标签:des style class blog code http
By语句
By语句用于规定分组变量,控制set,merge,update或modify语句
官方说明:
BY<DESCENDING> variable-1<...<DESCENDING>variable-n> <NOTSORTED> ;
specifies the variable that the procedure uses to form BY groups. You can specify more than one variable. By default, the procedure expects observations in the data set to be sorted in ascending order by all the variables that you specify or to be indexed appropriately.
简单意思为:默认为升序,可以声明多个变量
声明为降序:by descending var1 descending var2;每个变量前面都要写上descending.
NOTSORTED:specifies that observations with the same BY value are grouped together, but are not necessarily sorted in alphabetical or numeric order. The observations can be grouped in another way (for example, in chronological order).
声明所有by组的观测在一起,但是没有被排序,如果前面用到了descending,则会覆盖掉,使其无用
data me;
set sashelp.class;
run;
/*排序后me的内容会发生变化*/
proc sort data=work.me; by sex age; run;
/*排序后的变量才能使用by,没排序的变量如果放在排序变量前会出现错误,放在后面没事儿,这里是产生first和last观测值的步骤*/
/*意义在于寻找by组内的第一个和最后一个观测值*/ data fst_lst; set me; by sex age ; fisrt_a = first.age; last_a = last.age; fisrt_n = first.sex; last_n = last.sex; run;
/*复制到sas中会飘红,是格式问题,删除前面的空格即可*/
data fst_data last_data;
set me;
by sex age;
if first.sex then output fst_data;
if last.sex then output lst_data;
run;
MERGE语句
实现表的横向合并,在表的一对一,多对一,一对多的合并上面来说和sql的功能基本一样,在表的多对多合并上面还是需要用到sql
MERGE SAS-data-set-1 <(data-set-options)>
SAS-data-set-2 <(data-set-options) >
<...SAS-data-set-n<(data-set-options)>>
<END=variable>;
选项的含义,看上篇的set语句,在所有选项中IN=选项的使用频率最高
一对一merge
libname chapt3 ‘E:\sas-data\Book_data\Book_data\chapt3‘; /*横向合并,两个数据集一行一行同时读取,后面的数据集如果和前面的变量有相同的则会覆盖,merge观测值取观测值最大的数据集的观测值*/
data me_merge; merge chapt3.merge_a chapt3.merge_b; run;
/*先后读取两个数据集,纵向合并*/ data me_set; set chapt3.merge_a chapt3.merge_b; run;
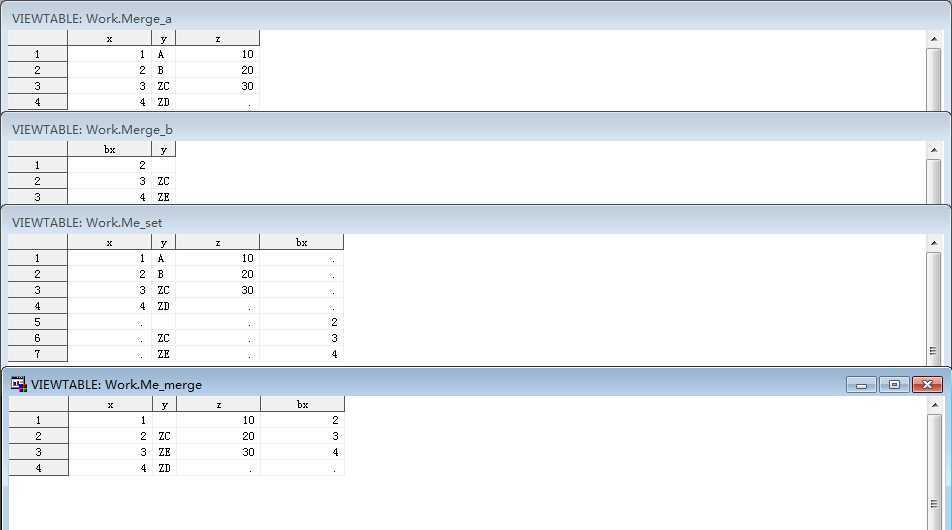
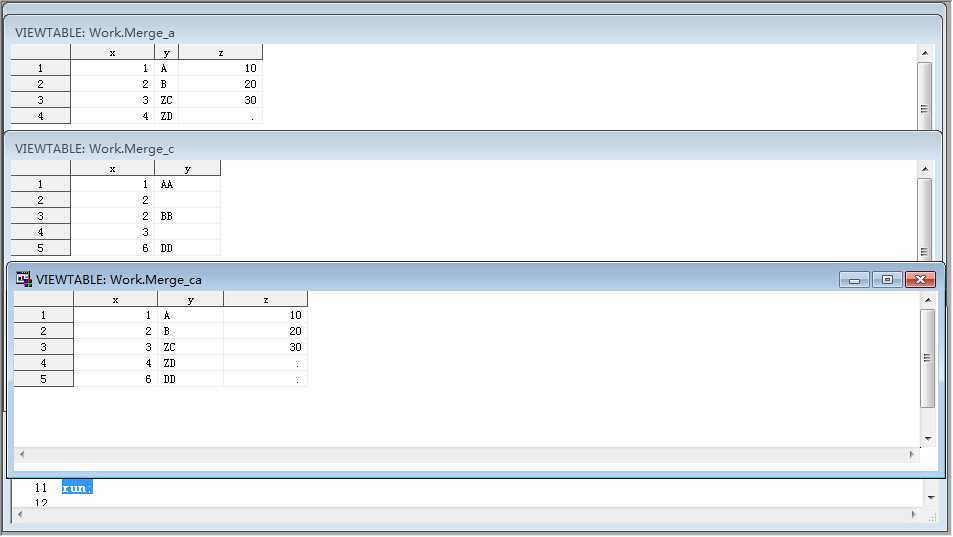
*一对多更新,会更新后面的多个,对于不相同的变量直接按顺序排列,例如z;
data merge_ac;
merge chapt3.merge_a chapt3.merge_c;
/* by x;*/
run;
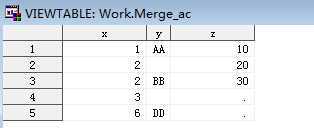
*多对一更新只更新第一个,对于不相同的变量直接按顺序排列;
data merge_ca; merge chapt3.merge_c chapt3.merge_a; /* by x;*/ run;
标签:des style class blog code http
原文地址:http://www.cnblogs.com/yican/p/3799318.html