标签:
数据库有3种基本的存储引擎:
LSM-Tree 的设计思想非常朴素:将对数据的修改增量保持在内存中,达到指定的大小限制后将这些修改操作批量写入磁盘,不过读取的时候稍微麻烦,需要合并磁盘中历史数据和内存中最近修改操作,所以写入性能大大提升,读取时可能需要先看是否命中内存,否则需要访问较多的磁盘文件。因此,LSM-Tree比较适合的应用场景是:insert数据量大,读数据量和update数据量不高且读一般针对最新数据。
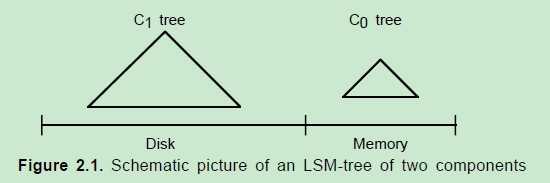
LSM树原理把一棵大树拆分成N棵小树,它首先写入内存中,随着小树越来越大,内存中的小树会flush到磁盘中,磁盘中的树定期可以做merge操作,合并成一棵大树,以优化读性能。
数据首先会插入到内存中的树。当内存中的树中的数据超过一定阈值时,会进行合并操作。合并操作会从左至右遍历内存中的树的叶子节点与磁盘中的树的叶子节点进行合并,当被合并的数据量达到磁盘的存储页的大小时,会将合并后的数据持久化到磁盘,同时更新父亲节点对叶子节点的指针。
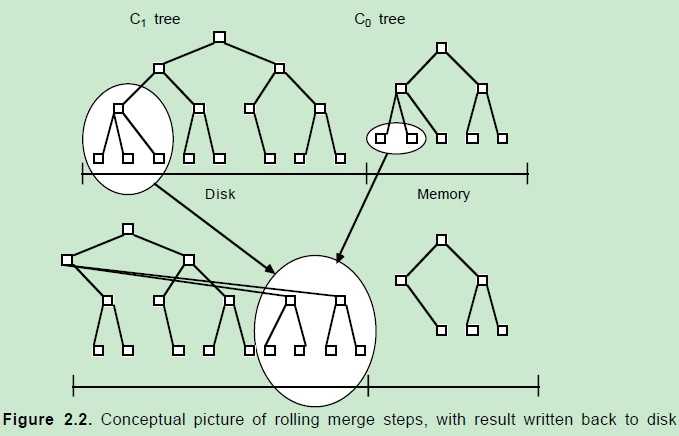
之前存在于磁盘的叶子节点被合并后,旧的数据并不会被删除,这些数据会拷贝一份和内存中的数据一起顺序写到磁盘。这会操作一些空间的浪费,但是,LSM-tree提供了一些机制来回收这些空间。
磁盘中的树的非叶子节点数据也被缓存在内存中。
数据查找会首先查找内存中树,如果没有查到结果,会转而查找磁盘中的树。
有一个很显然的问题是,如果数据量过于庞大,磁盘中的树相应地也会很大,导致的后果是合并的速度会变慢。一个解决方法是建立各个层次的树,低层次的树都比上一层次的树数据集大。假设内存中的树为c0, 磁盘中的树按照层次一次为c1, c2, c3, ... ck-1, ck。合并的顺序是(c0, c1), (c1, c2)...(ck-1, ck)。
为什么LSM-tree的插入很快:
参考文档:
http://www.2cto.com/database/201411/350877.html
标签:
原文地址:http://www.cnblogs.com/chenny7/p/4568829.html