背景:
有些分布式服务(比如HBase服务), 依赖于系统时间戳, 如果集群各个节点, 系统时间不一致, 导致服务出现诡异的情况.
解决方案:
那如何同步集群各个节点之间的时间?
采用NTP(Network Time Protocol)方式来实现, 选择一台机器, 作为集群的时间同步服务器, 然后分别配置服务端和集群其他机器
1.NTP服务端
*) 安装ntp服务
yum install ntp
*) 配置/etc/ntp.conf
这边采用本地机器作为时间的原点
注释server列表
#server 0.centos.pool.ntp.org
#server 1.centos.pool.ntp.org
#server 2.centos.pool.ntp.org
添加
server 127.127.1.0 prefer
fudge 127.127.1.0 stratum 8
*) 启动ntpd服务
/etc/init.d/ntpd restart
2. NTP客户端
*) 安装ntp
yum install ntpdate
*) 主动同步
ntpdate <server_ip>
可配置crontab命令
crontab -e
0-59/10 * * * * /usr/sbin/ntpdate <server_ip> && hwclock -w
# 每10分钟, 客户端机器, 主动进行时间同步
# 注意: 配置的crontab命令, 需要指定绝对路径, 没有crontab运行的命令, 没有登录会话的概念, 也就不会有/etc/profile, ~/.bashrc的载入初始化工作.
问题汇总:
1. 为何是127.127.1.0, 而不是其他保留的loopback地址?
在ntp服务中, 127.127.x.0有特殊的含义, 而x代表时钟数据源
2. 客户端时间同步失败
客户端机器, 执行 ntpdate <server_ip> 时, 报如下错误
no server suitable for synchronization found
采用ntpdate -d <server_ip> 查看具体的详细信息
172.16.1.106: Server dropped: strata too high server 172.16.1.106, port 123 stratum 16, precision -23, leap 11, trust 000
stratum 16表示, 服务端并未正常工作, 可能服务端的ntpd没有和其的时间源同步, 或者重启还未生效
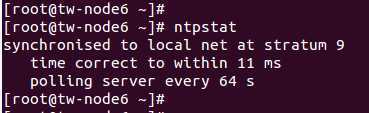
ntpd重启后, 并非立即生效, 需要等待一段时间
可通过 ntpstat 命令来进行查看
http://blog.csdn.net/weidan1121/article/details/3953021
3. /etc/ntp.conf具体参数含义
参考链接:
http://blog.sina.com.cn/s/blog_5369bee10100aysx.html
shell 脚本实战笔记(3)--集群机器的时间同步设置,布布扣,bubuko.com
原文地址:http://www.cnblogs.com/mumuxinfei/p/3804363.html