标签:style class blog code http color
使用MATLAB尝试了随机梯度下降的矩阵分解方法,实现了一个比较简单的推荐系统的原理。
常用推荐系统的方法有协同过滤, 基于物品内容过滤等等。
这次是用的矩阵分解模型属于协同过滤的一种方法,大致原理是通过一定数量的因子来描述各个用户的喜好和各个物品的属性。
通过随机梯度下降法分解后得到两个矩阵,一个是用户因子矩阵,另一个是物品因子矩阵。
这两个矩阵相乘可以得到所有用户对所有电影的预测评分。
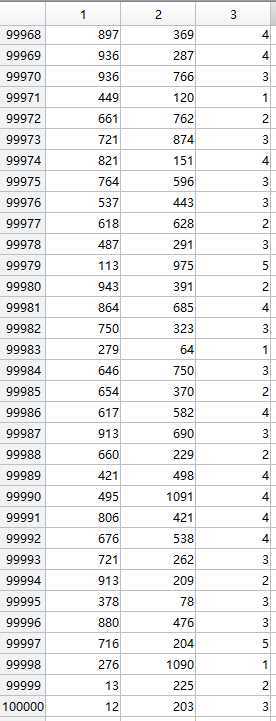
以Movie-Lens数据集举例,这包含943个用户对1682部电影的十万条评分。
第一列用户编号,第二列电影编号,第三列用户对该物品的评分(1-5分);
Matlab代码:
function [ Grade,userCal,itemCal,deviation ] = iterator( GradeData ,iteraTime ) % 利用随机梯度下降法分解稀疏的用户评分矩阵,得到用户因子矩阵和物品因子矩阵,因子项数30; % iteraTime : 迭代次数,建议值:30 alpha = 0.01; lambda = 10; userCal = rand(943,30); itemCal = rand(1682,30); range = size(GradeData,1); userCal_last = userCal; itemCal_last = itemCal; for limit = 1:1:iteraTime for i = 1:1:range tempUser = GradeData(i,1); tempItem = GradeData(i,2); tempGrade = GradeData(i,3); E = tempGrade - userCal(tempUser,:) * itemCal(tempItem,:)‘; userCal(tempUser,:) = userCal_last(tempUser,:) + alpha * ( E * itemCal_last(tempItem,:) - lambda * userCal_last(tempUser,:) ); itemCal(tempItem,:) = itemCal_last(tempItem,:) + alpha * ( E * userCal_last(tempUser,:) - lambda * itemCal_last(tempItem,:) ); end userCal_last = userCal; itemCal_last = itemCal; alpha = alpha / (1 + limit); end deviation= Deviation(GradeData ,lambda , userCal, itemCal); realGrade = pack(GradeData); Grade = userCal * itemCal‘ - realGrade; end function [ deviation ] = Deviation( GradeData , lambda ,user , item ) %计算平方误差,误差越小,拟合效果越好 range = size(GradeData(:,1)); deviation = 0; for i = 1:1:range tempUser = GradeData(i,1); tempItem = GradeData(i,2); tempGrade = GradeData(i,3); deviation = deviation + ( tempGrade - user(tempUser,:) * item(tempItem,:)‘ )^2 + lambda * ( sum(user(tempUser,:).^2 ) + sum(item(tempItem,:).^2) ) ; end end function [realGrade] = pack(GradeData) % realGrade = []; range = size(GradeData,1); for i =1:1:range realGrade(GradeData(i,1),GradeData(i,2)) = GradeData(i,3); end end
设置了30个因子项,这个可以根据实际情况调整。
迭代次数可以根据每一次迭代的deviation与上一次的deviation比较来判定是否收敛。
代码中直接迭代了20次,可以算出一个比较好的结果。
这样用户因子矩阵为943*30,物品因子矩阵为,1682*30;
分解后得到这两个矩阵:
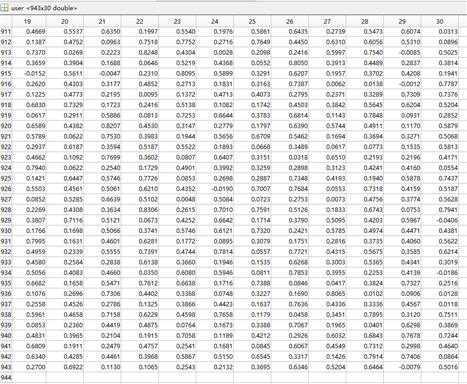
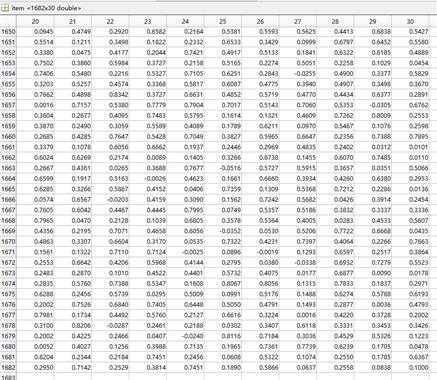
将用户因子矩阵(943*30)与物品因子矩阵(1682*30)的转置相乘即可得到评分预测矩阵(943*1682):
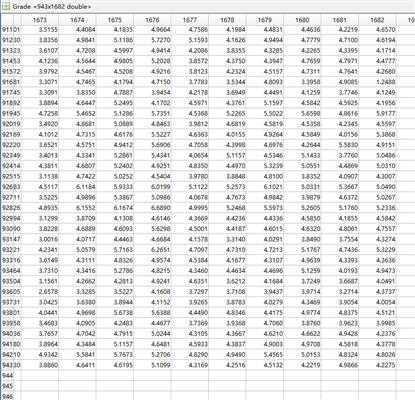
根据评分预测矩阵,就可以对用户进行相关推荐了。
基于随机梯度下降法的推荐系统虽然是基于内容推荐,但是系统设计者无需清楚每一个物品的内容属性和每一个用户的喜好,通过矩阵分解法得出的因子矩阵可以很好的描述用户和物品的属性,当然,这来自于用户的历史行为,用户过去的行为越多,则推荐越准确。比较流行的矩阵分解法还有SVD分解法等。
因为是协同过滤的方法,所以也存在着冷启动的问题,比如一个新物品,未和任何用户产生交互,则它永远不会被推荐,而新注册的用户也因为没有历史行为而无法对其推荐。其次,还有稀疏性问题,当系统中 用户与物品的交互过少时,推荐结果往往不会太准确。
标签:style class blog code http color
原文地址:http://www.cnblogs.com/moranBlogs/p/3795392.html