减少存储空间,加快传输速率
在hadoop中,压缩应用于文件存储、Map端到Reduce端的数据交换等情景。
hadoop,主要考虑压缩速率和压缩文件的可分割性
压缩算法:时间和空间的权衡
更快的压缩和解压缩效率通常压缩比较低。
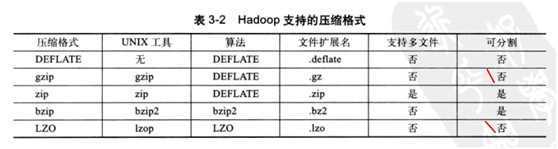
hadoop提供了对压缩算法的编码和解码器类
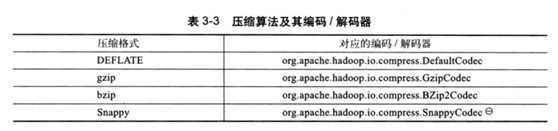
编码和解码示例(采用gzip)
package test;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.io.OutputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.CompressionOutputStream;
import org.apache.hadoop.util.ReflectionUtils;
public class CompressDemo {
public static void main(String[] args) throws Exception {
//compress("org.apache.hadoop.io.compress.GzipCodec");
//GzipCodec
decompress("readme.gz");
}
public static void compress(String className) throws Exception{
File filein = new File("readme.txt");
//输入流
InputStream in = new FileInputStream(filein);
Class codecClass = Class.forName(className);
Configuration conf = new Configuration();
//编码器实例
CompressionCodec codec = (CompressionCodec) ReflectionUtils.newInstance(codecClass, conf);
//输出流,若存在,先删除
File fileout = new File("readme"+codec.getDefaultExtension());
fileout.delete();
OutputStream out = new FileOutputStream(fileout);
//编码器包装输出流,成为编码输出流
CompressionOutputStream codecOut = codec.createOutputStream(out);
//编码输出
IOUtils.copyBytes(in, codecOut, 1024, true);
}
public static void decompress(String fileName) throws Exception{
Configuration conf = new Configuration();
CompressionCodecFactory fact = new CompressionCodecFactory(conf);
//得到一个编解码器
CompressionCodec codec = fact.getCodec(new Path(fileName));
if(codec == null){
System.out.println("Cannot find the codec for file "+fileName);
return;
}
//输入流
InputStream in = codec.createInputStream(new FileInputStream(new File(fileName)));
//输出到控制台
IOUtils.copyBytes(in, System.out, conf);
}
}
getCompressor()可以得到对应编码器的压缩器。
在各个压缩流中都有实现,但是不建议手工去实现,一是复杂二是效率。
总结:hadoop使用CompressionCodec编码和解码器,里面使用的流是压缩和解压缩流CompressionOutputStream和CompressionInputStream,而在流中采用了压缩和解压缩器Compressor、Decompressor
通过上面的那个示例,可以使用即可。
数据压缩往往是极速密集型的操作,考虑到性能,建议使用本地库(Native Library)来压缩和解压。(在某个测试中,与java内置的gzip压缩相比,使用本地gzip压缩库可将解压时间减少50%,压缩时间减少10%)。

这个可以在真正使用到的时候再研究,因为设置C语言等其它语言。
数据压缩库,被google用于许多内部项目,如BigTable,Mapreduce,等该算法库针对性能做了调整,经过了PB级数据压缩的考验,所以有必要提一提。
org.apache.hadoop.io.compress.snappy包
SnappyCodec类

方法:
setInput为压缩器提供数据
needsInput是否需要加载新的输入数据
compress 压缩数据
finished 压缩是否结束
在需要的时候可以研究一下。
Hadoop技术内幕HDFS-笔记4之压缩,布布扣,bubuko.com
原文地址:http://www.cnblogs.com/jsunday/p/3817440.html