标签:Lucene style class blog code java
搭建环境
搭建Lucene的开发环境只需要加入Lucene的Jar包,要加入的jar包至少要有:
lucene-core-3.0.1.jar(核心包)
contrib\analyzers\common\lucene-analyzers-3.0.1.jar(分词器)
contrib\highlighter\lucene-highlighter-3.0.1.jar(高亮)
contrib\memory\lucene-memory-3.0.1.jar(高亮)
Article.java

1 package cn.itcast._domain; 2 public class Article { 3 4 private Integer id; 5 private String title; 6 private String content; 7 8 public Integer getId() { 9 return id; 10 } 11 12 public void setId(Integer id) { 13 this.id = id; 14 } 15 16 public String getTitle() { 17 return title; 18 } 19 20 public void setTitle(String title) { 21 this.title = title; 22 } 23 24 public String getContent() { 25 return content; 26 } 27 28 public void setContent(String content) { 29 this.content = content; 30 } 31 32 }
HelloWorld.java
1 package cn.itcast.helloworld; 2 3 import java.io.File; 4 import java.io.IOException; 5 import java.util.ArrayList; 6 import java.util.List; 7 8 import org.apache.lucene.analysis.Analyzer; 9 import org.apache.lucene.analysis.standard.StandardAnalyzer; 10 import org.apache.lucene.document.Document; 11 import org.apache.lucene.document.Field; 12 import org.apache.lucene.document.Field.Index; 13 import org.apache.lucene.document.Field.Store; 14 import org.apache.lucene.index.IndexWriter; 15 import org.apache.lucene.index.IndexWriter.MaxFieldLength; 16 import org.apache.lucene.queryParser.QueryParser; 17 import org.apache.lucene.search.IndexSearcher; 18 import org.apache.lucene.search.Query; 19 import org.apache.lucene.search.ScoreDoc; 20 import org.apache.lucene.search.TopDocs; 21 import org.apache.lucene.store.Directory; 22 import org.apache.lucene.store.FSDirectory; 23 import org.apache.lucene.util.Version; 24 import org.junit.Test; 25 26 import cn.itcast._domain.Article; 27 28 public class HelloWorld { 29 30 private static Directory directory; // 索引库目录 31 private static Analyzer analyzer; // 分词器 32 33 static { 34 try { 35 directory = FSDirectory.open(new File("./indexDir")); 36 analyzer = new StandardAnalyzer(Version.LUCENE_30); 37 } catch (IOException e) { 38 throw new RuntimeException(e); 39 } 40 } 41 42 // 建立索引 43 @Test 44 public void testCreateIndex() throws Exception { 45 // 准备数据 46 Article article = new Article(); 47 article.setId(2); 48 article.setTitle("准备Lucene的开发环境"); 49 article.setContent("如果信息检索系统在用户发出了检索请求后再去互联网上找答案,根本无法在有限的时间内返回结果。"); 50 51 // 放到索引库中 52 // 1, 把Article转为Document 53 Document doc = new Document(); 54 String idStr = article.getId().toString(); //这个使用的话效率降低 被遗弃了 55 String idStr = NumericUtils.intToPrefixCoded(article.getId()); // 一定要使用Lucene的工具类把数字转为字符串! 56 //目录区域 和 数据区 57 doc.add(new Field("id", idStr, Store.YES, Index.ANALYZED)); 58 doc.add(new Field("title", article.getTitle(), Store.YES, Index.ANALYZED)); 59 doc.add(new Field("content", article.getContent(), Store.NO, Index.ANALYZED)); 60 61 // 2, 把Document放到索引库中 在目录中的长度 源码 Integer.Max_Value 62 IndexWriter indexWriter = new IndexWriter(directory, analyzer, MaxFieldLength.UNLIMITED); 63 indexWriter.addDocument(doc); 64 indexWriter.close(); 65 } 66 67 // 搜索 68 @Test 69 public void testSearch() throws Exception { 70 // 准备查询条件 71 String queryString = "lucene的"; 72 // String queryString = "hibernate"; 73 74 // 执行搜索 75 List<Article> list = new ArrayList<Article>(); 76 77 // ========================================================================================== 78 79 // 1,把查询字符串转为Query对象(默认只从title中查询) 80 QueryParser queryParser = new QueryParser(Version.LUCENE_30, "title", analyzer); 81 Query query = queryParser.parse(queryString); 82 83 // 2,执行查询,得到中间结果 84 IndexSearcher indexSearcher = new IndexSearcher(directory); // 指定所用的索引库 85 TopDocs topDocs = indexSearcher.search(query, 100); // 最多返回前n条结果 86 87 int count = topDocs.totalHits; 88 ScoreDoc[] scoreDocs = topDocs.scoreDocs; 89 90 // 3,处理结果 91 for (int i = 0; i < scoreDocs.length; i++) { 92 ScoreDoc scoreDoc = scoreDocs[i]; 93 float score = scoreDoc.score; // 相关度得分 94 int docId = scoreDoc.doc; // Document的内部编号 95 96 // 根据编号拿到Document数据 97 Document doc = indexSearcher.doc(docId); 98 99 // 把Document转为Article 100 String idStr = doc.get("id"); // 101 String title = doc.get("title"); 102 String content = doc.get("content"); // 等价于 doc.getField("content").stringValue(); 103 104 Article article = new Article();
Integer id = NumericUtils.prefixCodedToInt(doc.get("id")); // 一定要使用Lucene的工具类把字符串转为数字! 105 article.setId(id); 106 article.setTitle(title); 107 article.setContent(content); 108 109 list.add(article); 110 } 111 indexSearcher.close(); 112 113 // ========================================================================================== 114 115 // 显示结果 116 System.out.println("总结果数:" + list.size()); 117 for (Article a : list) { 118 System.out.println("------------------------------"); 119 System.out.println("id = " + a.getId()); 120 System.out.println("title = " + a.getTitle()); 121 System.out.println("content = " + a.getContent()); 122 } 123 } 124 }
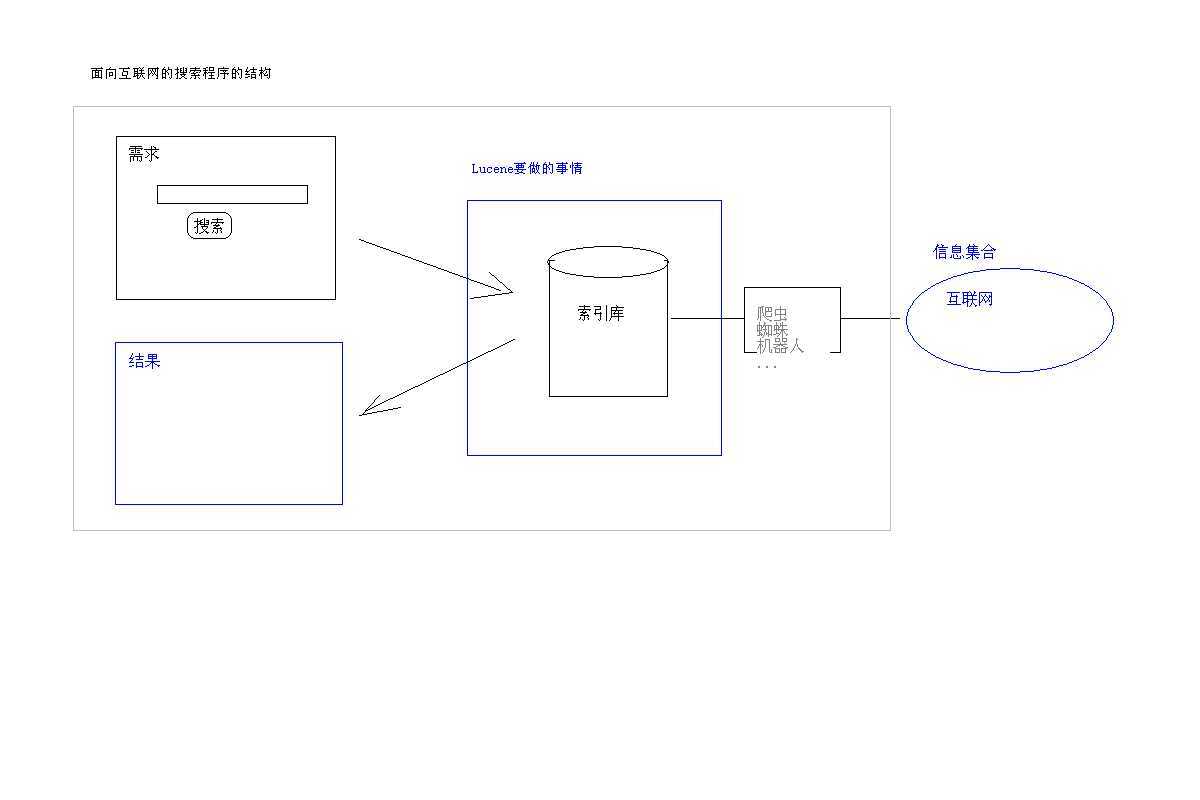
1-_搜索互联网资源的程序结构.PNG
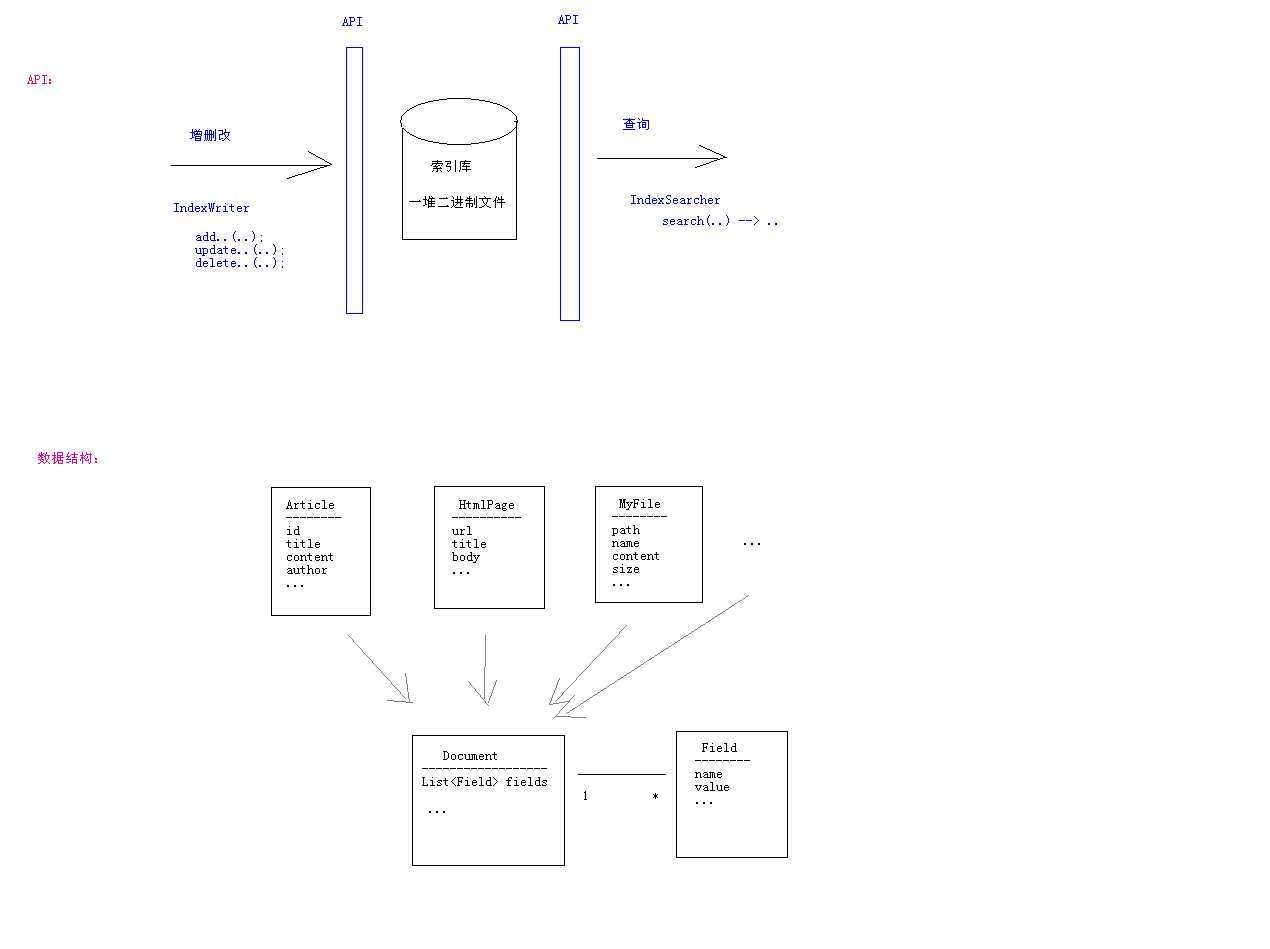
索引库的内部结构

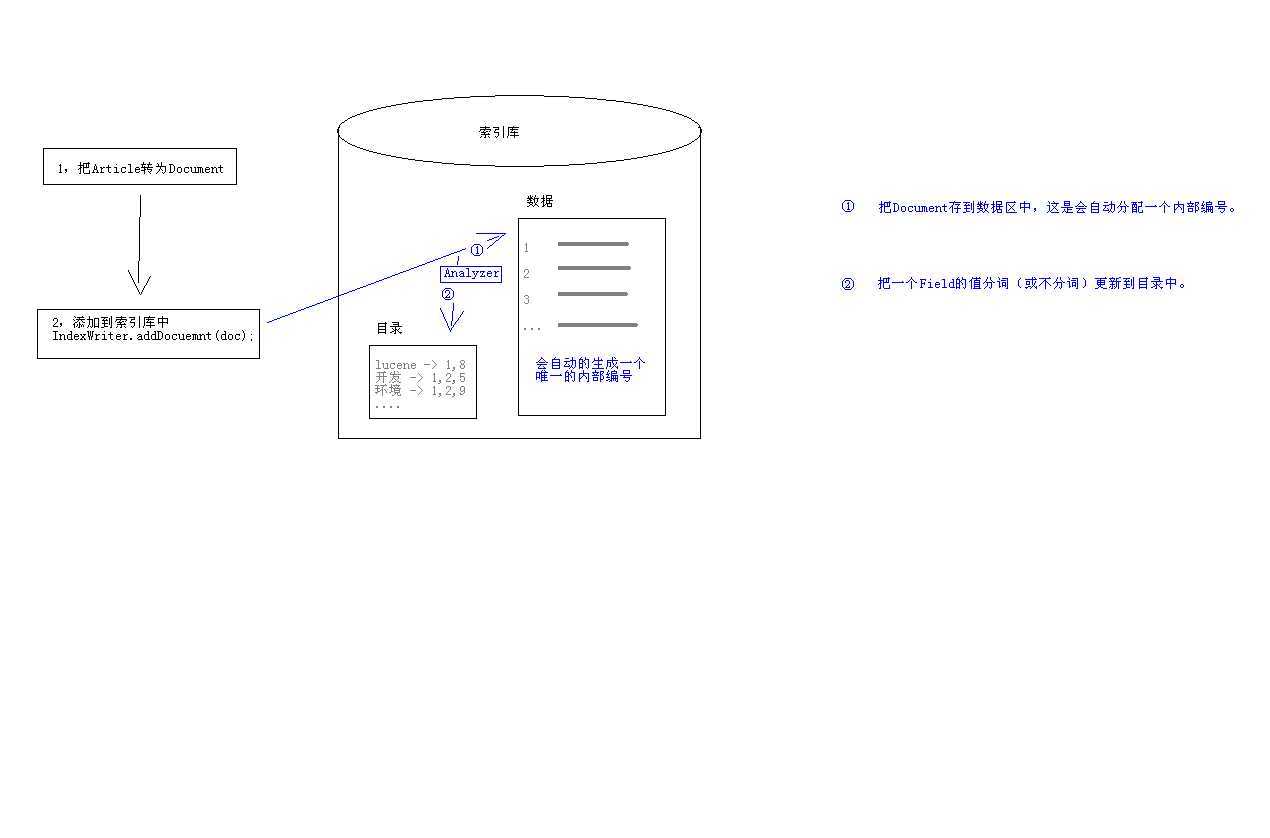
建立索引的执行过程
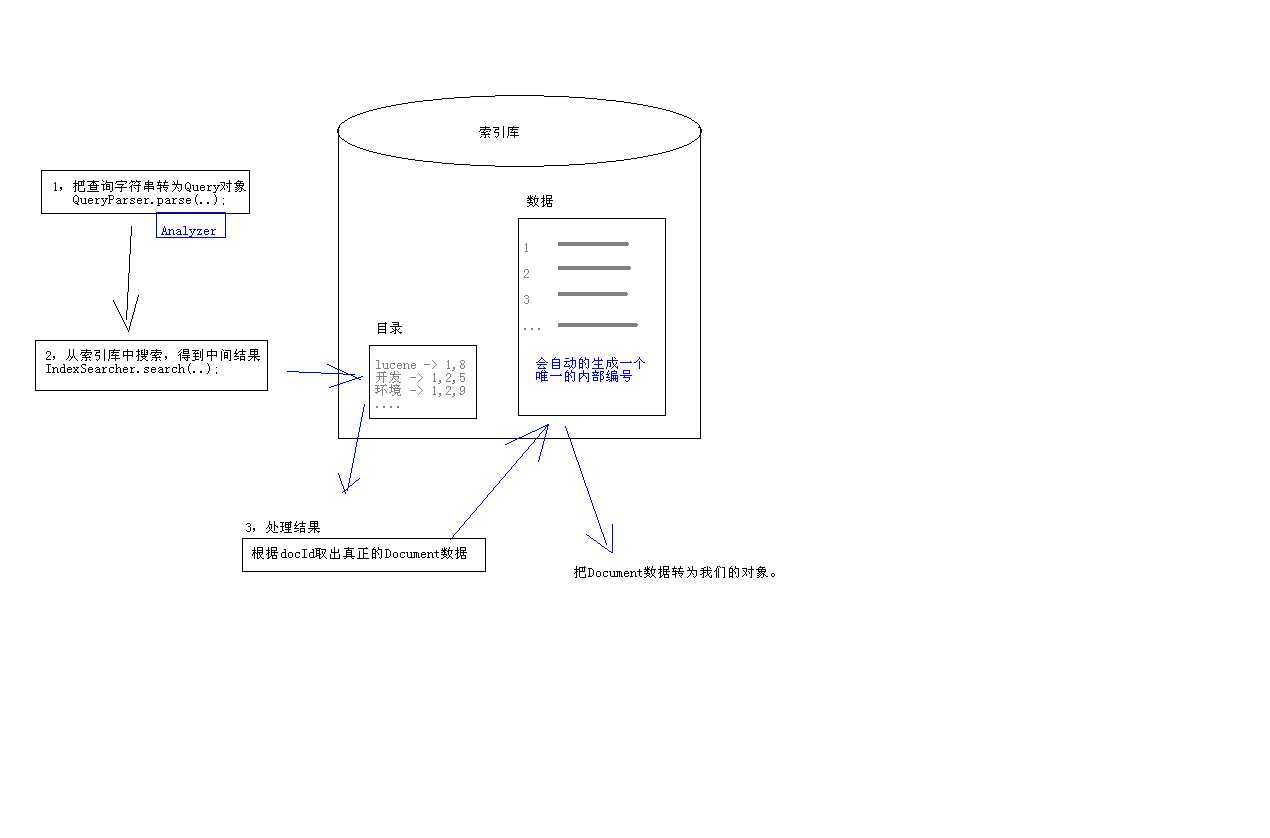
搜索的执行过程
分词器要保持一致
标签:Lucene style class blog code java
原文地址:http://www.cnblogs.com/friends-wf/p/3794908.html
