标签:
有个问题:在执行计划里运算符的估计行数是42,但是你知道查询的正确行数不是42。你也听说了SQL Server使用统计信息来作此估计的?但我们怎么看懂统计信息,来理解这里的估计是怎么来的?
今天我想谈下SQL Server里的统计信息,在直方图(histogram)和密度向量(density vector)里,SQL Server内部是如何保存这些值的并用此来估计行数的。
首先我们来看下直方图。直方图的用途是用高效、压缩的方式存储列数据分布情况。每次当你在表上创建索引时(聚集/非聚集索引),SQL Server会为你自动创建统计信息。这个统计信息就包含了那列(索引键)的数据分布信息。比如你有一个订单表,里面有个Country列,这列里有很多国家名字。因此直方图就是对这些国家个数分布情况的可视化:
在直方图里,我们用很多柱条描述数据分布情况:柱条越高,那列的这个值就记录数就越多。SQL Server使用同样的概念和格式来描述数据分布情况。我们通过一个例子来详细了解下。在AdventureWorks2008R2数据库里,我们找到表SalesOrderDetail里的ProductID列。这ProductID列存储着具体的销售产品ID信息。可以看到,ProductID列也有索引定义,那就说有对应的统计信息来描述ProductID列的数据分布情况。
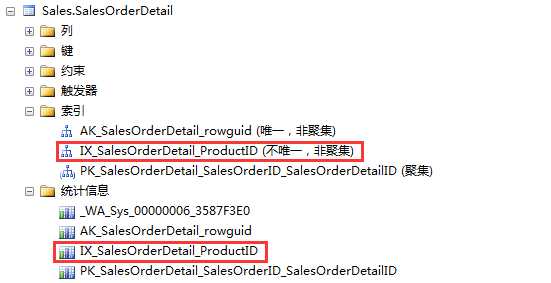
在SSMS里,你通过查看表属性来查看列和统计信息,也可以使用DBCC SHOW_STATISTICS命令在结果里输出统计信息。
1 -- Show the statistics for a given index 2 DBCC SHOW_STATISTICS (‘Sales.SalesOrderDetail‘, IX_SalesOrderDetail_ProductID) 3 GO
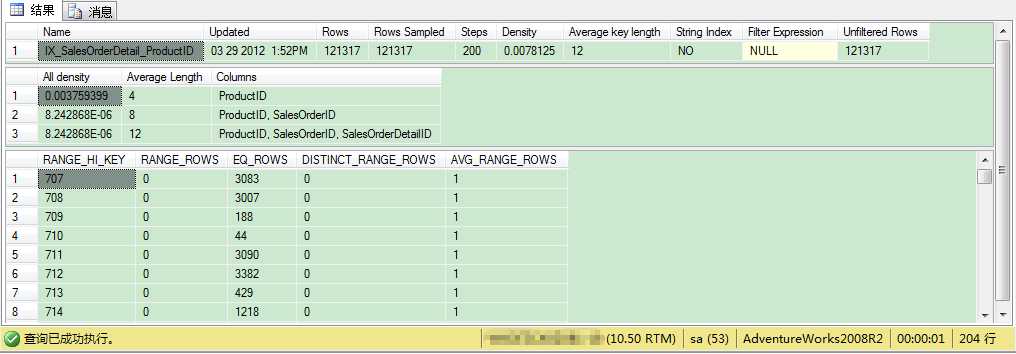
从上图可以看到,这个命令返回3个不同的记录集:
我们来关注下这3个部分信息,看看它们是如何被用来做参数预估(Cardinality Estimation) (估计行数的计算)。现在我们对SalesOrderDetail表执行一个简单的查询,点击工具栏的 显示包含实际的执行计划。如你所见,我们只要ProductID列值为707的记录:
显示包含实际的执行计划。如你所见,我们只要ProductID列值为707的记录:
1 -- SQL Server使用EQ_ROWS值来做预估,这个值在直方图里可以直接取到。 2 -- 对于筛选器运算符估计行数是3083. 3 SELECT * FROM Sales.SalesOrderDetail 4 WHERE ProductID = 707 5 GO
查询返回121317条记录中的3083条记录。因为我们没有定义覆盖非聚集索引(这里也用不到,因为用了SELECT *),这个查询已经越过临界点了,从执行计划里可以看到,SQL Server已经选择了非聚集索引扫描运算符。
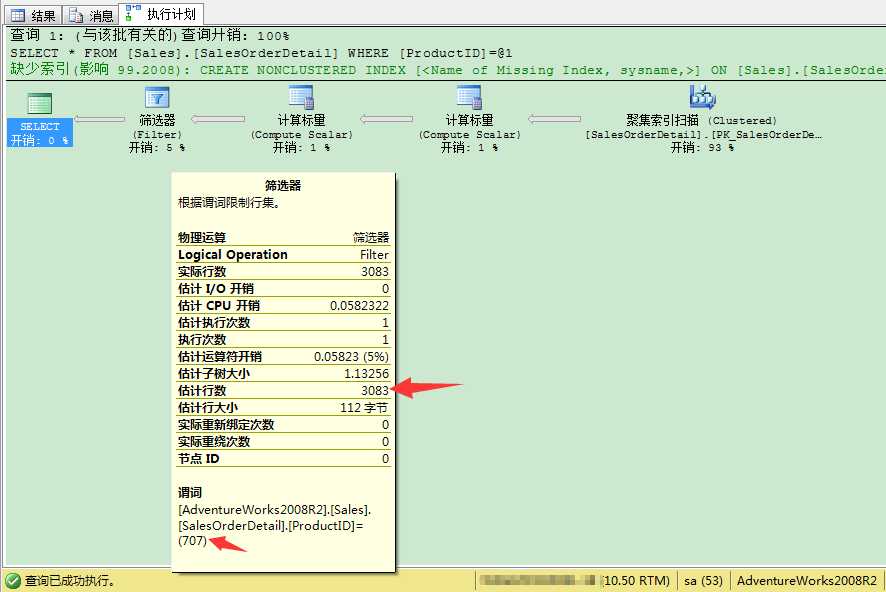
在执行计划里,筛选器运算符的属性信息(鼠标移到运算符上会显示属性信息)的谓词部分,这里显示了过滤记录条件是ProductID值是707,还有估计行数是3083。看来这里的统计信息非常准确。但问题是这个估计是从哪里来的呢?当你看直方图时,我们可以看到很多行(最大梯级(步长)数为 200),这里描述ProductID列数据分布情况。
直方图的每一行有以下列:
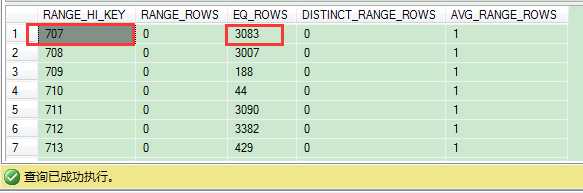
从RANGE_HI_KEY列可以看到,ProductID值为707的记录有3083。这与我们查询的限制条件完全匹配。在这个情况下,SQL Server使用EQ_ROWS列的值用作参数预估——这里是3083。这就是执行计划里筛选器运算符用到的估计方法。
我们再来看个查询:
1 -- 值为915记录数在直方图里不能直接取到,因此SQL Server使用AVG_RANGE_ROWS列值来做预估。 2 -- 在910到916之间有150条记录,不同值个数是4(DISTINCT_RANGE_ROWS)。 3 -- 因此对于非聚集查找,SQL Server估计150/4=37.5条记录。 4 SELECT * FROM Sales.SalesOrderDetail 5 WHERE ProductID = 915 6 GO
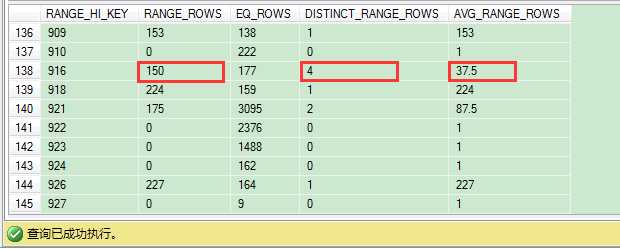
这里我们只返回ProductID列值为915的记录。但是在直方图里,我们找不到915的对应值。直方图里存储了910到916之间的值。这个范围内的记录数有150条(RANGE_ROWS),不包括910和916这2个值。在这个150条记录里,有4个不同值(DISTINCT_RANGE_ROWS)。这就是说915的记录数在910与916之间是37.5(AVG_RANGE_ROWS=150/4)。
因此在这个情况下,SQL Server对915值的估计行数是37.5,如你在执行计划所见。事实上,非聚集索引查找运算符返回41条记录,这个估计还是很准的。
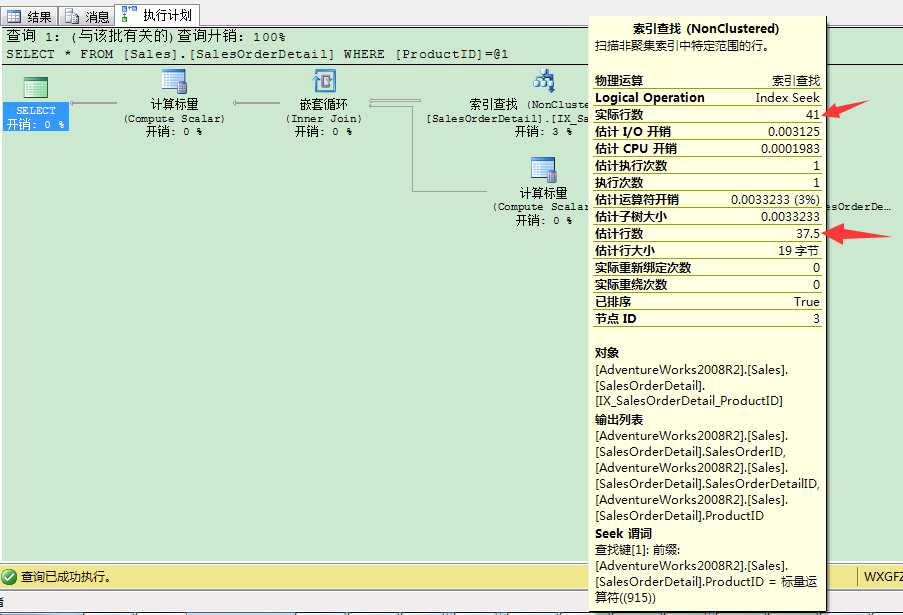
从这个例子里可以看出,在直方图里没有完全匹配值时,SQL Server也能进行基数预估。因此在直方图里会有RANGE_ROWS列和DISTINCT_RANGE_ROWS列。从上述解释可以看出,直方图并不难理解。直方图里很重要的一点是,SQL Server只为索引中第1个键列中的列值创建直方图。索引中的所有后续列,SQL Server在密度向量里存储。因此,在组合索引键里,第1列应该是选择性最高的那列(查询经常用到的)。
我们再来看看神秘的密度向量,看下非聚集索引IX_SalesOrderDetail_ProductID,这个索引只在ProductID列建立。但是每个非聚集索引,SQL Server在索引的页层也保存聚集键作为逻辑指针。当你定义了非唯一的非聚集索引,聚集键也是非聚集索引导航结构的一部分。表里的聚集键SalesOrderID是个组合列,包含SalesOrderID列和SalesOrderDetailID列。
这就是说我们的非唯一非聚集索引事实上包含ProductID,SalesOrderID和SalesOrderDetailID列。索引键是个组合键。同样SQL Server需要为其他列创建密度向量,因为只有第1列(ProductID)是直方图里有信息,这个在上一部分我们已经看过了。当你看用DBCC SHOW_STATISTICS命令的输出时,密度向量是第2个表信息。

SQL Server在这里存储选择率(selectivity),不同列组合的密度。例如,ProductID列的All density值是0.003759399,你可以用下列语句来验证下:
1 -- The "All Density" value for the column ProductID: 0,0037593984962406015 2 SELECT 1 / CAST(COUNT(DISTINCT ProductID) AS NUMERIC(18, 2)) FROM Sales.SalesOrderDetail 3 GO
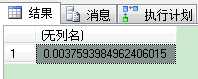
对于ProductID,SalesOrderID组合列和ProductID,SalesOrderID,SalesOrderDetailID组合列的All density值分别是8.242868E-06和8.242868E-06。你可以用1除以2个组合列的唯一值来验证下。这里我们的记录是121317,这些聚集值(SalesOrderID,SalesOrderDetailID组成了聚集键)都是唯一的,我们可以计算下:1/121317=8.242867858585359e-6。现在的问题是,SQL Server如何使用这些密度向量值作参数预估呢?
我们来看一个查询:
1 -- SQL Server uses the reciprocal in a GROUP BY to make an estimation how 2 -- much rows are returned: 3 -- Estimation for the Stream Aggregate: 266 4 SELECT ProductID FROM Sales.SalesOrderDetail 5 GROUP BY ProductID 6 GO
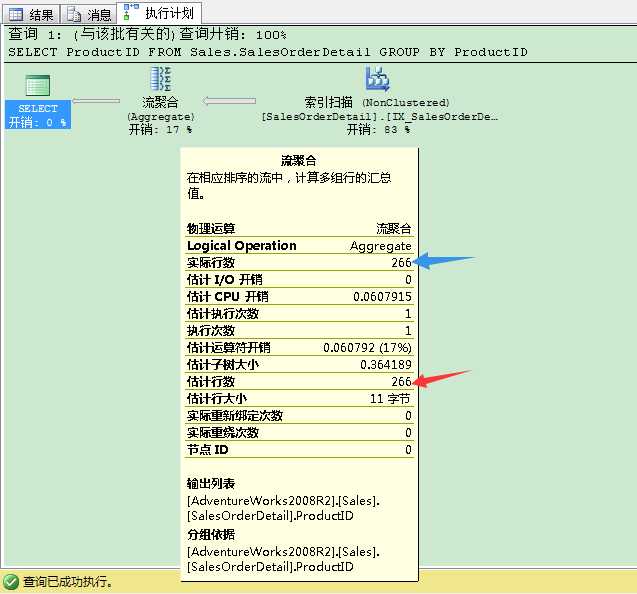
我们在ProductID列进行GROUP BY操作。在这个情况下,SQL Server使用ProductID列的密度向量值来估计流聚合运算符的估计行数:1/0.003759399=266。在执行计划里流聚合运算符的属性信息里可以看到估计行数是266。
在T-SQL语句里,当你使用本地变量时,SQL Server不能嗅探任何参数值,只能退回使用密度向量来进行参数预估。我们看下面的查询。
1 -- SQL Server also uses the Density Vector when we are working with local variables 2 -- and equality predicates. 3 -- SQL Server estimates for the Non-Clustered Index Seek 456 records: 121317 * 0,003759 = 456 4 -- Every variable value gives us the same estimation. 5 6 -- Estimated: 456 7 -- Actual: 3083 8 DECLARE @i INT = 707 9 10 SELECT * FROM Sales.SalesOrderDetail 11 WHERE ProductID = @i
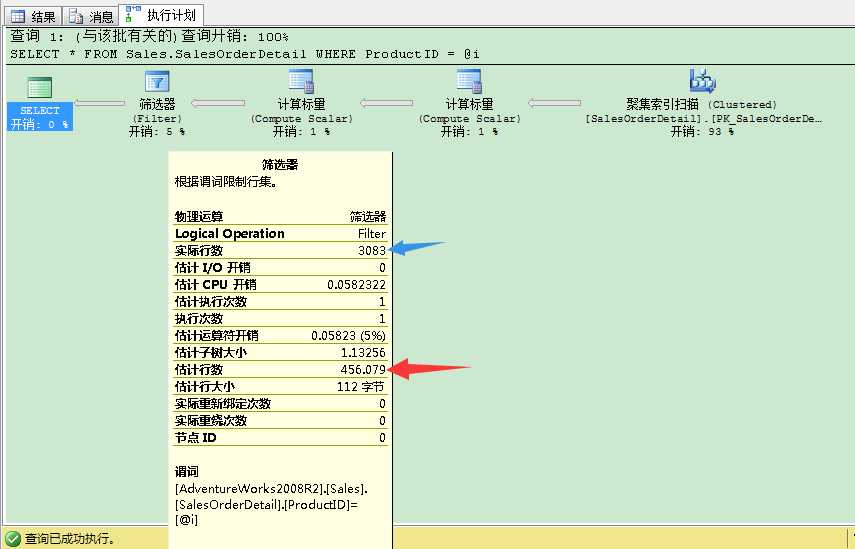
SQL Server对筛选器运算符的估计行数是456(121317 * 0.003759399),但实际上我们只返回了44条记录。
当你的本地变量与大于小于组合时,SQL Server不再使用密度向量值,只假设30%的行返回。
1 -- When we are using an inequality predicate (">", "<") SQL Server assumes 30% for the 2 -- estimated number of rows. 3 -- Estimated: 36.395 (121.317/36.395 = 3,33) 4 -- Actual: 44 5 DECLARE @i INT = 719 6 7 SELECT * FROM Sales.SalesOrderDetail 8 WHERE ProductID > @i 9 GO
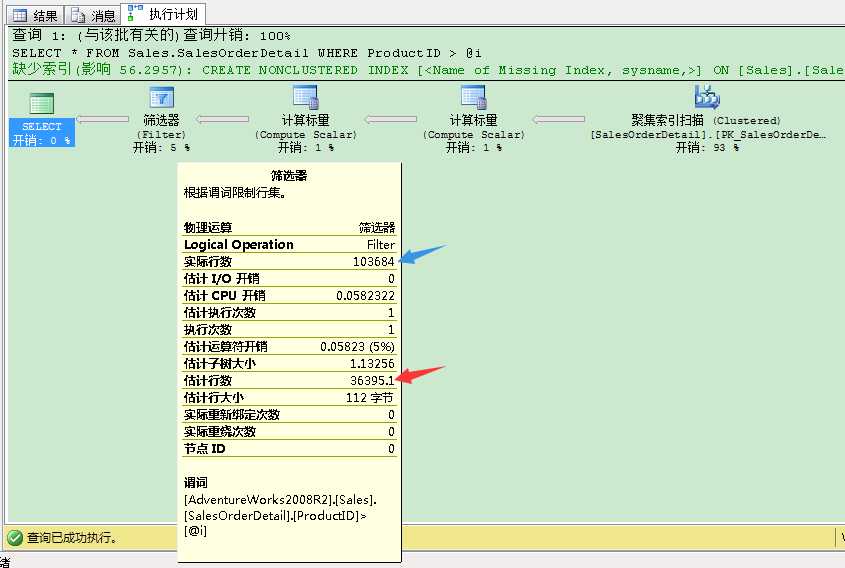
从执行计划里可以看到,SQL Server对此的估计行数是36395,因为这就是全表30%的记录数(12317 * 0.30)。
在这篇文章里你学到了SQL Server如何使用内在的统计信息,对我们的查询执行参数预估。统计信息包含2个部分:直方图,还有密度向量。在直方图里,SQL Server可以非常容易的估计出查询的平均返回行数。因为SQL Server只存储组合索引键第1列的直方图信息,另外对于其他列的信息在密度向量里存储。还有我们学习了这2个统计信息在参数预估时如何使用的。
标签:
原文地址:http://www.cnblogs.com/woodytu/p/4556065.html