标签:
Example: Polynomial Curve Fitting
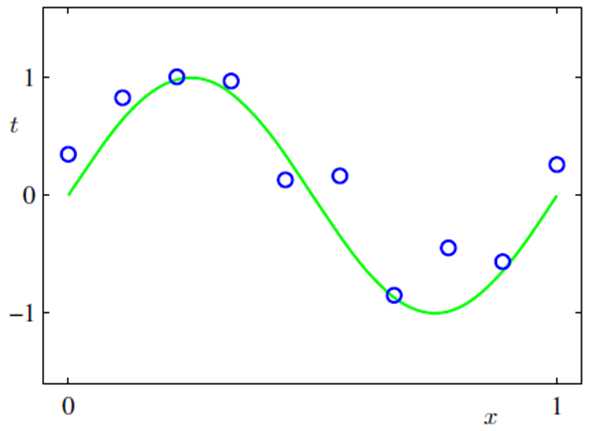
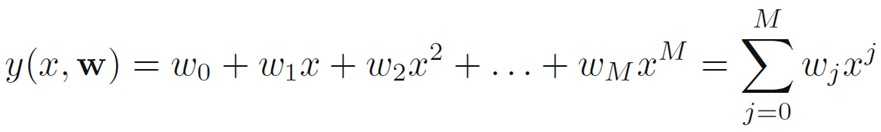
The goal of regression is to predict the value of one or more continuous target variables t given the value of a D-dimensional vector x of input variables.
什么是线性回归?线性回归的目标就是要根据特征空间是D维的输入x,预测一个或多个连续的目标值变量,大多数情况下我们研究的目标值是一维的。
We can obtain a much more useful class of functions by taking linear combinations of a fixed set of nonlinear functions of the input variables, known as basis functions. Such models are linear functions of the parameters, which gives them simple analytical properties, and yet can be nonlinear with respect to the input variables.
这个多项式拟合的例子并不是用一条直线进行回归,这个例子为什么是线性回归呢?这里说的线性是指预测函数y是关于参数w的线性函数。我们可以用一些非线性基函数(basis functions)将我们的输入变量进行非线性变换。
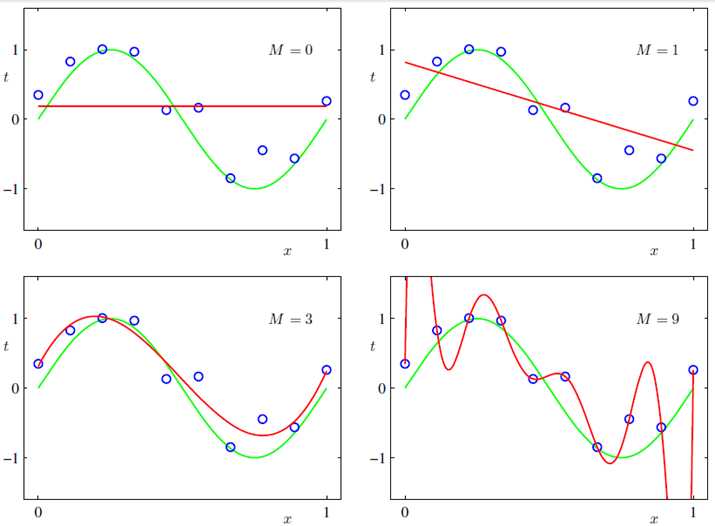
在这个例子中,绿色的曲线是产生数据真正的y=sin(2πx),蓝色的圈圈是在[0,1]区间上均匀采样,加入均值为0的高斯噪声产生的样本。
Talor Expansion
有人会想,为什么我们可以用多项式进行拟合?这时候我们可以借助泰勒展开定理。
若函数f(x)在点a的某一领域内具有(n+1)阶导数,则在该领域内f(x)的n阶泰勒公式为:
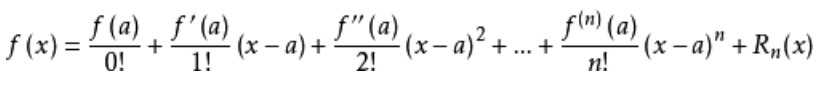
其中,当a=0时为泰勒公式的特例,麦克劳林展开
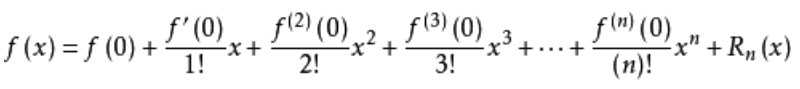
特别地,当f(x)=sin(x)和n=9时,我们有:
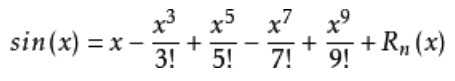
也就是说,sin(x)可以用在x=0处的麦克劳林展开,用M阶多项式进行近似,当M越大,拟合效果越好。
Common Basis Functions
更一般地形式
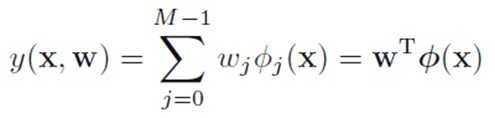
where ?j(x) is known as basis functions
Polynomial basis functions
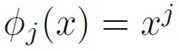
Gaussian basis functions
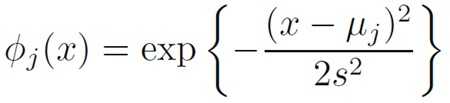
Sigmoid basis functions
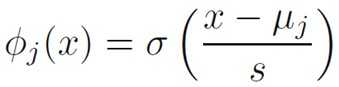
where
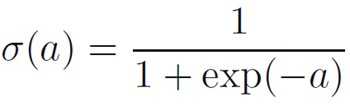
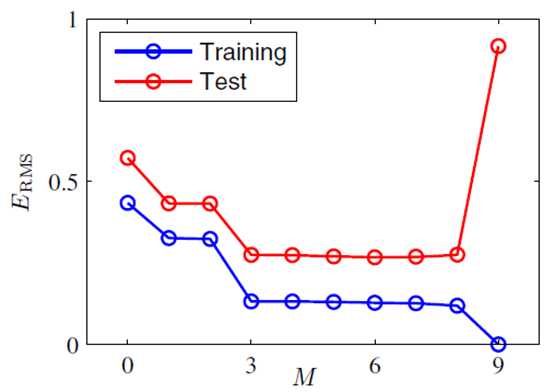
Objectives and Results
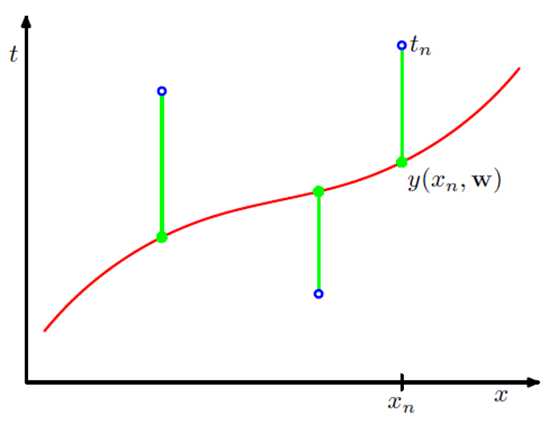
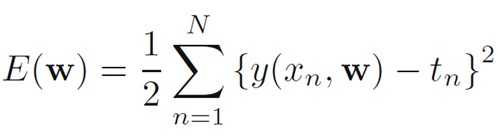
我们的目标是预测值(绿色的点)与训练样本的值(蓝色的点)之间的误差尽量小,采用的损失函数是平方损失函数。
Maximum likelihood and least squares
假设我们的目标变量t是由目标函数y(x,w)加上高斯噪声产生的
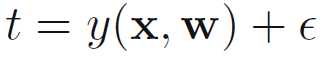
其中,?是均值为0,方差为β?1的高斯随机变量,也就是
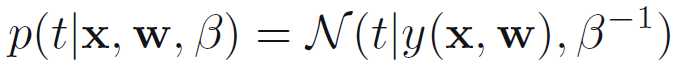
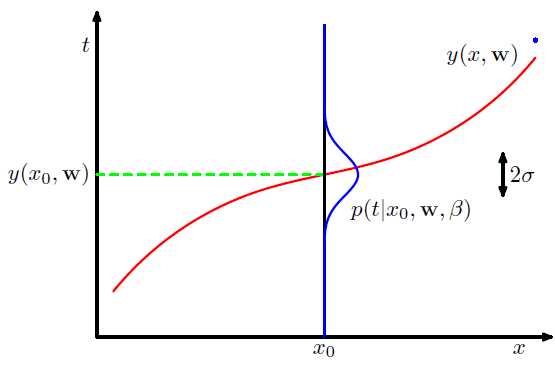
在给定一个输入x的情况下,目标变量t的条件期望
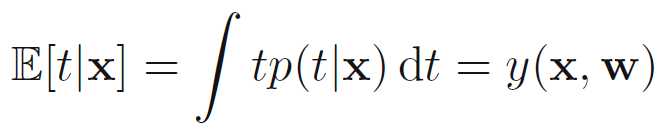
根据训练样本X以及对应的t,我们可以得到关于参数w和β似然函数
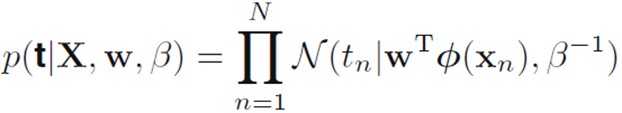
两边取log
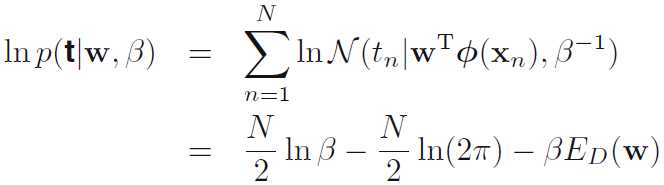
其中
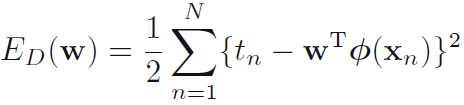
极大化似然函数等价于极小化损失函数。在噪声服从均值为0的高斯分布情况下,MLE与Least Square等价
Calculate Parameter
通过梯度下降进行求解
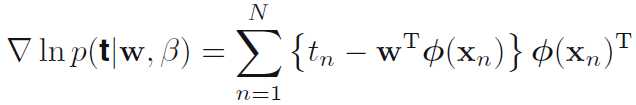
设置梯度为0
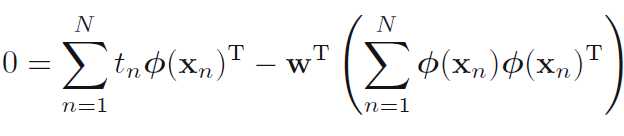
最后化简,我们可以得到
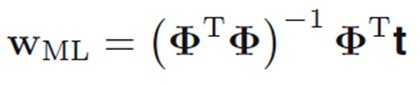
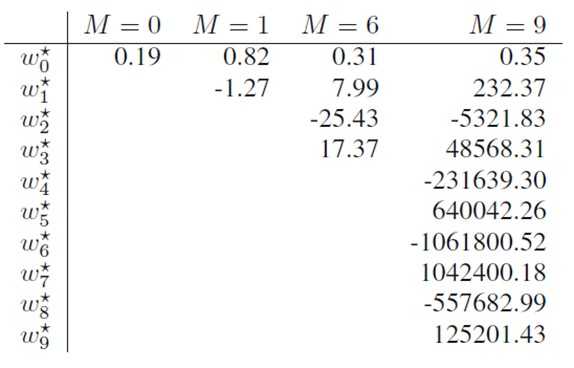
特别地,当两个或两个以上的列向量相关性明显的话,?T?容易接近奇异矩阵,求解的w会有很大的波动
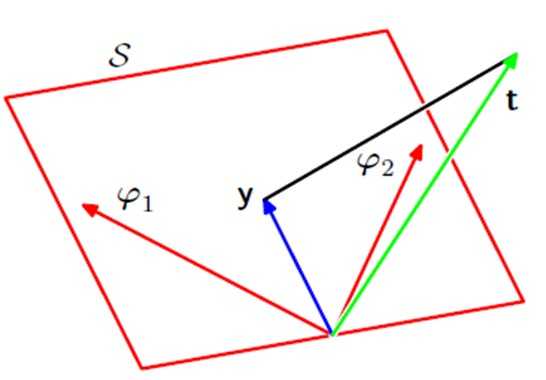
Geometry of least square
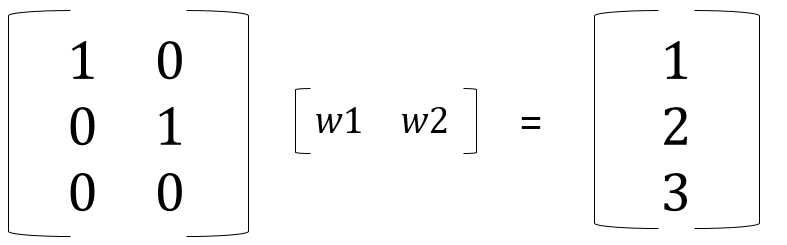
这里假设我们的样本大小N=3,特征M=2,t? =(1,2,3)
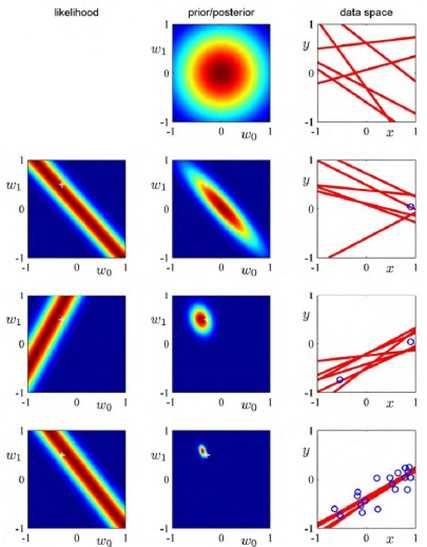
每个样本的特征空间是2维,其中第一列(1,0,0)我们可以看成是一个特征维度(比如x轴),三维空间中的一个点或者向量,对应下图的φ1,第二列(0,1,0)也是一个特征维度(比如y轴),对应下图的φ2,这两个维度向量构成的向量空间(对这两个向量进行线性组合,系数为w1和w2)就是在三维空间中的一个平面。但是我们的数据样本的t? =(1,2,3)(下图中绿色的向量),显然不在这个平面中,这样进行回归或者拟合就会产生误差(下图中黑色的线段),我们的任务是将这种误差最小化,也就是找一条最短的黑色线段,解决的办法就是将t? 向二维平面(数据的特征空间)进行投影,得到一个y? ,这个y? 就是对两个列向量进行线性组合的结果,系数为w1和w2,也就是我们要求解的参数。我们可以再进一步想想,为什么会有误差呢,如果我们再引进一个特征(再加入一个列向量φ3=(0,0,1),比如z轴),这时候,我们的特征空间就可以表示任何三维空间中的数据了,在这个例子中就不会有误差了。但是实际上,对一个问题进行回归分析,考虑的维度可能是成千上万维甚至无穷维,所以基本上都会有误差。
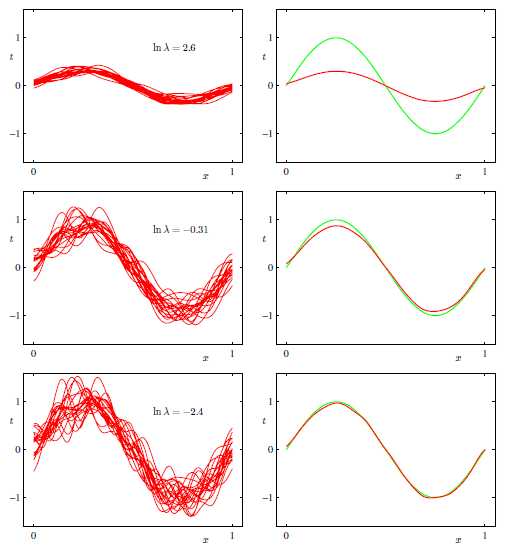
Regularized Least Squares
Over-fitting的问题可以通过在损失函数中加入正则项(参数的惩罚)
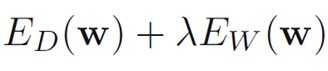
其中λ是正则项的系数,损失函数就变为
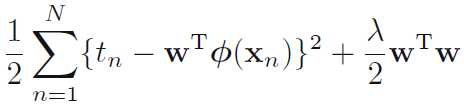
参数w的解变为
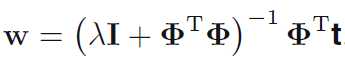
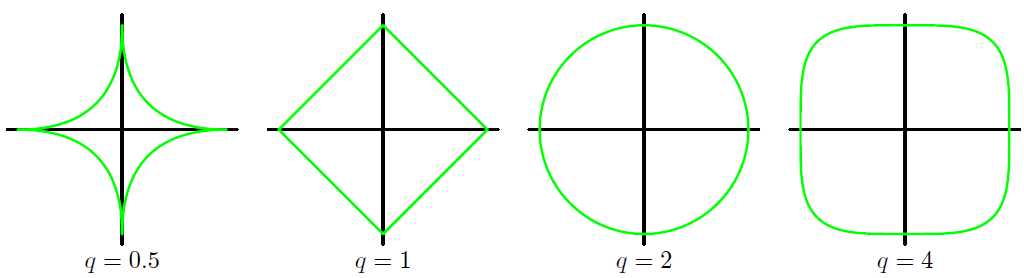
更一般的形式
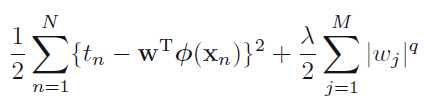
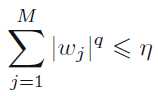
这个问题可以转换为带约束的凸优化问题,我们可以基于约束条件,构造拉格朗日函数。
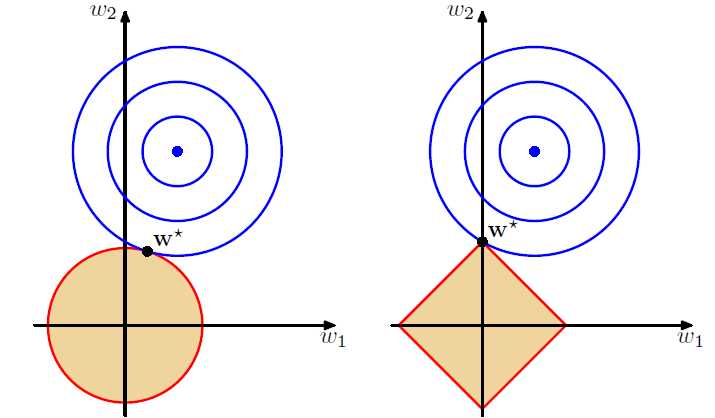
上图左边为Ridge,右边为Lasso,这就是为什么Lasso能够参数稀疏解,进行特征选择。
---
#The Bias-Variance Decomposition
期望的损失函数
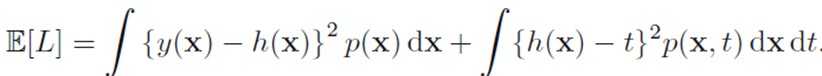
其中h(x)是我们的目标函数
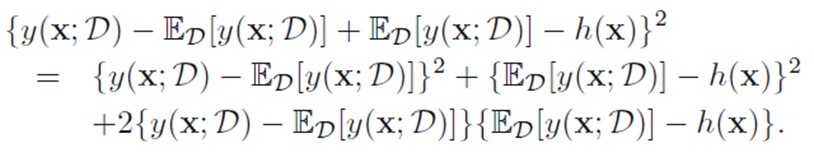
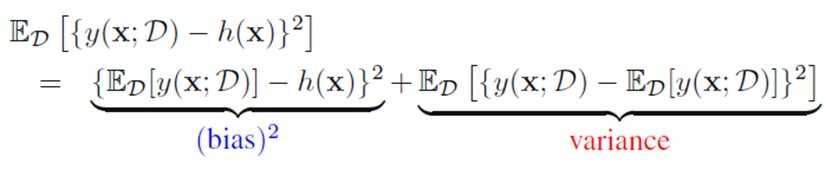
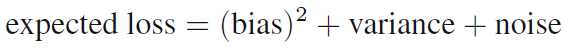
Bias和Variance是一个trade-off的问题
Bayesian Linear Regression
参数w的先验概率分布
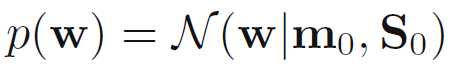
参数w的后验概率分布
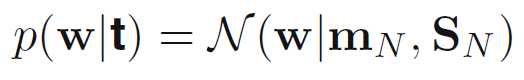
其中
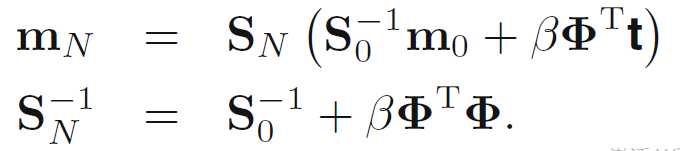
特别地,我们取
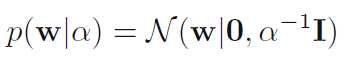
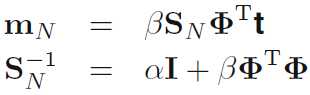
对参数w的后验概率分布取log
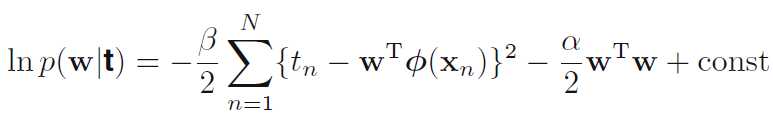
λ=αβ
MAP与Regularized Least Square等价
Predictive distribution
Bayesian关注的不是参数的获取,而是预测
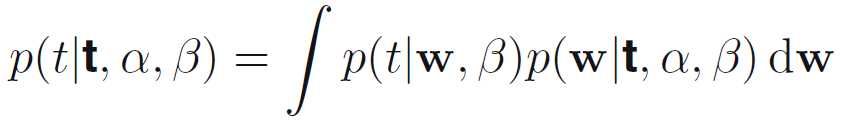
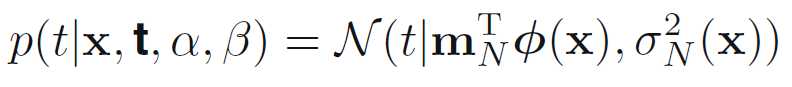
Equivalent Kernel
预测值可以写成
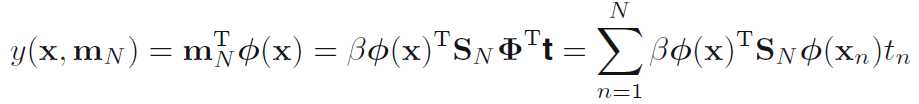
写成等价核的形式
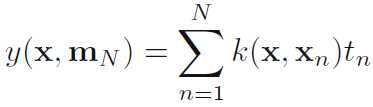
其中
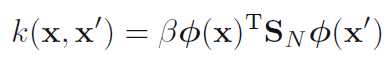
可以看出是训练样本的目标值的加权求和。我们可以不使用基函数(隐式定义了核),直接定义等价核,从而引出了高斯过程。
Bayesian Model Comparison
Bayesian可以帮助我们做模型选择
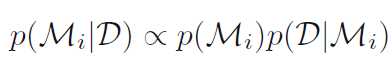
其中Model Evidence是
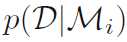
我们需要选择那个Model Evidence最大的模型
Bayes factor
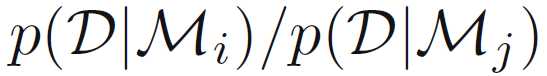
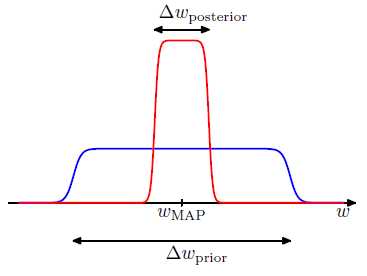
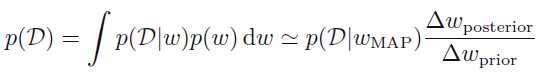
取log
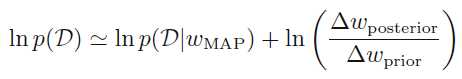
多个参数w的情况下
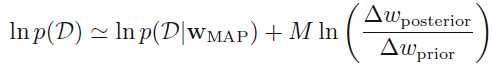
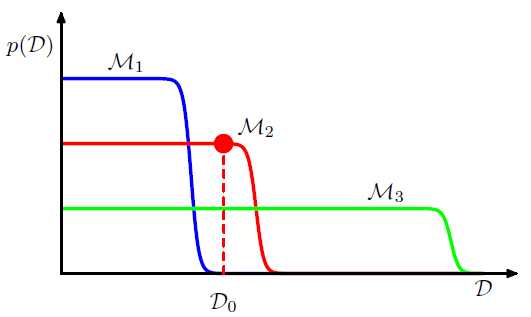
从这个图中,我们可以看出,简单模型可以产生的数据D比较单一,而复杂模型可以产生比较复杂多样数据,但是分配到这些数据D的概率比较低,也就是复杂模型的Model Evidence较低,适中的模型复杂度有较高的Model Evidence,而简单模型虽然有较高的Model Evidence,但是其拟合能力差。
Bayesian Framework Summary
- 可以避免过拟合
- 需要对模型进行假设,也就是选择合适的先验,不合理的先验会导致一些问题(例如高斯先验的方差如果取无限大的话,无法对参数w进行积分)
PRML-Chapter3 Linear Models for Regression
标签:
原文地址:http://www.cnblogs.com/aling/p/4557419.html