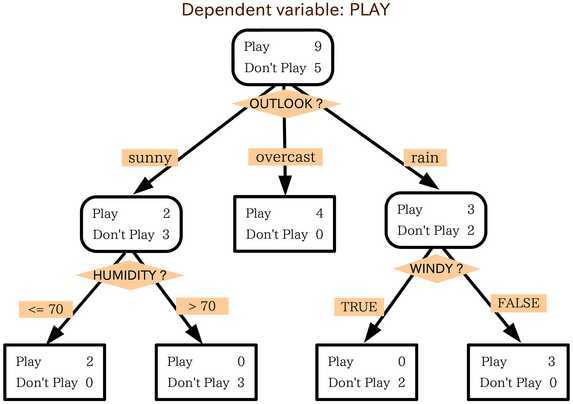
-------------------------------分割线------------------------------------------------
library(plyr)
# 测试数据集 http://archive.ics.uci.edu/ml/datasets/Car+Evaluation
##计算训练集合D的熵H(D)
##输入:trainData 训练集,类型为数据框
## nClass 指明训练集中第nClass列为分类结果
##输出:训练集的熵
cal_HD <- function(trainData, nClass){
if ( !(is.data.frame(trainData) & is.numeric(nClass)) )
"input error"
if (length(trainData) < nClass)
"nClass is larger than the length of trainData"
rownum <- nrow(trainData)
#对第nClass列的值统计频数
calss.freq <- count(trainData,nClass)
#计算每个取值的 概率*log2(概率)
calss.freq <- mutate(calss.freq, freq2 = (freq / rownum)*log2(freq / rownum))
-sum(calss.freq[,"freq2"])
#使用arrange代替order,方便的按照多列对数据框进行排序
#mtcars.new2 <- arrange(mtcars, cyl, vs, gear)
}
#cal_HD(mtcars,11)
##计算训练集合D对特征值A的条件熵H(D|A)
##输入:trainData 训练集,类型为数据框
## nClass 指明训练集中第nClass列为分类结果
## nA 指明trainData中条件A的列号
##输出:训练集trainData对特征A的条件熵
cal_HDA <- function(trainData, nClass, nA){
rownum <- nrow(trainData)
#对第nA列的特征A计算频数
nA.freq <- count(trainData,nA)
i <- 1
sub.hd <- c()
for (nA.value in nA.freq[,1]){
#取特征值A取值为na.value的子集
sub.trainData <- trainData[which(trainData[,nA] == nA.value),]
sub.hd[i] <- cal_HD(sub.trainData,nClass)
i <- i+1
}
nA.freq <- mutate(nA.freq, freq2 = (freq / rownum)*sub.hd)
sum(nA.freq[,"freq2"])
}
##计算训练集合D对特征值A的信息增益g(D,A)
##输入:trainData 训练集,类型为数据框
## nClass 指明训练集中第nClass列为分类结果
## nA 指明trainData中特征A的列号
##输出:训练集trainData对特征A的信息增益
g_DA <- function(trainData, nClass, nA){
cal_HD(trainData, nClass) - cal_HDA(trainData, nClass, nA)
}
##根据训练集合生成决策树
##输入:trainData 训练集,类型为数据框
## strRoot 指明根节点的属性名称
## strRootAttri 指明根节点的属性取值
## nClass 指明训练集中第nClass列为分类结果
## cAttri 向量,表示当前可用的特征集合,用列号表示
## e 如果特征的最大信息增益小于e,则剩余作为一个分类,类频数最高的最为分类结果
##输出:决策树T
gen_decision_tree <- function(trainData, strRoot, strRootAttri, nClass, cAttri, e){
# 树的描述,(上级节点名称、上级节点属性值、自己节点名称,自己节点的取值)
decision_tree <- data.frame()
nClass.freq <- count(trainData,nClass) ##类别出现的频数
nClass.freq <- arrange(nClass.freq, desc(freq)) ##按频数从低到高排列
col.name <- names(trainData) ##trainData的列名
##1、如果D中所有属于同一类Ck,则T为单节点树
if nrow(nClass.freq) == 1{
rbind(decision_tree, c(strRoot, strRootAttri, nClass.freq[1,1], ‘‘))
return decision_tree
}
##2、如果属性cAttri为空,将D中频数最高的类别返回
if length(cAttri) == 0{
rbind(decision_tree, c(strRoot, strRootAttri, nClass.freq[1,1], ‘‘))
return decision_tree
}
##3、计算cAttri中各特征值对D的信息增益,选择信息增益最大的特征值Ag及其信息增益
maxDA <- 0 #记录最大的信息增益
maxAttriName <- ‘‘ #记录最大信息增益对应的属性名称
maxAttriIndex <- ‘‘ #记录最大信息增益对应的属性列号
for(i in cAttri){
curDA <- g_DA(trainData,nClass,i)
if (maxDA <= curDA){
maxDA <- curDA
maxAttriName <- col.name[i]
}
}
##4、如果最大信息增益小于阈值e,将D中频数最高的类别返回
if (maxDA < e){
rbind(decision_tree, c(strRoot, strRootAttri, nClass.freq[1,1], ‘‘))
return decision_tree
}
##5、否则,对Ag的每一可能值ai,依Ag=ai将D分割为若干非空子集Di
## 将Di中实例数最大的类作为标记,构建子节点
## 由节点及其子节点构成树T,返回T
for (oneValue in unique(trainData[,maxAttriName])){
sub.train <- trainData[which(trainData[,maxAttriName] == oneValue),] #Di
#sub.trian.freq <- count(sub.train,nClass) ##类别出现的频数
#sub.trian.freq <- arrange(sub.trian.freq, desc(freq)) ##按频数从低到高排列
rbind(decision_tree, c(strRoot, strRootAttri, maxAttriName , oneValue))
##6、递归构建下一步
# 剔除已经使用的属性
next.cAttri <- cAttri[which(cAttri !=maxAttriIndex)]
# 递归调用
next.dt <-gen_decision_tree(sub.train, maxAttriName,
oneValue, nClass, next.cAttri, e)
rbind(decision_tree, next.dt)
}
names(decision_tree) <- c(‘preName‘,‘preValue‘,‘curName‘,‘curValue‘)
decision_tree
}