标签:松本行弘的程序世界

半个月之前买了这本书,还是经园子里的一位网友推荐的。到现在看了一半多,基础的都看完了,剩下的几章可做高级部分来看。这本书看到现在,可以说感触很深,必须做一次读书笔记!
关于这本书,不了解的可以去网上查查。作者是Ruby语言的创始人,可谓是程序世界中的高手,开卷有益,不管你是哪个层次的编程人员,相信都能或多或少的汲取到你想要的营养。
下面将总结一下看完本书我记录下的一些知识点。有的是书中的原话,有的是我个人的理解,供参考。
2.1 多态性
面向对象三大原则:继承、封装和多态,其中最重要的技术是“多态性”,多态往往会用继承来表现,而封装又保证多态的独立性。多态性可以让程序只关注做什么,而不是关注怎么做。根据情况的不同,自动选择最合适的方法来处理。多态也是程序扩展性的基础。
2.2 历史
面向对象语言从60年代的Simula,到70、80年代的SmallTalk,直到后来的C++和java,java是最成功、应用最普遍的面向对象语言。本人用C#,和java差不多。UML是描述面向对象方法设计模型的图示方法(不会UML的抓紧补补吧,这也算是基础了)。
2.3 结构化编程
在很久很久以前,一些比较低级语言,是通过goto语句来执行代码的。C语言中有goto语句,一开始学的时候老师就不让用。goto语句是在出现if...else...(条件判断)和for、while等循环结构之前,人们用来控制程序的方法。大家试想,如果不让你用if..else..和for循环,通篇都是goto,那将会是什么结果??所以,用【顺序】、【条件】和【迭代】来代替goto语句,是程序开发的一大变革。
另外提一句,如果你从事.net开发,你可能有幸解除到goto语句——IL中间语言,IL相当于.net中的汇编预研。将一个简单的 if..else...编译成IL之后,结果如下:
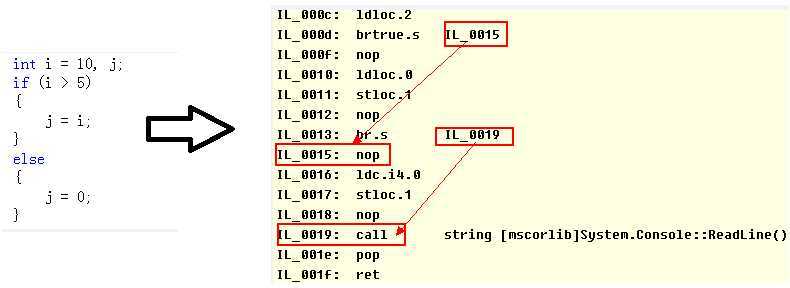
2.4 数据抽象化
前面讲到程序结构从goto语句中解放出来,那么程序所操作的数据结构呢?也需要有一种抽象的表达方式,而不是计算式世界所能理解的二进制代码。最常见是我们常用的数组、链表、字典等结构。其实,严格来说,程序中的整数、浮点数、各国的语言文字,都是数据抽象的结果。因为计算机只认识二进制字符串。
2.5 多重继承
如果你是一名java、C#开发人员,你用不到多继承,因为他们根本就不提供。但是有些语言是支持多继承的,C++、python。现实世界中需要多继承,例如以为程序员同时也可能是一位作家,一个部门经理同事也可能是一位父亲。但是多继承如果开放到程序中,就会带来许多问题。允许一个类有多个父类,复杂度可想而知,因此java禁止使用。但是它用什么来弥补这一缺失——接口interface。
至此,大家要了解接口是因为什么才来到这个世界——因为弥补进制使用多继承而带来的问题。但是接口真的能很好的解决这个问题吗?不见得。因为接口毕竟不能像父类那样使用。
Ruby中没有接口(不是所有面向对象语言都有接口的),它通过引用程序块的方式来实现多继承。我没有深入了解Ruby的这块功能,有兴趣的朋友可以研究。
2.6 面向对象是现实世界中具体事物的反映吗?
作者认为,对“面向对象”最好的解释是“对数据的结构化”。前文讲到结构化编程是将程序流程分为顺序、条件和循环三种结构,而面向对象则是在此基础上的延伸,它将程序处理的数据进行了结构化。通过对象来组织数据,数据就成为一个整体,而不再松散。
这是面向对象最根本的意义,如果理解这一点,那么是否反映现实世界就不重要了。其实像数组、字符串,你也找不出现实世界的什么东西与之对应。
程序是处理抽象数据的。无论以后学习什么技术,都不要满足于小猫小狗之类的例子。
另外,关于“继承”,也不要看成是现实世界的真实反映,它就是一些抽象、公用功能的重用方法,这样反而更好理解。
2.7 静态语言 VS 动态语言
这里所谓的静态和动态,指的是数据类型的强弱。例如C#、java就是强类型,js、Ruby就是弱类型。强类型中,每个变量都有明确的数据类型,不能更改,也不能赋其他类型的值,要不然会报错。而在若类型中,变量的类型是随着其存储值动态改变的。
两者各有好坏。强类型可以在编译时识别类型错误,程序执行的速度会更快,但是不灵活。弱类型灵活,但是有些潜在的错误不容易发现。
我恰巧C#和js都用,在我看来,这两种方式都可以,只要你认真对待,哪个都不会出现大问题。所以了解即可,不必太纠结到底哪个好。
3.1 闭包
“闭包”这个词,我是在js中第一次接触的。不过看来业界通用这个词汇,大体意思就是应用外部的变量和环境,和js中一样。作者提到Ruby中可以通过传递程序块的方式实现闭包,我没有仔细去看细节。不过读到这里,我想起了以下几点:
01. jQuery源码中用到了大量的闭包,了解到js中的闭包会影响到性能和内存。所以,我以后将会非常注意jQuery中闭包的使用,真正深入了解闭包;
02. C语言的函数指针是闭包吗?
03. C#和java中,哪些用到了闭包?
以后再遇到这种问题、知识点,将关注以下。
3.2 for循环
Ruby中实现for循环的方式是 obj.each(....) 这种方式,和jquery的each循环类似。作者在本章节的后面提到“不用for语句”,因为for语句会破坏对象的封装性。其实这一点在设计模式中也有专门的解决方案——迭代器模式。
首先,书中没有一个一个挨着讲每个设计模式。有兴趣可以看看我写的关于设计模式的博客:
大家最好要知道,“设计模式”一词来源于建筑业(曾经是我比较向往的专业,呵呵)。大家常说的设计模式,一般是指《设计模式.可复用软件的基础》一书中提到的二十三中设计模式,作者们是GoF。其实这些设计模式并不是作者们创新出来的,而是他们总结当时日常设计工作中,最常用的23中模式,给他们分组、取名,最后成就了一部伟大的作品。所以,GoF做出的贡献就是将原本没有名字的东西,给他们起名字,并让他们成为结构化的知识。这是件很了不起的事,例如美国PMI将日常项目管理工作总结为10大知识领域5大过程组一样。
4.1 设计模式和类库
类库是把常用的算法、接口封装起来,供系统其他模块使用,或者供其他系统使用,它可以“0成本”重用的。但设计模式的重用,却不是“0成本”,它是一个很抽象的东西,你要根据实际情况来具体确定。
4.2 开放-封闭 原则(简称:OCP)
业界有5大设计原则,其中最重要的就是“开放-封闭原则”——即对扩展开放、对修改封闭。了解设计原则可以查阅:换种思路去理解设计模式(上)
这里所谓的“对扩展开放”,在面向对象编程中是通过继承和多态来实现的,继承允许功能的添加,多态保证接口的稳定性。从实用主义的观点来看,面向对象的精髓就在于对OCP的实践。至于把对象看做物体理解起来比较容易,能够建立现实世界的模型等,只不过是一些锦上添花的东西。
一个优秀的设计模式,肯定能经得住OCP的考验!
ajax是web开发中比较基础的东西,基本概念此处不再赘述。
5.1 Ajax中的“x”
“x”指的是“XML”。因为在ajax刚开始用的时候,都是用xml格式来传递数据,因此xml也被说成是ajax的基本部分之一。但是现在随着json越来越流行,xml的用武之地越来越少,高版本的浏览器直接支持JSON转换接口。
所以,此处了解即可。开发时该用什么用什么。
5.2 javascript——基于对象的语言
可能你会经常听到:js是以对象为基础的语言,所有的数据都是对象,js是基于原型的语言。对,js中没有“类”的概念,除了基本的值类型之外,其他的数据都以对象来处理,都可以自定义添加属性,包括函数。js是通过原型来实现所谓的继承的。
另外,js中的闭包是比较出名的,闭包在js中的应用很多,jQuery源码中大量使用闭包就是个例证。
这两个问题,不是一两句话能说明白的,说实话我现在感觉自己知道一些,但是了解的不是很透彻。不过正在努力的补充。要想把js的“对象”和“闭包”讲明白,我想还需要从其他方面下手,将会是一个比较系统的工程。后期我定会搞定它们,并以某种方式讲出来。此处点到为止。
6.1 MVC
感觉作者本文中只是讲述了MVC这个理念,并用小例子解释。由于我没有真正参与过MVC的项目,也只是日常的了解,所以对这块感触不是很深。
6.2 猴子补丁
所谓的“猴子补丁”,其实就是C#中的部分类和扩展方法。在不改变原来代码结构的基础上,添加新代码。个人不建议这种做法,如果重复这样做,将会导致代码松散难以维护。
-----------------------------------------------------------------------------
推荐一下我录制的《asp.net petshop4.0源码解读》教程,免费学习!
-----------------------------------------------------------------------------
7.1 理解编码
计算机只能处理二进制数据,从计算机被发明出来它是这样,到现在还是这样。那么我们要让这个只能识别“010101...”二进制的家伙去处理文字,该怎么办呢?——把文字表示成二进制。大家可以查看unicode(下文将介绍unicode)编码表,看看其中中文编码那一块,比如,16进制的4e07表示“万”字:

说到这里让我想起来,平时我们在新闻留言、QQ聊天或者发短信的时候,可以发一些表情—— ,大家可能都知道这些表情是用一些特殊的字符串规定好的。其实,这就是一个简单的表情编码,和计算机中文字编码成二进制一个道理。
,大家可能都知道这些表情是用一些特殊的字符串规定好的。其实,这就是一个简单的表情编码,和计算机中文字编码成二进制一个道理。
7.2 ASCII码
当初计算机是美国人发明的,最早也在美国被应用。美国人用英语,所谓的字符只有26个英文字母,大小写都算上,也不过52个,在算上键盘上那些乱七八糟的标点符号,最多100来个。于是他们发明了用7位二进制数构成的编码表——ASCII码。2的7次方=128。ASCII码可表示128个字符。计算机中8位二进制是一个字节,还能剩下一位,用于附加错误码(作者:不知错误码为何意??)

上图中,用二进制数“1000001”表示的是字母“A”,十进制是65,咱们学C语言的时候,估计都能背过——‘A‘转换成int是65,现在知道什么意思了吧。。。
下图是ASCII码对应的值(十进制表示):
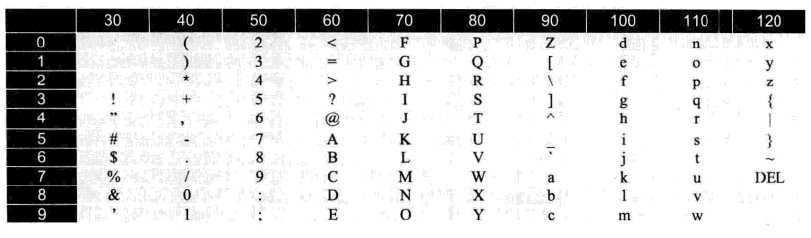
7.3 unicode字符集
世界上的文字有很多种,除了用A-Z表示的文字之外,还有许多欧洲、亚洲的文字是用其他图形表示的,比如咱们的中文(简体和繁体还不一样)。于是,ASCII码不能满足要求之后,有出现了很多种编码方式,例如中国的GB2312字符集。不过现在业界越来越统一到unicode字符集中。所以,就简单介绍unicode字符集。
ASCII码用7位二进制,可表示128个字符,而最初的unicode字符集用16位二进制表示,2的16次方=65536,可表示6万多个字符。unicode字符集最初的设计者预计6W多个字符足以表示世界上所有语言文字了,可惜他们错了。后来unicode字符集又扩充到了21位。
从网上可以查到所有unicode编码表的内容,以下是截取的一个片段。例如,汉字“万”的编码是16进制数 4e07:
7.4 unicode的字符编码方式
虽然unicode字符集将世界上的文字字符全部统一了编码,但是这个编码的存储方式,却又分为好几种,例如大家常见的UTF-8、UTF-16、UTF-32。
例如,汉字“万”的编码值是16进制数 4e07 ,但是通过UTF-8计算出的存储结构和UTF-16是不一样的。所以,如果用UTF-16的方式去解析UTF-8编码的数据,可能会出现乱码。
至于每种编码方式是怎样的,这里就不再详细介绍了。其实书中也只是讲了一点皮毛。大家了解即可。
我接触正则表达式是在学习js中接触的,js应用正则表达式比较简单,但是正则表达式本身的语法却很复杂。
后来看jQuery源码,被sizzle这块的正则表达式给完全搞晕了,到现在都没梳理好。
书中介绍的无非就是正则表达式的若干语法,以及Ruby如何支持。
其实学习正则表达式不用看这个,推荐一个:正则表达式30分钟入门教程(提醒:说30分钟是忽悠你,用俩小时全部看完并理解,就不错了!)
整数和浮点小数,是程序开发中最常用的类型之一。如果你觉得程序对数字的操作非常简单,无非就是加减乘除,那么请你耐心看完下面的文字。
9.1 整数是有范围的
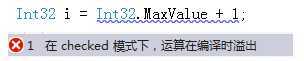
在C、C++、C#等静态类型的语言中,int一般表示32位整数,也就是用32个二进制数表示一个整数,除去一个符号位,int所能表现的最大整数是有限的。
C#中,int32 和 int64 分别表示不同位数的整数,都有最大值和最小值的标志:

如果程序中的数字,超过了最大值,无法通过编译,提示溢出。同理,如果运行时出现了这样的情况,也会抛出异常。
另外,不光整数有范围。浮点小数也有范围大小,原理一样。
不过浮点小数还有其他要说的内容,下文介绍。
9.2 为何Ruby中的整数没有范围
任何语言都无法从根本上行使整数没有范围。Ruby是动态类型的语言,当他遇到数字超过单个整数范围时,它会把这个数分多个整数存储。不过这一切都是Ruby自动帮你完成的,所以在你看来,你认为Ruby的整数大小是无限制的。
这是一种技巧,类似于数据库的分表存储。
9.3 浮点小数的误差
其实我从很早以前就注意到,javascript中:0.1 + 0.2 = 0.30000000000000004 ,当时只是单纯的认为js对小数的计算有误差,以后得注意。但是看完书中本章节,发现不对。不光js,所以语言都会有误差。以C#为例:
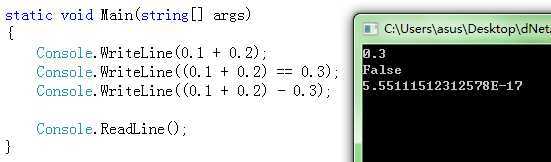
大家可以从上图中很清楚的看到答案。程序第一行,虽然C#输出的是 0.1 + 0.2 = 0.3 ,但是从下面的程序可以看出,这里的0.3只不过是个近似值。
针对浮点小数的这些计算的误差,各个程序也都给出了他们认为的可控制的范围。例如,C#的single类型(即float类型)中,允许误差的可控范围如下图:
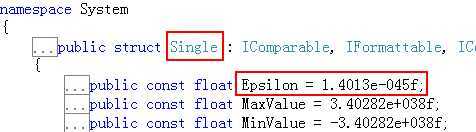
意思就是说,只要在这个范围之内,就不认为有误差。但是很遗憾,我还没有用到过这个属性。。。先了解一下吧。
9.4 计算机如何处理小数
上文说了半天的误差,下面解释计算机中为何对小数处理会产生误差。原因还是一句话:计算机只能处理二进制。
所有的整数,都可以用二进制无误差的表示出来,例如:65 --> 1000001,10 --> 1010 ,但是小数呢? 有的小数无法用二进制表示。
例如,十进制的0.5表示为二进制是 0.1, 但是十进制的0.2表示为二进制会出现一个无限循环的小数:0.001100110011....
这是计算机无法完全处理小数的根本!
对于计算机处理浮点数的现状,暂时是无法改变的。它会带来一些误差,某些时候可能会因为一些不当的操作或者数据量的增加,而导致误差过大,但是这也只能通过我们的算法和设计来减轻。
最后,小数在内存中肯定不是以“0.25”这样带小数点的形式表示的,因为它必须转换成为二进制。书中提到了表示浮点数的IEEE745标准,也简单介绍了如何将一个浮点小数表示为二进制串,但这不是我学习的重点。因为对于这一点,先了解就好,有必要时再去深入研究。
-----------------------------------------------------------------------------------------
顺便,推荐一下我录制的《asp.net petshop4.0源码解读》教程,免费学习!
-----------------------------------------------------------------------------------------
前文提到的文字编码和数字,让我想起了一个词——数据抽象化。
计算机本来只能识别二进制码,通过这些年来的演变,使得它可以很友好的处理我们的语言和数学知识,这怎能不叫数据抽象呢。
再说个详细的例子,我们现在能通过打印机几秒钟打印一页文字,并轻松阅读,但是一开始要阅读计算机的语言,是打印纸带,再翻译纸带。大家可以试着通过ASCII码翻译一下这几个字母:

《松本行弘的程序世界》读书笔记,布布扣,bubuko.com
标签:松本行弘的程序世界
原文地址:http://blog.csdn.net/wangfupeng1988/article/details/32098999