标签:style blog http color com width
请注意:csdn那边的博客http://blog.csdn.net/my_share。因为那边审核的时间太长。搬迁入这里。stanford机器学习前2堂在CSDN的博客里面。
刚开始他写了,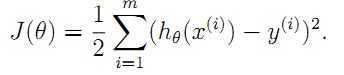 这个公式第二堂讲的,是梯度下降法,预测房价的那个。
这个公式第二堂讲的,是梯度下降法,预测房价的那个。
第二堂讲的线性回归,我们假设的房价的预测可以用线性方程来拟合。那只是一个假设量。其实可以用多次函数拟合。按照视频的说法就是,如果你只有7个样本,你就可以用一个6次函数完成拟合。这个结论可以记住,其实我csdn里面关于神经网络中隐层数量设计的时候,也涉及到这一点。具体原因我不是很明白,可是这个现象理解。
如果完全拟合的话,并不能说明你拟合的很好,也有可能是你的数据样本采集的不正确。
过拟合就是说,仅仅是拟合了某种特定状况的行为特征。而没有反应出房价和面积的真正规律。
locally weighted linear regression
局部加权线性回归。从表面上看局部加权线性回归还是线性回归,所以基本结构还是一样的。不过区别在于,
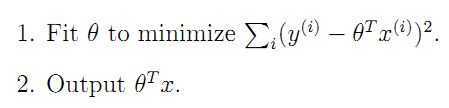 这个是上一堂线性回归的要求。
这个是上一堂线性回归的要求。
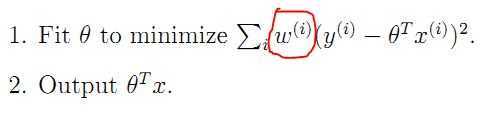 这个是加权线性回归。多了一个w是权系数。而这个w呢??
这个是加权线性回归。多了一个w是权系数。而这个w呢??
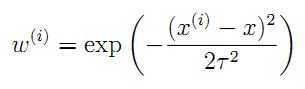 这里这个T呢。叫带宽系数,是我们自己设定的。和a学习系数的性质差不多。从这个式子可以看出,其实是用周边的点,来拟合当前的点。离的远的贡献就低一些,也就是关联性不强。这样拟合的就准确一些。
这里这个T呢。叫带宽系数,是我们自己设定的。和a学习系数的性质差不多。从这个式子可以看出,其实是用周边的点,来拟合当前的点。离的远的贡献就低一些,也就是关联性不强。这样拟合的就准确一些。
按照老师的说法是,w的函数还在讨论中,仅仅是e指数比较合适。
这个函数每一次预测都需要重新局部训练,具体怎么回事??还是看视频吧。好像是每次都是局部拟合,而且线性。用周边的来预测。说明局部加权回归这里的i是当前附近的几个点,在训练的结果。而最终拟合成非线性函数。
好像这个是每一次预测都需要重新学习重新拟合,所以数据量大的时候,代价很大。
epsilon希腊字母,表示的是error,表示那些没有被表示出来的特征。被遗忘的参考因素等。
这里的误差模型为什么选用高斯分布,第一个它只是一个方便的讨论模型,第二个,目前最合适的。
...............未完待续。
我能力有限,但是我努力的将学习成果分享。到这里就是我今天所学到的新知识,一起学习一起努力吧。
FPGA机器学习之stanford机器学习第三堂1,布布扣,bubuko.com
标签:style blog http color com width
原文地址:http://www.cnblogs.com/maohuawang/p/3805209.html