标签:style blog http color 使用 strong
现有的hadoop生态系统中存在的问题
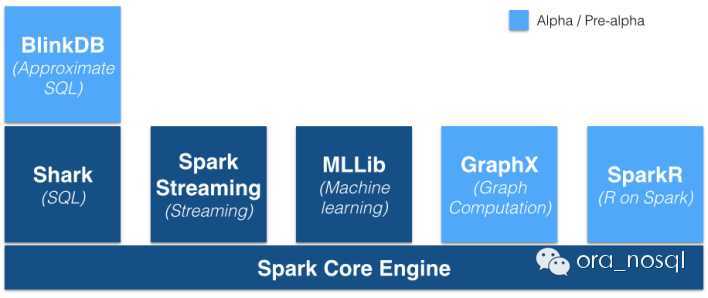
为什么要使用Spark?,布布扣,bubuko.com
为什么要使用Spark?
原文地址:http://www.cnblogs.com/luogankun/p/3798405.html