Spark计算速度远胜于Hadoop的原因之一就在于中间结果是缓存在内存而不是直接写入到disk,本文尝试分析Spark中存储子系统的构成,并以数据写入和数据读取为例,讲述清楚存储子系统中各部件的交互关系。
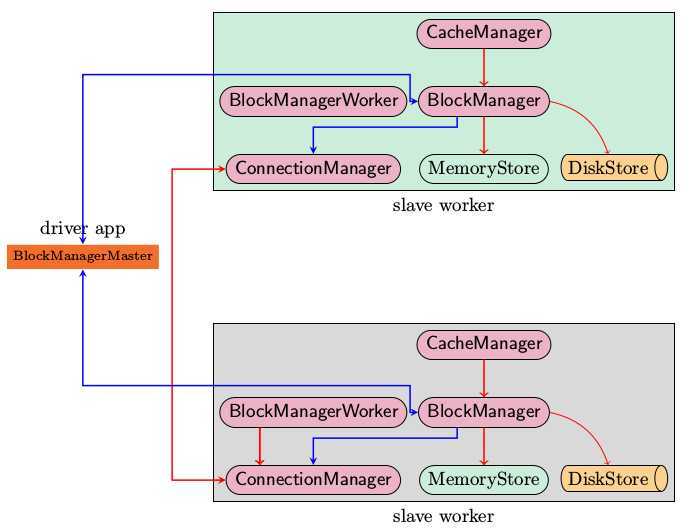
上图是Spark存储子系统中几个主要模块的关系示意图,现简要说明如下
由于BlockManager起到实际的存储管控作用,所以在讲支持的操作的时候,以BlockManager中的public api为例
上述的各个模块由SparkEnv来创建,创建过程在SparkEnv.create中完成
val blockManagerMaster = new BlockManagerMaster(registerOrLookup(
"BlockManagerMaster",
new BlockManagerMasterActor(isLocal, conf)), conf)
val blockManager = new BlockManager(executorId, actorSystem, blockManagerMaster, serializer, conf)
val connectionManager = blockManager.connectionManager
val broadcastManager = new BroadcastManager(isDriver, conf)
val cacheManager = new CacheManager(blockManager)
这段代码容易让人疑惑,看起来像是在所有的cluster node上都创建了BlockManagerMasterActor,其实不然,仔细看registerOrLookup函数的实现。如果当前节点是driver则创建这个actor,否则建立到driver的连接。
def registerOrLookup(name: String, newActor: => Actor): ActorRef = {
if (isDriver) {
logInfo("Registering " + name)
actorSystem.actorOf(Props(newActor), name = name)
} else {
val driverHost: String = conf.get("spark.driver.host", "localhost")
val driverPort: Int = conf.getInt("spark.driver.port", 7077)
Utils.checkHost(driverHost, "Expected hostname")
val url = s"akka.tcp://spark@$driverHost:$driverPort/user/$name"
val timeout = AkkaUtils.lookupTimeout(conf)
logInfo(s"Connecting to $name: $url")
Await.result(actorSystem.actorSelection(url).resolveOne(timeout), timeout)
}
}
初始化过程中一个主要的动作就是BlockManager需要向BlockManagerMaster发起注册
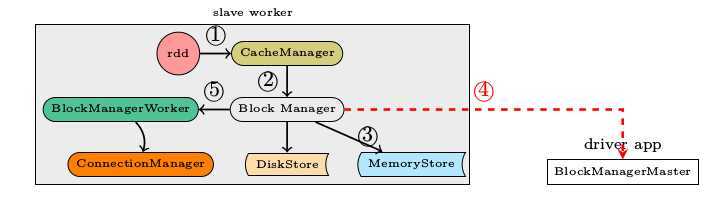
数据写入的简要流程
写入的具体内容可以是序列化之后的bytes也可以是没有序列化的value. 此处有一个对scala的语法中Either, Left, Right关键字的理解。
def get(blockId: BlockId): Option[Iterator[Any]] = {
val local = getLocal(blockId)
if (local.isDefined) {
logInfo("Found block %s locally".format(blockId))
return local
}
val remote = getRemote(blockId)
if (remote.isDefined) {
logInfo("Found block %s remotely".format(blockId))
return remote
}
None
}
首先在查询本机的MemoryStore和DiskStore中是否有所需要的block数据存在,如果没有则发起远程数据获取。
远程获取调用路径, getRemote->doGetRemote, 在doGetRemote中最主要的就是调用BlockManagerWorker.syncGetBlock来从远程获得数据
def syncGetBlock(msg: GetBlock, toConnManagerId: ConnectionManagerId): ByteBuffer = {
val blockManager = blockManagerWorker.blockManager
val connectionManager = blockManager.connectionManager
val blockMessage = BlockMessage.fromGetBlock(msg)
val blockMessageArray = new BlockMessageArray(blockMessage)
val responseMessage = connectionManager.sendMessageReliablySync(
toConnManagerId, blockMessageArray.toBufferMessage)
responseMessage match {
case Some(message) => {
val bufferMessage = message.asInstanceOf[BufferMessage]
logDebug("Response message received " + bufferMessage)
BlockMessageArray.fromBufferMessage(bufferMessage).foreach(blockMessage => {
logDebug("Found " + blockMessage)
return blockMessage.getData
})
}
case None => logDebug("No response message received")
}
null
}
上述这段代码中最有意思的莫过于sendMessageReliablySync,远程数据读取毫无疑问是一个异步i/o操作,这里的代码怎么写起来就像是在进行同步的操作一样呢。也就是说如何知道对方发送回来响应的呢?
别急,继续去看看sendMessageReliablySync的定义
def sendMessageReliably(connectionManagerId: ConnectionManagerId, message: Message)
: Future[Option[Message]] = {
val promise = Promise[Option[Message]]
val status = new MessageStatus(
message, connectionManagerId, s => promise.success(s.ackMessage))
messageStatuses.synchronized {
messageStatuses += ((message.id, status))
}
sendMessage(connectionManagerId, message)
promise.future
}
要是我说秘密在这里,你肯定会说我在扯淡,但确实在此处。注意到关键字Promise和Future没。
如果这个future执行完毕,返回s.ackMessage。我们再看看这个ackMessage是在什么地方被写入的呢。看一看ConnectionManager.handleMessage中的代码片段
case bufferMessage: BufferMessage => {
if (authEnabled) {
val res = handleAuthentication(connection, bufferMessage)
if (res == true) {
// message was security negotiation so skip the rest
logDebug("After handleAuth result was true, returning")
return
}
}
if (bufferMessage.hasAckId) {
val sentMessageStatus = messageStatuses.synchronized {
messageStatuses.get(bufferMessage.ackId) match {
case Some(status) => {
messageStatuses -= bufferMessage.ackId
status
}
case None => {
throw new Exception("Could not find reference for received ack message " +
message.id)
null
}
}
}
sentMessageStatus.synchronized {
sentMessageStatus.ackMessage = Some(message)
sentMessageStatus.attempted = true
sentMessageStatus.acked = true
sentMessageStaus.markDone()
}
注意,此处的所调用的sentMessageStatus.markDone就会调用在sendMessageReliablySync中定义的promise.Success. 不妨看看MessageStatus的定义。
class MessageStatus(
val message: Message,
val connectionManagerId: ConnectionManagerId,
completionHandler: MessageStatus => Unit) {
var ackMessage: Option[Message] = None
var attempted = false
var acked = false
def markDone() { completionHandler(this) }
}
我想至此调用关系搞清楚了,scala中的Future和Promise理解起来还有有点费劲。
在Spark的最新源码中,Storage子系统引入了TachyonStore. TachyonStore是在内存中实现了hdfs文件系统的接口,主要目的就是尽可能的利用内存来作为数据持久层,避免过多的磁盘读写操作。
有关该模块的功能介绍,可以参考http://www.meetup.com/spark-users/events/117307472/
一点点疑问,目前在Spark的存储子系统中,通信模块里传递的数据即有“心跳检测消息”,“数据同步的消息”又有“数据获取之类的信息流”。如果可能的话,要将心跳检测与数据同步即数据获取所使用的网卡分离以提高可靠性。
Apache Spark源码走读之6 -- 存储子系统分析,布布扣,bubuko.com
原文地址:http://www.cnblogs.com/downtjs/p/3815293.html