:应用
类似插入算法应用
4:实现
void CombSort(int *arr, int size) { double shrink_factor = 1.247330950103979;//1.3比率 int gap = size; int swapped = 1; int swap; int i; while ((gap > 1) || swapped) { if (gap > 1) { gap = gap / shrink_factor;//计算间距 } //直到gap为1时表示已经再距离上已经是到达了 //此时就和冒泡一致了,外循环加内循环了,直到不再交换为止。。。 swapped = 0; i = 0; while ((gap + i) < size) { if(arr[i]-arr[i+gap] > 0) { swap = arr[i]; arr[i] = arr[i+gap]; arr[i+gap] = swap; swapped = 1; } ++i; } } }
下一遍----->运算类的排序<-------下一篇
排序算法总结----比较类排序,布布扣,bubuko.com
标签:style class blog code http color
原文地址:http://www.cnblogs.com/miner007/p/3793549.html